【深度学习】:详解目标检测YOLO V2(YOLO9000: Better, Faster, Stronger)算法
论文链接:
https://arxiv.org/pdf/1612.08242.pdf
YOLO的升级版有两种:YOLOv2和YOLO9000。作者采用了一系列的方法优化了YOLO的模型结构,产生了YOLOv2,在快速的同时准确率达到目前最好的结果(state of the art)。然后,作者提出了一种目标分类与检测的联合训练方法,通过WordTree来混合检测数据集与识别数据集之中的数据,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种物体的实时检测。
先解释概念:Yolov2和Yolo9000算法内核相同,区别是训练方式不同:Yolov2用coco数据集训练后,可以识别80个种类。而Yolo9000可以使用coco数据集 + ImageNet数据集联合训练,可以识别9000多个种类。
YOLO V2是原作者在V1基础上做出改进后提出的,论文的名称就已经表达了作者的工作内容:
- Better 指的是和YOLO相比,YOLO V2有更好的精度
- Faster 指的是修改了网络结构,其检测更快
- Stronger 指的就是YOLO 9000,使用联合训练的方法,同时使用目标检测和图像分类的数据集,训练YOLO V2,训练出来的模型能够实时的识别多达9000种目标,所以也称为YOLO9000。
遵循原论文的结构,本文将从Better,Faster和Stronger三个方面对YOLO V2进行解读。
一. Better
在YOLO V1的基础上,作者提出了不少的改进来进一步提升算法的性能(mAP),主要改进措施包括网络结构的改进(第1,3,5,6条)和Anchor Box的引进(第3,4,5条)以及训练方法(第2,7条)。
1.1 引入BN层(Batch Normalization)
Batch Normalization能够加快模型收敛,并提供一定的正则化。作者在每个conv层都加上了了BN层,同时去掉了原来模型中的drop out部分,实验证明可以提高2%的mAP。
BN层进行如下变换:①对该批样本的各特征量(对于中间层来说,就是每一个神经元)分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。从而使得每一批训练样本在每一层都有类似的分布。这一变换不需要引入额外的参数。②对上一步的输出再做一次线性变换,假设上一步的输出为Z,则Z1=γZ + β。这里γ、β是可以训练的参数。增加这一变换是因为上一步骤中强制改变了特征数据的分布,可能影响了原有数据的信息表达能力。增加的线性变换使其有机会恢复其原本的信息。
关于批规一化的更多信息可以参考 Batch Normalization原理与实战。
1.2 高分辨率分类器(High Resolution Classifier)
这里要先清楚相比图像的分类任务,目标检测需要更高的图像分辨率。另外,训练网络时一般都不会从随机初始化所有的参数来开始的,一般都是用预训练好的网络来fine-tuning自己的网络,预训练的网络一般是在ImageNet上训练好的分类网络。
- YOLOV1预训练的时候使用224x224的输入,检测的时候采用的是448x448的输入,这会导致分类切换到检测的时候,模型需要适应图像分辨率的改变。
- YOLOV2中将预训练分成两步:①:先用224x224的输入来训练大概160个epoch,然后再把输入调整到448x448再训练10个epoch,然后再与训练好的模型上进行fine-tuning,检测的时候用448x448就可以顺利过渡了。
这个方法提高了3.7%的mAP.
