从零开始手写一个Transformer
本文将带你从零开始实现一个Transformer,并将其应用在NMT任务上。
目录
- 一、符号说明
- 二、基本组件
-
- 2.1 MultiHeadAttention
- 2.2 PositionalEncoding
- 2.3 PositionWiseFFN
- 2.4 AddNorm
- 三、搭建Transformer
-
- 3.1 Encoder
- 3.2 Decoder
- 3.3 Transformer
- 3.4 验证
- 3.5 Transformer完整代码
- 四、Tranformer实战
-
- 4.1 训练与推理
- 4.2 结果展示
- 五、~~一些心得~~
- References
一、符号说明
| 符号 | 描述 |
|---|---|
| S S S | 源序列的长度 |
| T T T | 目标序列的长度 |
| N N N | 批量大小 |
| E E E | d_model |
Transformer的架构:
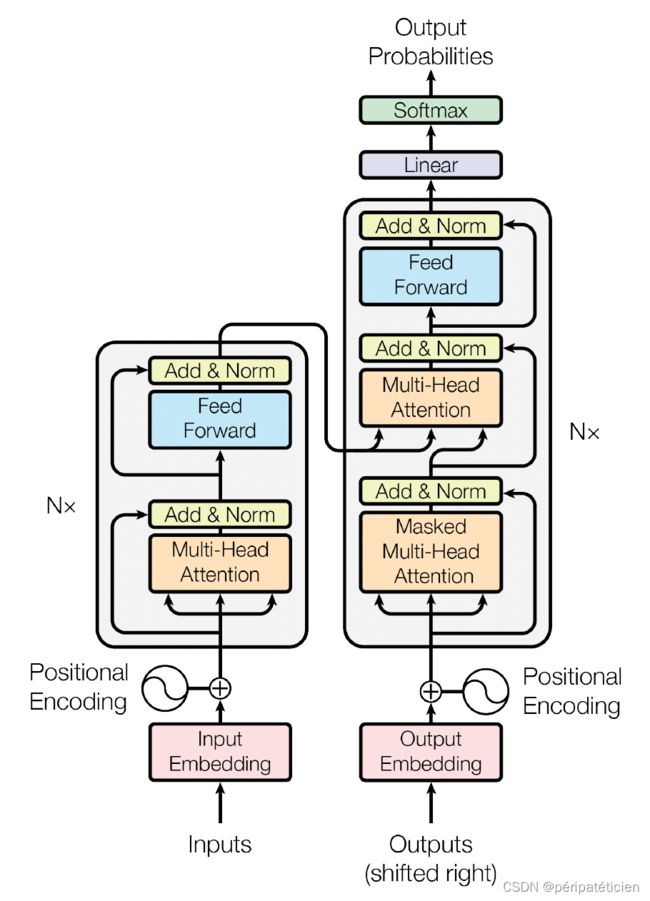
接下来我们会逐个实现上图中的基本组件,最后将这些基本组件拼接起来就可以得到Transformer了。
导入实现Transformer所需要的所有包
import math
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
二、基本组件
2.1 MultiHeadAttention
MHA我们之前已经实现过,这里不做过多介绍,详情可参考各种注意力机制的PyTorch实现。
需要补充的是,自注意力中的 attn_mask 可通过如下代码快速生成:
def generate_square_subsequent_mask(a):
return torch.triu(torch.full((a, a), -1e9), diagonal=1)
至于 key_padding_mask,以源序列 src 为例,初始输入形状为 ( N , S ) (N,S) (N,S),设
""" 一个可能的例子 """
src = torch.tensor([
[3, 5, 7, 0, 0],
[9, 4, 0, 0, 0],
[6, 7, 2, 1, 0],
])
src_key_padding_mask = src == 0
print(src_key_padding_mask)
# tensor([[False, False, False, True, True],
# [False, False, True, True, True],
# [False, False, False, False, True]])
2.2 PositionalEncoding
在自注意力机制中,即使打乱输入序列,最终得到的结果并不会变(只是顺序变了,但词嵌入本身没变),因此需要对输入序列注入位置信息。
以源序列为例,不考虑批量计算,则输入 X X X 的形状为 ( S , E ) (S,E) (S,E),位置编码使用形状相同的矩阵 P P P 并输出 X + P X+P X+P。设 P P P 的元素为 p i j p_{ij} pij,则
p i , 2 j = sin ( i / 1000 0 2 j / d model ) p i , 2 j + 1 = cos ( i / 1000 0 2 j / d model ) \begin{aligned} p_{i,2j}&=\sin(i/10000^{2j/d_{\text{model}}}) \\ p_{i,2j+1}&=\cos(i/10000^{2j/d_{\text{model}}}) \\ \end{aligned} pi,2jpi,2j+1=sin(i/100002j/dmodel)=cos(i/100002j/dmodel)
注意到 E E E 通常是固定的,但 S S S 我们可以指定,我们希望创建的 PositionalEncoding 类能够对不同的 S S S 完成相应的 X + P X+P X+P 操作,因此初始时可以创建一个足够大的 P P P,它的形状为 ( max_len , E ) (\text{max\_len},E) (max_len,E),之后相加时只需要执行 X + P [ : S , : ] X+P[\,:\!S, :] X+P[:S,:]。
class PositionalEncoding(nn.Module):
def __init__(self, d_model=512, dropout=0.1, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.P = torch.zeros(max_len, d_model)
row = torch.arange(max_len).reshape(-1, 1)
col = torch.pow(10000, torch.arange(0, d_model, 2) / d_model)
self.P[:, ::2] = torch.sin(row / col)
self.P[:, 1::2] = torch.cos(row / col)
self.P = self.P.unsqueeze(0).transpose(0, 1)
def forward(self, X):
X = X + self.P[:X.shape[0]].to(X.device)
return self.dropout(X)
2.3 PositionWiseFFN
所谓的 PositionWiseFFN,说白了就是只有一个隐藏层的MLP:
class FFN(nn.Module):
def __init__(self, d_model=512, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model),
)
def forward(self, X):
return self.net(X)
2.4 AddNorm
NLP任务中,BatchNorm的效果通常没有LayerNorm的效果好,所以我们在残差连接后接上LayerNorm:
class AddNorm(nn.Module):
def __init__(self, d_model=512, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(d_model)
def forward(self, X, Y):
return self.norm(X + self.dropout(Y))
三、搭建Transformer
3.1 Encoder
我们首先需要实现一个 TransformerEncoderLayer
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadSelfAttention(d_model, nhead, dropout=dropout)
self.addnorm1 = AddNorm(d_model, dropout)
