DGL入坑
DGL教学
文章目录
- DGL教学
-
- 1. 数据集
- 2. 图特征
- 3. Graph Loader and Training
- 4. 自定义图神经网络
DGL官方文档:https://docs.dgl.ai/index.html
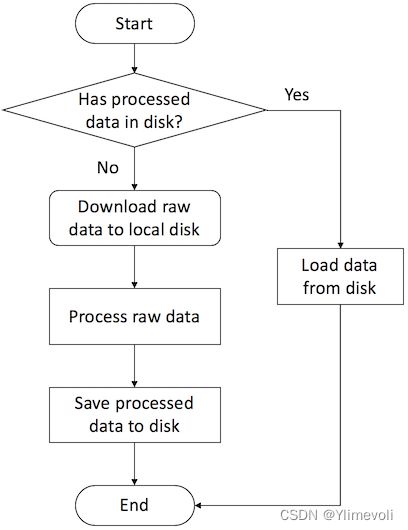
1. 数据集
from dgl.data import DGLDataset
class MyDataset(DGLDataset):
def __init__(self,
url=None,
raw_dir=None,
save_dir=None,
force_reload=False,
verbose=False):
super(MyDataset, self).__init__(name='dataset_name',
url=url,
raw_dir=raw_dir,
save_dir=save_dir,
force_reload=force_reload,
verbose=verbose)
def process(self):
# 将原始数据处理为图、标签和数据集划分的掩码
pass
def __getitem__(self, idx):
# 通过idx得到与之对应的一个样本
return self.reactant_graphs[i], self.prod_graphs[i], self.labels[i]
def __len__(self):
# 数据样本的数量
return len(self.reactant_graphs)
def save(self):
# 将处理后的数据保存至 `self.save_path`
print('saving dataset to ' + self.path + '.bin')
save_info(self.path + '_info.pkl', {'labels': self.labels})
dgl.save_graphs(self.path + '_reactant_graphs.bin', self.reactant_graphs)
dgl.save_graphs(self.path + '_product_graphs.bin', self.prod_graphs
def load(self):
# 从 `self.save_path` 导入处理后的数据
print('loading dataset from ' + self.path + '.bin')
self.reactant_graphs = dgl.load_graphs(self.path + '_reactant_graphs.bin')[0]
self.prod_graphs = dgl.load_graphs(self.path + '_product_graphs.bin')[0]
self.labels = load_info(self.path + '_info.pkl')['labels']
def has_cache(self):
# 检查在 `self.save_path` 中是否存有处理后的数据
pass
读取数据到这个类中,数据处理流程如下:对应模板中的process, save, load
2. 图特征
DGL使用自身的定义的数据结构,这部分应该在上述的process函数中处理,将读入的图转换为DGL图结构
import dgl
graph = dgl.graph((src, dst), num_nodes=n_node) #其中一种定义方式
常用的接口
graph.adj()
graph.ndata['']
graph.edata['']
其中ndata和edata对应图的点特征和边特征,可以多个
3. Graph Loader and Training
该步骤将步骤1的自定义数据集类放入图的迭代器中
from dgl.dataloading import GraphDataLoader
train_dataloader = GraphDataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True)
然后开始训练
for i in range(args.epoch):
model.train()
for batch in train_dataloader:
data, label = batch
y = model(data)
loss = ...
optimizer.zero_grad()
loss.backward()
optimizer.step()
4. 自定义图神经网络
常用的图神经网络
from dgl.nn import GraphConv, GATConv, SAGEConv, SGConv, TAGConv
初始化对应好输入和输出就行,源码在github的dgl-master\python\dgl\nn\pytorch\conv上(pytorch)
forward输入为DGL的graph
自定义图神经网络,要搞懂两个函数,graph内置函数
update_allapply_edges
第一个是对所有的点进行操作,第二个是对所有的边进行操作,这两个函数有两个输入,分布是message passing函数和reduce函数
-
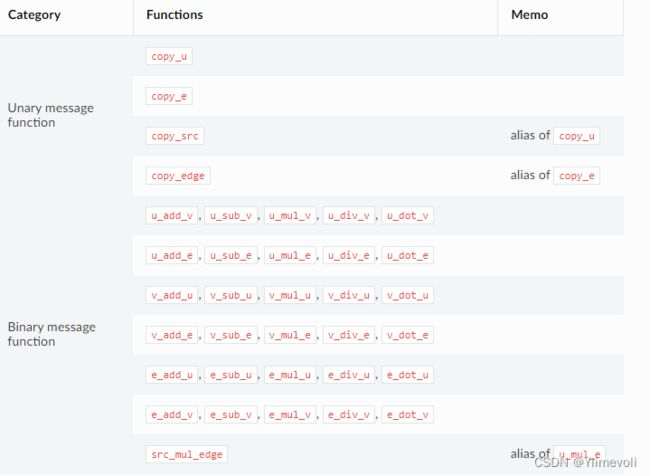
message passing函数
- 有如下已经定义好的
举例展示其操作:
copy_e(‘x’, ‘y’) : 就是将每个节点
v,与之关联的边(指向v的边)的特征x(graph.edata['v'])放到点v的点特征y上(graph.ndata['y']) 这步操作完后,
graph.ndata['y']的维度可以写作(为了方便理解): n × n e × h n\times n_e \times h n×ne×h, n n n表示节点数, n e n_e ne表示每个节点关联的边数(入度,每个节点不同), h h h表示特征维度
u_add_v(‘x’, ‘x’, ‘y’) :就是将每个节点
v,其特征x(graph.ndata['x'])与其邻居节点(指向自己)的特征x相加,放到点v的特征y上(graph.ndata['y']) 这步操作完后,
graph.ndata['y']的维度可以写作(为了方便理解): n × n i × h n\times n_i \times h n×ni×h, n n n表示节点数, n i n_i ni表示每个节点的邻居数(每个节点不同), h h h表示特征维度
其他操作类似,注意:这里u表示是源节点,v表示是目标节点
- 有如下已经定义好的
-
Reduce函数
就是将上述操作完的数据进行聚合,有如下:

举例:
sum(‘y’, ‘m’) : 就是将每个节点或者每条边的
y特征相加放到m上 -
自定义
- message passing
def message(self, edges): f = torch.cat([edges.src['h'], edges.dst['h'], edges.data['radial']], dim=-1) msg_h = self.edge_mlp(f) msg_x = self.coord_mlp(msg_h) * edges.data['x_diff'] return {'msg_x': msg_x, 'msg_h': msg_h}- reduce
def reducer(self, node): msg = torch.sum(node.mailbox['a'], dim=1) * torch.max(node.mailbox['a'], dim=1)[0] return {'m': msg}