1.3 引入先验框(Anchor Box)
在YOLO中在最后网络的全连接层直接预测目标边框的坐标,在YOLO V2中借鉴 Fast R-CNN中的Anchor的思想。
- 去掉了YOLO网络的全连接层和最后的池化层,使提取特征的网络能够得到更高分辨率的特征。
- 使用416×416代替448×448作为网络的输入。这是因为希望得到的特征图的尺寸为奇数。奇数大小的宽和高会使得每个特征图在划分cell的时候就只有一个center cell(比如可以划分成7x7或9x9个cell,center cell只有一个,如果划分成8x8或10x10的,center cell就有4个)。为什么希望只有一个center cell呢?因为大的object一般会占据图像的中心,所以希望用一个center cell去预测,而不是4个center cell去预测。网络最终将416x416的输入变成13x13大小的feature map输出,也就是缩小比例为32。(5个池化层,每个池化层将输入的尺寸缩小1/2)。
- Anchor Boxes 在YOLO中,每个grid cell只预测两个bbox,最终只能预测98个bbox(7×7×2=98),而在Faster RCNN在输入大小为1000×600时的boxes数量大概是6000,在SSD300中boxes数量是8732。显然增加box数量是为了提高object的定位准确率。 过少的bbox显然影响了YOLO的定位的精度,在YOLO V2中引入了Anchor Boxes的思想,其预测的bbox则会超过千个(以输出的feature map为13×13为例,每个grid cell有9个anchor box的话,其预测的bbox数量为13×13×9=1521个)。
引入anchor box之后,相对YOLO1的81%的召回率,YOLO2的召回率大幅提升到88%。同时mAP有0.2%的轻微下降。
1.4 引入聚类提取先验框尺度(Dimension Cluster)
在引入anchor box后,一个问题就是如何确定anchor的位置和大小?Faster RCNN中是手工选定的,每隔stride设定一个anchor,并根据不同的面积比例和长宽比例产生9个(3种大小,3种形状共9种)anchor box。设想能否一开始就选择了更好的、更有代表性的先验Boxes维度,那么网络就应该更容易学到准确的预测位置。作者的解决办法就是统计学习中的K-means聚类方法,通过对数据集中的Ground True Box做聚类,找到Ground True Box的统计规律。以聚类个数k为Anchor Boxs个数,以k个聚类中心Box的宽高维度为Anchor Box的维度。
如果按照标准K-means使用欧式距离函数,大Boxes比小Boxes产生更多Error。但是,我们真正想要的是产生好的IOU得分的Boxes(与Box的大小无关)。因此采用了如下距离度量:
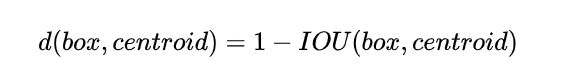
图1是在VOC和COCO上的聚类结果:
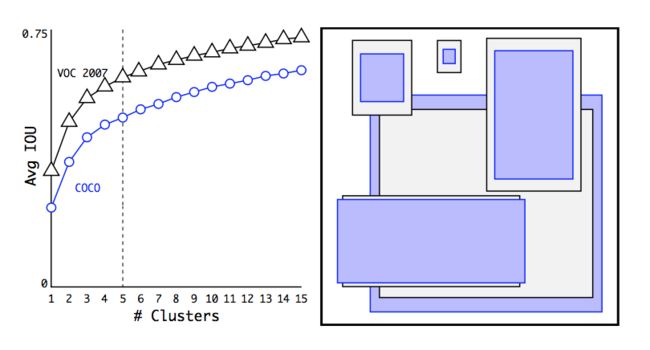
实验结论:
- 采用聚类分析得到的先验框比手动设置的平均的IOU值更高,模型更容易训练和学习。
- 随着K的增加,平均的IOU是增加的。但是为了综合考虑模型的复杂度和召回率。最终选择K=5。使用5个聚类框就已经达到61 Avg IOU,相当于9个手工设置的先验框60.9 Avg IOU。