self.ffn = FFN(d_model, dim_feedforward, dropout)
self.addnorm2 = AddNorm(d_model, dropout)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
X = src
X = self.addnorm1(X, self.self_attn(X, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0])
X = self.addnorm2(X, self.ffn(X))
return X
为了将多个 EncoderLayer 组合在一起形成 Encoder,我们需要定义一个可以复制layer的函数
# 将module复制N次
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
接下来实现 Encoder
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers=6, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.norm = norm
def forward(self, src, src_mask=None, src_key_padding_mask=None):
output = src
for mod in self.layers:
output = mod(output, src_mask=src_mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
有两点需要注意:
- 我们实现的Encoder并不自带位置编码(后续的Decoder也是如此),这样做是为了在面对不同任务时,我们不需要改动太多的代码。
- Encoder最后一层的输出称为Memory。
3.2 Decoder
同理先实现一个 DecoderLayer
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadSelfAttention(d_model, nhead, dropout=dropout)
self.addnorm1 = AddNorm(d_model, dropout)
self.cross_attn = MultiHeadAttention(d_model, nhead, dropout=dropout)
self.addnorm2 = AddNorm(d_model, dropout)
self.ffn = FFN(d_model, dim_feedforward, dropout)
self.addnorm3 = AddNorm(d_model, dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None):
X = tgt
X = self.addnorm1(X, self.self_attn(X, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0])
X = self.addnorm2(X, self.cross_attn(X, memory, memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0])
X = self.addnorm3(X, self.ffn(X))
return X
然后进行组装
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers=6, norm=None):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.norm = norm
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None):
output = tgt
for mod in self.layers:
output = mod(output, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
有一点需要注意,我们实现的Decoder不包含最后一个Linear层。
3.3 Transformer
有Encoder和Decoder后,我们就可以组装Transformer了
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
encoder_norm = nn.LayerNorm(d_model)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
def forward(self,
src,
tgt,
src_mask=None,
tgt_mask=None,
memory_mask=None,
src_key_padding_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None):
"""
Args:
src: (S, N, E)
tgt: (T, N, E)
src_mask: (S, S) or (N * num_heads, S, S)
tgt_mask: (T, T) or (N * num_heads, T, T)
memory_mask: (T, S)
src_key_padding_mask: (N, S)
tgt_key_padding_mask: (N, T)
memory_key_padding_mask: (N, S)
Returns:
output: (T, N, E)
"""
memory = self.encoder(src, src_mask, src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, a):
return torch.triu(torch.full((a, a), -1e9), diagonal=1)
def _reset_parameters(self):
""" Initiate parameters in the transformer model. """
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
3.4 验证
为了验证我们的Transformer模型搭建正确,我们需要进行输入输出测试
src_len = 5
tgt_len = 6
batch_size = 2
d_model = 16
nhead = 8
src = torch.randn(src_len, batch_size, d_model)
tgt = torch.randn(tgt_len, batch_size, d_model)
src_key_padding_mask = torch.tensor([[False, False, False, True, True],
