ElasticSearch入门看这篇就够了
ElasticSearch入门
什么是ES?
ES是一个开源的分布式搜索引擎,可以用来实现搜索、日志统计分析、系统监控等,es底层基于lucene实现
什么是elastic stack ?
以elasticsearch为核心的技术栈,包括beats、logstash、kibana
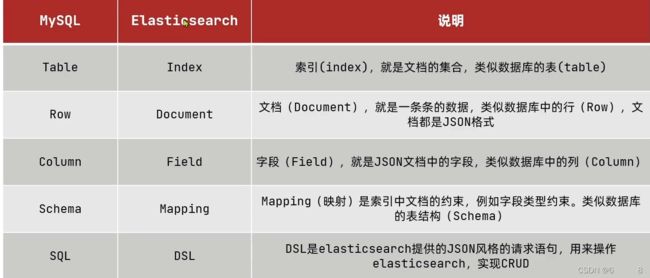
ES概念介绍
docker创建es
# 创建存放IK分词器的目录
mkdir -p /mnt/elasticsearch/plugins/ik
# 上传IK分词器
# 解压IK到指定路径
tar -xf ik-7.4.0.tar -C /mnt/elasticsearch/plugins/ik
# 创建单机版elasticsearch容器
docker run -id --name elasticsearch \
--net seckill_network --ip 172.36.0.13 \
-v /mnt/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--restart=always -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" elasticsearch:7.12.1
# 创建kibana
docker run -id --name kibana --net seckill_network \
-e ELASTICSEARCH_HOSTS=http://172.36.0.13:9200 \
--restart=always -p 5601:5601 kibana:7.12.1
# 安装head插件
docker pull mobz/elasticsearch-head:5
docker run --restart=always --name elasticsearch-head -di -p 9100:9100 docker.io/mobz/elasticsearch-head:5
IK分词器作用
创建倒排索引时对文档分词,用户搜索时对内容进行分词
分为粗粒度ik_smart 和ik_max_word 细粒度 两种模式
添加字典和禁用字典在IKAnalyzer.cfg配置中查看
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">entry>
<entry key="ext_stopwords">entry>
properties>
DSL语句创建索引库
PUT /abcd
{
"mappings": {
"properties": {
"info" :{
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword" ,
"index": false
}
}
}
}
// keyword:不进行分词 列如国家 人名
索引库一旦创建 不可修改原来的字段 但可以新增
DSL语句创建文档
POST /abcd/_doc/1
{
"email": "[email protected]",
"info": "abcd"
}
DSL 全量修改
PUT /abcd/_doc/1
{
"email": "[email protected]",
"info": "abcdedf"
}
DSL 增量修改
POST /abcd/_update/1
{
"doc": {
"email": "[email protected]"
}
}
RestClient操作索引库和文档
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
# 添加索引
@Test
void addIndex() throws IOException {
CreateIndexRequest createRequest = new CreateIndexRequest("hotel");
createRequest.mapping("", XContentType.JSON);
client.indices().create(createRequest, RequestOptions.DEFAULT);
}
# 添加文档数据
@Test
void addDoc() throws IOException {
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(hotel);
String jsonString = JSON.toJSONString(hotelDoc);
IndexRequest indexRequest = new IndexRequest("hotel").id(hotelDoc.getId().toString());
indexRequest.source(jsonString, XContentType.JSON);
client.index(indexRequest, RequestOptions.DEFAULT);
}
# 修改文档数据
@Test
void updateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("hotel", "36934");
updateRequest.doc(
"city", "湘潭"
);
client.update(updateRequest, RequestOptions.DEFAULT);
}
#批量添加
@Test
void batchDoc() throws IOException {
BulkRequest buikRequest = new BulkRequest();
List<Hotel> list = hotelService.list();
for (Hotel hotel : list) {
HotelDoc hotelDoc = new HotelDoc(hotel);
buikRequest.add(new IndexRequest("hotel").id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
client.bulk(buikRequest, RequestOptions.DEFAULT);
}
DSL query查询语法
# 查询所有
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
# 全文搜索
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
}
}
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "如家",
"fields": ["brand","name"]
}
}
}
# match根据一个字段查询 multi根据多个字段
# 精确查询
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 1000,
"lte": 2688
}
}
}
}
# term精确匹配 range范围查询
# 地理坐标查询
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"location": "31.21, 121.5"
}
}
}
GET /hotel/_search
{
"query": {
"geo_bounding_box":{
"location": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
# geo_distance 类似附近的人功能 以自已为中心条件为15km查找附近匹配的文档 # geo_bounding_box 查询geo_point落在某个矩形范围的所有文档
#复合查询 function_score 算分函数查询 可以控制文档相关性算分 ES5.0前使用TF+IDF算法 5.0以后使用BM25
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}

# 复合查询:布尔查询
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 400
}
}
}
],
"filter": {
"geo_distance": {
"distance": "10km",
"location": "31.21, 121.5"
}
}
}
}
}
# must: 必须匹配 should: 选择性匹配 或 must_not: 必须不匹配 不参与算分 取反 filter:必须匹配 不参与算分
# 排序 分页 高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 31.21,
"lon": 121.5
},
"order": "desc"
}
}
],
"highlight": {
"fields": {
"name": { # 高亮的字段
"pre_tags": "",
"post_tags": "",
"require_field_match": "false" #是否需要匹配字段 因为上面all是3个字段组装的 如果为true name不会高亮