作者还发现:The cluster centroids are significantly different than hand-picked anchor boxes. There are fewer short, wide boxes and more tall, thin boxes.这个是个无关紧要的结论了。
1.5 直接位置预测(Direct Location Prediction)
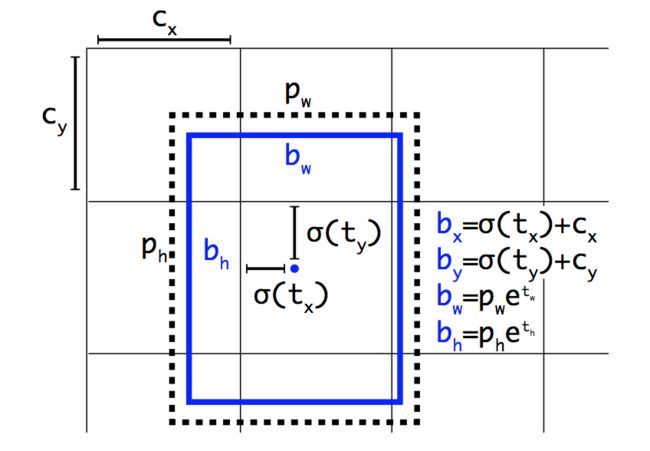
在引入anchor box后,另一个问题就是模型不稳定,特别是在训练前期,作者认为这种不稳定是因为边界框(bounding box)中心位置的预测不够成功。
基于候选框的网络一般是通过预测相对于anchor box中心的偏移值来预测边界框的的中心坐标。公式如下:


1.6 细粒度特征(Fine-Gained Features)
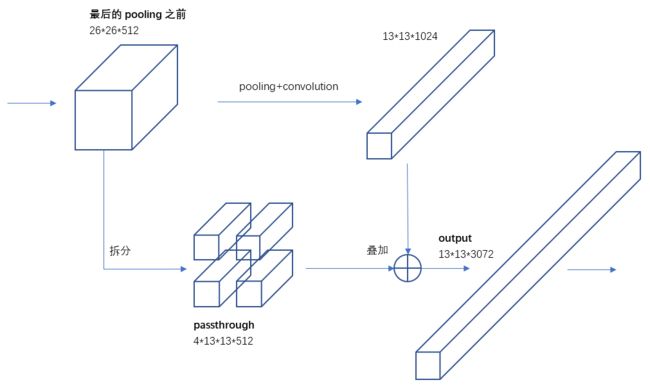
YOLO V2最后一层卷积层输出的是13x13的特征图,检测时也是遵循的这个分辨率。这个分辨率对于大尺寸目标的检测是足够了,但是对于小目标则需要更细粒度的特征,因为越小的物体在经过层层池化后,体现在最终特征图中的可能性越小。
Faser R-CNN和SSD都在不同层次的特征图上产生区域建议以获得多尺度的适应性,YOLO V2则开创性地引入了直通层(passthrough layer),这个直通层有点类似ResNet的dentity mappings结构,将浅层和深层两种不同尺寸的特征连接起来。在这里是将前一层高分辨率的特征图连接到低分辨率的特征图上:前一层的特征图的维度为26x26x512,在最后一个pooling之前将其1拆4形成4个13x13x512大小的特征图,然后将其与最后一层特征图(13x13x1024)连接成13x13x(1024+2048)的特征图,最后在此特征图上进行卷积预测(详细过程见下图3)。相当于做了一次特征融合,有利于检测小目标。
1.7 多尺度训练(Multi-Scale Training)
在实际应用时,输入的图像大小有可能是变化的。我们也将这一点考虑进来。因为我们的网络是全卷积神经网络,只有conv和pooling层,没有全连接层,这样就可以处理任意尺寸的图像。为了应对不同尺寸的图像,YOLO V2中在训练的时候使用不同的尺寸图像。
具体来说,在训练的时候,每隔一定的epoch(例如10)后就会微调网络,随机改变网络的输入图像大小。YOLO V2共进行5次最大池化,即最终的降采样参数为32,所以随机生成的图像大小为32的倍数,即{320,352,…,608},最终最小的尺寸为320×320,最大的尺寸为608×608。
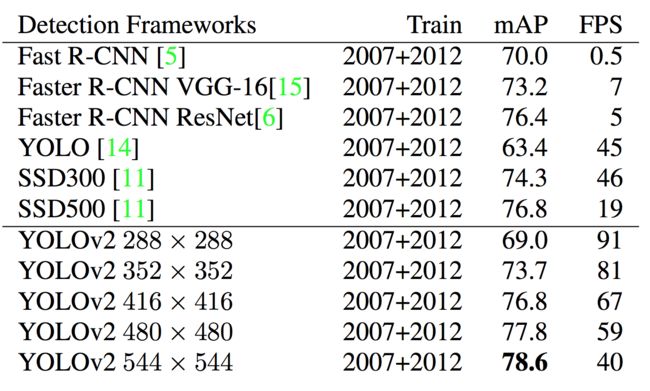
该训练规则强迫模型取适应不同的输入分辨率。模型对于小尺寸的输入处理速度更快,因此YOLOv2可以按照需求调节速度和准确率。在低分辨率情况下(288×288),YOLOv2可以在保持和Fast R-CNN持平的准确率的情况下,处理速度可以达到90FPS。在高分辨率情况下,YOLOv2在VOC2007数据集上准确率可以达到state of the art(78.6mAP)
对于目前流行的检测方法(Faster RCNN,SSD,YOLO)的精度和帧率之间的关系,见下图4。可以看到,作者在30fps处画了一条竖线,这是算法能否达到实时处理的分水岭。Faster RCNN败下阵来,而YOLO V2的不同点代表了不同输入图像分辨率下算法的表现。对于详细数据,见表格1对比(VOC 2007上进行测试)。