[False, False, False, False, True]])
tgt_key_padding_mask = torch.tensor([[False, False, False, True, True, True],
[False, False, False, False, True, True]])
transformer = Transformer(d_model=d_model, nhead=nhead, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=200)
src_mask = transformer.generate_square_subsequent_mask(src_len)
tgt_mask = transformer.generate_square_subsequent_mask(tgt_len)
memory_mask = torch.randint(2, (tgt_len, src_len)) == torch.randint(2, (tgt_len, src_len))
output = transformer(src=src,
tgt=tgt,
src_mask=src_mask,
tgt_mask=tgt_mask,
memory_mask=memory_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=src_key_padding_mask)
print(output.shape)
# torch.Size([6, 2, 16])
能够正确输出,说明我们的模型没有问题。
3.5 Transformer完整代码
transformer.py
import math
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1, bias=True):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.dropout = dropout
assert self.head_dim * num_heads == embed_dim
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def forward(self, query, key, value, attn_mask=None, key_padding_mask=None):
"""
Args:
query: (n, N, embed_dim)
key: (m, N, embed_dim)
value: (m, N, embed_dim)
attn_mask (bool Tensor or float Tensor): (n, m) or (N * num_heads, n, m)
key_padding_mask (bool Tensor): (N, m)
Returns:
attn_output: (n, N, embed_dim)
attn_output_weights: (N, num_heads, n, m)
"""
return self._multi_head_forward_attention(query,
key,
value,
dropout_p=self.dropout,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
training=self.training)
def _multi_head_forward_attention(self, query, key, value, dropout_p, attn_mask=None, key_padding_mask=None, training=True):
q, k, v = self.q_proj(query), self.k_proj(key), self.v_proj(value)
n, N, embed_dim = q.size()
m = key.size(0)
if attn_mask is not None:
if attn_mask.dim() == 2:
assert attn_mask.shape == (n, m)
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
assert attn_mask.shape == (N * self.num_heads, n, m)
else:
raise RuntimeError
if key_padding_mask is not None:
assert key_padding_mask.shape == (N, m)
key_padding_mask = key_padding_mask.view(N, 1, 1, m).repeat(1, self.num_heads, 1, 1).reshape(N * self.num_heads, 1, m)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, -1e9)
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)
new_attn_mask.masked_fill_(attn_mask, -1e9)
attn_mask = new_attn_mask
q = q.reshape(n, N * self.num_heads, self.head_dim).transpose(0, 1)
k = k.reshape(m, N * self.num_heads, self.head_dim).transpose(0, 1)
v = v.reshape(m, N * self.num_heads, self.head_dim).transpose(0, 1)
if not training:
dropout_p = 0.0
attn_output, attn_output_weights = self._scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).reshape(n, N, embed_dim)
attn_output = self.out_proj(attn_output)
attn_output_weights = attn_output_weights.reshape(N, self.num_heads, n, m)
return attn_output, attn_output_weights
def _scaled_dot_product_attention(self, q, k, v, attn_mask=None, dropout_p=0.0):
"""
Args:
q: (N, n, E), where E is embedding dimension.
