YOLOV3从数据集到预测
实现代码使用Bubbliiiing博主的git代码,宝藏博主,希望自己能全部实现一遍博主实现过的代码睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的博客-CSDN博客_睿智的目标检测26
第一步先将代码跑起来,跑起来后很多看着抽象的变量都能看的更具体,不用想象,从以下几个方面介绍
1、数据集处理
2、模型生成
3、计算loss
4、训练
5、预测
一、数据集处理
上一篇介绍过VOC数据集文件夹中各个文件夹的作用,这里主要使用VOC中Annotations、ImageSets-Main、JPEGImages文件夹,博主的voc_annotation.py是为了将各个文件夹的标注及图片整合,生成一个2007_train.txt.
voc_annotation.py主要做了以下几个工作
a、读取Annotation文件夹中的xml文件,计算共有m个,使用os.listdir列出文件夹内的xml文件列表(os.listdir读出来是乱序的,想要顺序排列需加入files=os.listdir(".")files.sort())
b、根据训练和验证的比例,将xml列表内的文件名写入trainval.txt以及test.txt,train.txt,val.txt
c、根据b的训练txt中的名称列表读取xml文件
d、新建txt,写入当前读取到的图片路径以及图片名称对应的xml文件中的bndbox及类别
二、模型生成
模型backbone使用Darknet53
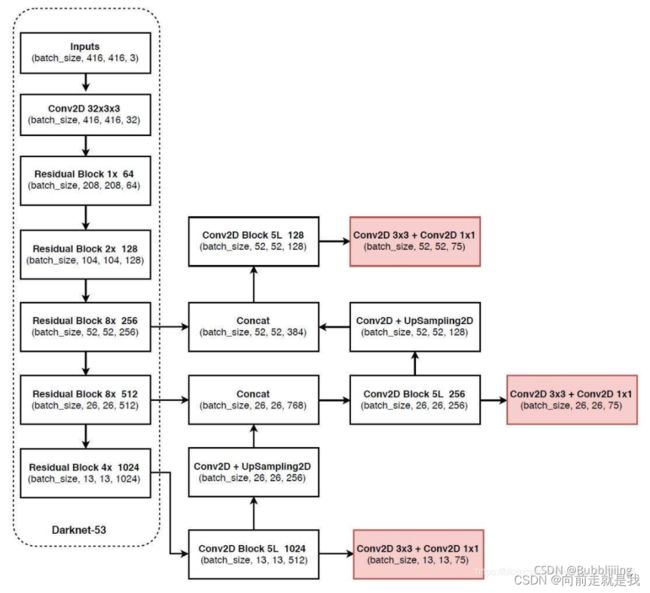
每一个ResidualBlock是构成网络的一个Layer。
每个Layer由一个卷积核大小为3X3、步长为2的卷积,加若干个Basic Block组成。
Basic Block由一个1X1的卷积和一次3X3的卷积,以及把这个结果加上上面的layer,组成
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return outLayer层中的卷积核大小为3X3、步长为2的卷积会压缩输入进来的特征层的宽和高
Basic Block不断的将1X1卷积和3X3卷积以及残差边叠加,大幅度的加深了网络。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。(拷贝自Bubbliiiing)
backbone出来的结果处理可以分为两个部分,分别是:
- 构建FPN特征金字塔进行加强特征提取。
- 利用Yolo Head对三个有效特征层进行预测。
构建FPN特征金字塔进行加强特征提取:
主干网络共输出三个结果(两个中间结果(52*52*256,26*26*512),一个最终结果(13*13*1024))对这三个结果构建FPN。首先对最终结果(13*13*1024)进行5次卷积,结果用作yoloHead预测及上采样后与上一个中间结果(26*26*512)进行concat
对concat后的26*26*768(26*26*512concat26*26*256)进行5次卷积,结果用作yoloHead预测及 上采样后与上一个中间结果(52*52*256)进行concat
对concat后的52*52*384进行5次卷积,结果用作yoloHead预测
yoloHead搭建:
yoloHead是一次3x3卷积加上一次1x1卷积,3x3卷积的作用是特征整合,1x1卷积的作用是调整通道数。对yoloHead收到的三个特征层(13,13,512)、(26,26,256)、(52,52,128)进行整合,输出(13,13,75),(26,26,75),(52,52,75)
至此,模型部分搭建完成
三、计算loss
yolo计算loss需要先将预测结果中与真值IOU最大的那几个框挑出,再由这几个框与真值间做loss
挑出(decode):
未完待续