小结
YOLO V2针对YOLO定位不准确以及召回率低的问题,进行一些改变。 主要是借鉴Faster R-CNN的思想,引入了Anchor box。并且使用k-means的方法,通过聚类得到每个Anchor应该生成的Anchor box的的大小和形状。为了是提取到的特征有更细的粒度,其网络中借鉴ResNet的思想,将浅层的高分辨率特征和深层的特征进行了融合,这样能够更好的检测小的目标。 最后,由于YOLO V2的网络是全卷积网络,能够处理任意尺寸的图像,在训练的时候使用不同尺度的图像,以应对图像尺寸的变换。
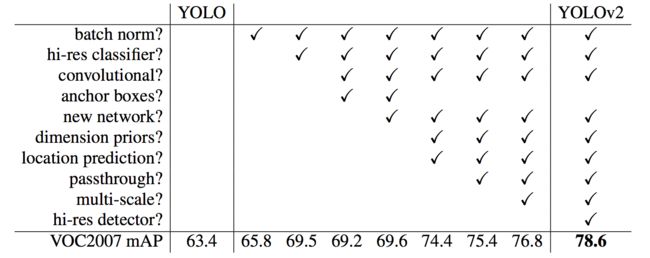
在Better这部分的末尾,作者给出了一个表格,指出了主要提升性能的措施。
二. Faster
为了精度与速度并重,作者在速度上也作了一些改进措施。大多数检测网络依赖于VGG-16作为特征提取网络,VGG-16是一个强大而准确的分类网络,但是确过于复杂。224*224的图片进行一次前向传播,其卷积层就需要多达306.9亿次浮点数运算。
YOLO使用的是基于Googlenet的自定制网络,比VGG-16更快,一次前向传播仅需85.2亿次运算,不过它的精度要略低于VGG-16。224*224图片取Single-Crop, Top-5 Accuracy,YOLO的定制网络得到88%(VGG-16得到90%)。
2.1 Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的工作经验。类似于VGG,网络使用了较多的33卷积核,在每一次池化操作后把通道数翻倍。借鉴了Network In Network的思想,网络使用了全局平均池化(Global Average Pooling)做预测,把11的卷积核置于3*3的卷积核之间,用来压缩特征。使用Batch Normalization稳定模型训练,加速收敛,正则化模型。
最终得出的基础模型就是Darknet-19,包含19个卷积层、5个最大值池化层(Max Pooling Layers )。Darknet-19处理一张照片需要55.8亿次运算,Imagenet的Top-1准确率为72.9%,Top-5准确率为91.2%。具体的网络结构见表3。

2.2 分类任务训练(Training For Classification)
作者采用ImageNet1000类数据集来训练分类模型。训练过程中,采用了 random crops, rotations, and hue, saturation, and exposure shifts等data augmentation方法。预训练后,作者采用高分辨率图像(448×448)对模型进行finetune。高分辨率下训练的分类网络Top-1准确率76.5%,Top-5准确率93.3%。
2.3 检测任务训练(Training For Detection)
为了把分类网络改成检测网络,作者将分类模型的最后一层卷积层去除,替换为三层卷积层(3×3,1024 filters),最后一层为1×1卷积层,输出维度filters为需要检测的数目。对于VOC数据集,预测5种Boxes,每个Box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。因此,输出为125(5x20+5x5) filters。最后还加入了passthough 层,从最后3 x 3 x 512的卷积层连到倒数第二层,使模型有了细粒度特征。