k: (N, m, E)
v: (N, m, E)
attn_mask: (n, m) or (N, n, m)
Returns:
attn_output: (N, n, E)
attn_weights: (N, n, m)
"""
q = q / math.sqrt(q.size(2))
if attn_mask is not None:
scores = q @ k.transpose(-2, -1) + attn_mask
else:
scores = q @ k.transpose(-2, -1)
attn_weights = F.softmax(scores, dim=-1)
if dropout_p > 0.0:
attn_weights = F.dropout(attn_weights, p=dropout_p)
attn_output = attn_weights @ v
return attn_output, attn_weights
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1, bias=True):
super().__init__()
self.mha = MultiHeadAttention(embed_dim, num_heads, dropout=dropout, bias=bias)
def forward(self, X, attn_mask=None, key_padding_mask=None):
"""
Args:
X (input sequence): (L, N, embed_dim), where L is sequence length.
"""
return self.mha(X, X, X, attn_mask=attn_mask, key_padding_mask=key_padding_mask)
class PositionalEncoding(nn.Module):
def __init__(self, d_model=512, dropout=0.1, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.P = torch.zeros(max_len, d_model)
row = torch.arange(max_len).reshape(-1, 1)
col = torch.pow(10000, torch.arange(0, d_model, 2) / d_model)
self.P[:, ::2] = torch.sin(row / col)
self.P[:, 1::2] = torch.cos(row / col)
self.P = self.P.unsqueeze(0).transpose(0, 1)
def forward(self, X):
X = X + self.P[:X.shape[0]].to(X.device)
return self.dropout(X)
class FFN(nn.Module):
def __init__(self, d_model=512, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model),
)
def forward(self, X):
return self.net(X)
class AddNorm(nn.Module):
def __init__(self, d_model=512, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(d_model)
def forward(self, X, Y):
return self.norm(X + self.dropout(Y))
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadSelfAttention(d_model, nhead, dropout=dropout)
self.addnorm1 = AddNorm(d_model, dropout)
self.ffn = FFN(d_model, dim_feedforward, dropout)
self.addnorm2 = AddNorm(d_model, dropout)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
X = src
X = self.addnorm1(X, self.self_attn(X, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0])
X = self.addnorm2(X, self.ffn(X))
return X
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers=6, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.norm = norm
def forward(self, src, src_mask=None, src_key_padding_mask=None):
output = src
for mod in self.layers:
output = mod(output, src_mask=src_mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadSelfAttention(d_model, nhead, dropout=dropout)
self.addnorm1 = AddNorm(d_model, dropout)
self.cross_attn = MultiHeadAttention(d_model, nhead, dropout=dropout)
self.addnorm2 = AddNorm(d_model, dropout)
self.ffn = FFN(d_model, dim_feedforward, dropout)
self.addnorm3 = AddNorm(d_model, dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None):
X = tgt
X = self.addnorm1(X, self.self_attn(X, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0])
X = self.addnorm2(X,
self.cross_attn(X, memory, memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0])
X = self.addnorm3(X, self.ffn(X))
return X
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers=6, norm=None):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.norm = norm
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None):
output = tgt
for mod in self.layers:
output = mod(output, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
encoder_norm = nn.LayerNorm(d_model)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
def forward(self,
src,
tgt,
src_mask=None,
tgt_mask=None,
memory_mask=None,
src_key_padding_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None):
"""
Args:
src: (S, N, E)
tgt: (T, N, E)
src_mask: (S, S) or (N * num_heads, S, S)
tgt_mask: (T, T) or (N * num_heads, T, T)
memory_mask: (T, S)
src_key_padding_mask: (N, S)
tgt_key_padding_mask: (N, T)
memory_key_padding_mask: (N, S)
Returns:
output: (T, N, E)
"""
memory = self.encoder(src, src_mask, src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, a):
return torch.triu(torch.full((a, a), -1e9), diagonal=1)
def _reset_parameters(self):
""" Initiate parameters in the transformer model. """
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
此文件可独立运行。
这里再次强调一下,我们手动搭建的Transformer(包括PyTorch官方的 nn.Transformer)仅仅是下图中的红框部分:
也就是说,Embedding、Positional Encoding 以及最后的 Linear 层需要我们自己手动实现。
四、Tranformer实战
这一小节我们会将之前搭建的Transformer应用到NMT任务上。
有关NMT任务可参考博主此前的两篇文章:
- 基于双语数据集搭建seq2seq模型
- 基于注意力机制的seq2seq模型
Transformer实际上有六个可选参数,分别是 src_mask、tgt_mask、memory_mask、src_key_padding_mask、tgt_key_padding_mask、memory_key_padding_mask。
在NMT任务的训练阶段中,这些参数的设置分别为:
src_mask=None
tgt_mask=tgt_mask
memory_mask=None
src_key_padding_mask=src_key_padding_mask
tgt_key_padding_mask=tgt_key_padding_mask
memory_key_padding_mask=src_key_padding_mask
在NMT任务的推理阶段中,这些参数的设置分别为:
src_mask=None
tgt_mask=tgt_mask
memory_mask=None
src_key_padding_mask=src_key_padding_mask
tgt_key_padding_mask=None
memory_key_padding_mask=src_key_padding_mask
定义 Seq2SeqModel:
class Seq2SeqModel(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6,
dim_feedforward=2048,
dropout=0.1):
super().__init__()
self.d_model = d_model
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.pe = PositionalEncoding(d_model, dropout)
self.transformer = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
self.out = nn.Linear(d_model, tgt_vocab_size)
def forward(self,
src,
tgt,
src_mask=None,
tgt_mask=None,
memory_mask=None,
src_key_padding_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None):
"""
Args:
src: (N, S)
tgt: (N, T)
tgt_mask: (T, T)
src_key_padding_mask: (N, S)
tgt_key_padding_mask: (N, T)
memory_key_padding_mask: (N, S)
"""
src = self.pe(self.src_embedding(src).transpose(0, 1) * math.sqrt(self.d_model)) # (S, N, E)
tgt = self.pe(self.tgt_embedding(tgt).transpose(0, 1) * math.sqrt(self.d_model)) # (T, N, E)
transformer_output = self.transformer(src=src,
tgt=tgt,
src_mask=src_mask,
tgt_mask=tgt_mask,
memory_mask=memory_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask) # (T, N, E)
logits = self.out(transformer_output) # (T, N, tgt_vocab_size)
return logits
在inference阶段,我们需要单独使用Transformer的Encoder和Decoder,因此我们还需为 Seq2SeqModel 定义 encoder 和 decoder 方法:
def encoder(self, src, src_mask=None, src_key_padding_mask=None):
"""
Args:
src: (N, S)
"""
src = self.pe(self.src_embedding(src).transpose(0, 1) * math.sqrt(self.d_model))
memory = self.transformer.encoder(src, src_mask, src_key_padding_mask)
return memory
def decoder(self,
tgt,
memory,