三. Stronger
如之前所说,物体分类,是对整张图片打标签,比如这张图片中含有人,另一张图片中的物体为狗;而物体检测不仅对物体的类别进行预测,同时需要框出物体在图片中的位置。物体分类的数据集,最著名的ImageNet,物体类别有上万个,而物体检测数据集,例如coco,只有80个类别,因为物体检测、分割的打标签成本比物体分类打标签成本要高很多。所以在这里,作者提出了分类、检测训练集联合训练的方案。
3.1 Joint Classification And Detection(联合分类和检测)
使用检测数据集的图片去学习检测相关的信息,例如Bounding Box 坐标预测,是否包含物体以及属于各个物体的概率。使用仅有类别标签的分类数据集图片去扩展可以检测的种类。训练过程中把监测数据和分类数据混合在一起。基本的思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。当然,一般的训练策略为,先在检测数据集上训练一定的epoch,待预测框的loss基本稳定后,再联合分类数据集、检测数据集进行交替训练,同时为了分类、检测数据量平衡,作者对coco数据集进行了上采样,使得coco数据总数和ImageNet大致相同。
联合分类与检测数据集,这里不同于将网络的backbone在ImageNet上进行预训练,预训练只能提高卷积核的鲁棒性,而分类检测数据集联合,可以扩充识别物体种类。比如狗,ImageNet上就包含超过100多类品种的狗。如果要联合训练,需要将这些标签进行合并。
大部分分类方法采用softmax输出所有类别的概率。采用softmax的前提假设是类别之间不相互包含(比如,犬和牧羊犬就是相互包含)。因此,我们需要一个多标签的模型来综合数据集,使类别之间不相互包含。
作者最后采用WordTree来整合数据集,解决了ImageNet与coco之间的类别问题。
3.2 Dataset combination with WordTree
可以使用WordTree把多个数据集整合在一起。只需要把数据集中的类别映射到树结构中的同义词集合(Synsets)。使用WordTree整合ImageNet和COCO的标签如图5所示:

树结构表示物体之间的从属关系非常合适,第一个大类,物体,物体之下有动物、人工制品、自然物体等,动物中又有更具体的分类。此时,在类别中,不对所有的类别进行softmax操作,而对同一层级的类别进行softmax:

如图6中所示,同一颜色的位置,进行softmax操作,使得同一颜色中只有一个类别预测分值最大。在预测时,从树的根节点开始向下检索,每次选取预测分值最高的子节点,直到所有选择的节点预测分值连乘后小于某一阈值时停止。在训练时,如果标签为人,那么只对人这个节点以及其所有的父节点进行loss计算,而其子节点,男人、女人、小孩等,不进行loss计算。
最后的结果是,Yolo v2可以识别超过9000个物体,作者美其名曰Yolo9000。当然原文中也提到,只有当父节点在检测集中出现过,子节点的预测才会有效。如果子节点是裤子、T恤、裙子等,而父节点衣服在检测集中没有出现过,那么整条预测类别支路几乎都是检测失效的状态。这也合理,给神经网络看的都是狗,让它去预测猫,目前神经网络还没有这么智能。
参考资料:
https://www.cnblogs.com/han-sy/p/13301054.html