tgt_mask=None,
memory_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None):
"""
Args:
tgt: (N, T)
"""
tgt = self.pe(self.tgt_embedding(tgt).transpose(0, 1) * math.sqrt(self.d_model))
decoder_output = self.transformer.decoder(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask,
memory_key_padding_mask)
logits = self.out(decoder_output)
return logits
4.1 训练与推理
训练时,为了并行化计算,Tranformer会采用teacher forcing的手段,即将解码器的 target 偏移一位并在最前面加上 input。因为Tranformer没有像RNN那样的时序结构,为了防止 t t t 时刻的词元注意到之后时刻的词元,我们需要用到 tgt_mask 进行遮蔽,它是一个上三角矩阵,形状为 (tgt_len, tgt_len)。此外,我们还需提供 src_key_padding_mask 和 tgt_key_padding_mask,因为编码器的输入和解码器的输入都含有
训练函数定义如下:
def train(train_loader, model, criterion, optimizer, num_epochs):
train_loss = []
model.train()
for epoch in range(num_epochs):
for batch_idx, (encoder_inputs, decoder_targets) in enumerate(train_loader):
encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)
bos_column = torch.tensor([tgt_vocab['' ]] * decoder_targets.shape[0]).reshape(-1, 1).to(device)
decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)
tgt_mask = model.transformer.generate_square_subsequent_mask(SEQ_LEN)
src_key_padding_mask = encoder_inputs == 1 # 因为padding_idx=1
tgt_key_padding_mask = decoder_inputs == 1
pred = model(encoder_inputs,
decoder_inputs,
tgt_mask=tgt_mask.to(device),
src_key_padding_mask=src_key_padding_mask.to(device),
tgt_key_padding_mask=tgt_key_padding_mask.to(device),
memory_key_padding_mask=src_key_padding_mask.to(device))
loss = criterion(pred.permute(1, 2, 0), decoder_targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if (batch_idx + 1) % 50 == 0:
print(
f'[Epoch {epoch + 1}] [{(batch_idx + 1) * len(encoder_inputs)}/{len(train_loader.dataset)}] loss: {loss:.4f}'
)
print()
return train_loss
在推理阶段,我们只能一个一个词元进行输出,所以循环结构不可避免。因为解码器在遇到 tgt_key_padding_mask。
像RNN这种时序结构在推理阶段, t t t 时刻的输入来自 t − 1 t-1 t−1 时刻的输出,而Transformer这样的无时序架构,解码器的输入序列有多长相应的输出序列就有多长,我们该如何让Transformer像RNN那样一个一个词输出呢?
这里举一个简单的例子。不考虑 a b c ,则在训练阶段解码器的输入应当是
- 首先向解码器输入
a; - 把上一时刻的
a拿过来放在a a b; - 把上一时刻输出的最后一个词元(即
b)拿过来,放到a a b a b c; - 把上一时刻输出的最后一个词元(即
c)拿过来,放到a b a b c a b c; - 把上一时刻输出的最后一个词元拿过来,发现是
可能会有读者疑惑,第二时刻输入 a b,也有可能是 d b、e b 或是其他。这个情况的确会发生,但由于我们关注的是下一个词元,因此只需要取输出序列的最后一个词元再把它放到已预测序列的末尾即可。
此外还需注意,tgt_mask 的形状在推理阶段是动态变化的,取决于已预测出的序列的长度。
推理函数定义如下:
@torch.no_grad()
def translate(test_loader, model):
translation_results = []
model.eval()
for src_seq, tgt_seq in test_loader:
encoder_inputs = src_seq.to(device)
src_key_padding_mask = encoder_inputs == 1
memory = model.encoder(encoder_inputs, src_key_padding_mask=src_key_padding_mask)
pred_seq = [tgt_vocab['' ]]
for _ in range(SEQ_LEN):
decoder_inputs = torch.tensor(pred_seq).reshape(1, -1).to(device) # 注意是pred_seq而不是pred_seq[-1]
tgt_mask = model.transformer.generate_square_subsequent_mask(len(pred_seq))
pred = model.decoder(
decoder_inputs,
memory,
tgt_mask=tgt_mask.to(device),
memory_key_padding_mask=src_key_padding_mask.to(device)) # (len(pred_seq), 1, tgt_vocab_size)
next_token_idx = pred[-1].squeeze().argmax().item() # 选取输出序列的最后一个词元
if next_token_idx == tgt_vocab['' ]:
break
pred_seq.append(next_token_idx)
pred_seq = tgt_vocab[pred_seq[1:]]
assert len(pred_seq) > 0, "The predicted sequence is empty!"
tgt_seq = tgt_seq.squeeze().tolist()
tgt_seq = tgt_vocab[
tgt_seq[:tgt_seq.index(tgt_vocab['' ])]] if tgt_vocab['' ] in tgt_seq else tgt_vocab[tgt_seq]
translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
return translation_results
此外还需定义一个函数用来计算BLEU得分
def evaluate(translation_results, bleu_k_list=[2, 3, 4]):
assert type(bleu_k_list) == list and len(bleu_k_list) > 0
bleu_scores = {k: [] for k in sorted(bleu_k_list)}
for bleu_k in bleu_scores.keys():
for tgt_seq, pred_seq in translation_results:
if len(pred_seq) >= bleu_k:
bleu_scores[bleu_k].append(bleu(tgt_seq, pred_seq, k=bleu_k))
for bleu_k in bleu_scores.keys():
bleu_scores[bleu_k] = np.mean(bleu_scores[bleu_k])
return bleu_scores
之后我们就可以开始跑分了
# Parameter settings
set_seed()
BATCH_SIZE = 512
LEARNING_RATE = 0.0001
NUM_EPOCHS = 50
# Dataloader
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1)
# Model building
device = 'cuda' if torch.cuda.is_available() else 'cpu'
net = Seq2SeqModel(len(src_vocab), len(tgt_vocab)).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=1)
optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE, betas=(0.9, 0.98), eps=1e-9)
# Training phase
train_loss = train(train_loader, net, criterion, optimizer, NUM_EPOCHS)
torch.save(net.state_dict(), './params/trans_seq2seq.pt')
plt.plot(train_loss)
plt.ylabel('train loss')
plt.savefig('./output/loss.png')
# Evaluation
translation_results = translate(test_loader, net)
bleu_scores = evaluate(translation_results)
print(f"BLEU-2: {bleu_scores[2]} | BLEU-3: {bleu_scores[3]} | BLEU-4: {bleu_scores[4]}")
4.2 结果展示
GPU为RTX 3090,24G显存刚好够用,大概花了2个多小时跑完了50个epoch,损失函数曲线:
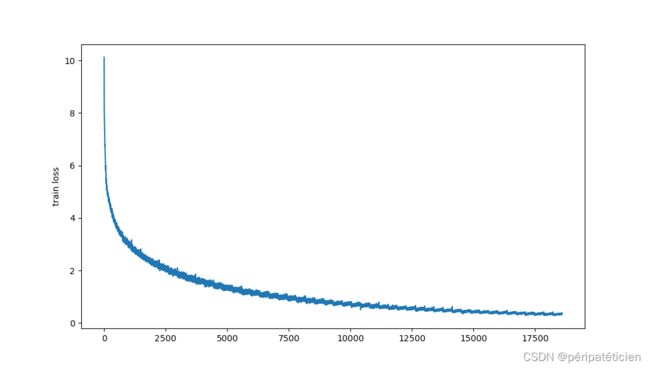
和此前模型对比:
| 模型 | 平均BLEU-2 | 平均BLEU-3 | 平均BLEU-4 |
|---|---|---|---|
| Vanilla Seq2Seq(链接) | 0.4799 | 0.3229 | 0.2144 |
| Attention-based Seq2Seq(链接) | 0.5711 | 0.4195 | 0.3036 |
| Transformer(本文) | 0.7992 | 0.7579 | 0.7337 |
五、一些心得
- 记得将各种
mask移动到GPU上,否则会造成数据不在同一设备上而报错。 - 因为个人习惯在正式训练前先调小
NUM_EPOCHS看看程序能不能跑通,此前使用1e-3学习率导致在推理阶段输入NUM_EPOCHS,但此时Transformer变成了复读机。最后将学习率调低至1e-4后模型才得以正常,如下:
optimizer = torch.optim.Adam(net.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
完整代码请前往 eng-fra-seq2seq 和 attention-pytorch 进行查看。码文不易,下载时还请您随手给一个follow和star,谢谢!
References
[1] https://arxiv.org/pdf/1706.03762.pdf
[2] https://www.zhihu.com/column/nulls
[3] https://pytorch.org/docs/stable/_modules/torch/nn/modules/transformer.html#Transformer
[4] https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html