}
}
},
"from": 2,
"size": 20
}
client实现布尔查询
@Test
void queryBool() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
// 构建条件
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.matchQuery("name", "如家"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").gte(400));
boolQuery.filter(QueryBuilders.geoDistanceQuery("location").point(31.21, 121.5).distance("10km"));
searchRequest.source().query(boolQuery);
// 布尔查询
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果
SearchHits hits = response.getHits();
// 获取总数
long value = hits.getTotalHits().value;
System.out.println(value);
// 获取数据
for (SearchHit hit : hits.getHits()) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
System.out.println(hotelDoc);
}
}
}
client实现排序高亮
@Test
void queryHighlight() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
// 构建条件
searchRequest.source().query(QueryBuilders.matchQuery("all", "如家"));
// 排序
searchRequest.source().sort(SortBuilders.geoDistanceSort("location", 31.21, 121.5).order(SortOrder.DESC).unit(DistanceUnit.KILOMETERS));
// 高亮
searchRequest.source().highlighter(new HighlightBuilder().field("name").preTags("").postTags("").requireFieldMatch(false));
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果
SearchHits hits = response.getHits();
// 获取总数
long value = hits.getTotalHits().value;
System.out.println(value);
// 获取数据
for (SearchHit hit : hits.getHits()) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
// 解析高亮字段
Map<String, HighlightField> map = hit.getHighlightFields();
HighlightField name = map.get("name");
// 获取高亮字段
String highlightName = name.getFragments()[0].toString();
hotelDoc.setName(highlightName);
System.out.println(hotelDoc);
}
}
}
# 布尔 复合 练习
public PageResult<HotelDoc> querylist(RequestParam param) {
try {
SearchRequest searchRequest = new SearchRequest("hotel");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 数据查询
if (StringUtils.isBlank(param.getKey())) {
boolQuery.must((QueryBuilders.matchAllQuery()));
} else {
boolQuery.must(QueryBuilders.matchQuery("all", param.getKey()));
}
// 星级判断
if (StringUtils.isNotBlank(param.getStarName())) {
boolQuery.filter(QueryBuilders.termQuery("startName", param.getStarName()));
}
// 品牌过滤
if (StringUtils.isNotBlank(param.getBrand())) {
boolQuery.filter(QueryBuilders.termQuery("brand", param.getBrand()));
}
// 城市过滤
if (StringUtils.isNotBlank(param.getCity())) {
boolQuery.filter(QueryBuilders.termQuery("city", param.getCity()));
}
// 价格判断
if (Objects.nonNull(param.getMinPrice()) && Objects.nonNull(param.getMaxPrice())) {
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(param.getMinPrice()).lte(param.getMaxPrice()));
}
// 复合查询 算法控制
FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD", true)
, ScoreFunctionBuilders.weightFactorFunction(5)) // isAD需要自已添加 功能:广告置顶
});
searchRequest.source().query(functionScoreQuery);
// 分页
int page = (param.getPage() - 1) * param.getSize();
int size = param.getSize();
searchRequest.source().from(page).size(size);
// 附近功能 + 排序
if (StringUtils.isNotBlank(param.getLocation())) {
searchRequest.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint(param.getLocation()))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS));
}
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
return buildResult(response);
} catch (IOException e) {
throw new RuntimeException();
}
}
什么是数据聚合?
对文档数据进行统计、分析、计算
常见种类有哪些?参与聚合的字段必须是什么类型的?
常见有桶:对文档数据分组,并统计每组数据 度量:对数据进行计算 avg sum 管道:对其它聚合再做操作
字段为keyword、数值、日期、布尔
# 桶聚合操作
GET /hotel/_search
{
"size" : 0, # 只查询统计的结果 不显示文档数据
"aggs": {
"brangAgg": {
"terms": { # 聚合字段的类型
"field": "brand",
"size": 20, # 获取多少条数据
"order": {
"_count": "asc" # 根据count值排序
}
}
}
}
}
api实现
void testAggregation() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().size(0);
searchRequest.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand").size(20)
.order(BucketOrder.count(true)));
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms brangAgg = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brangAgg.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}
}
# 实现度量聚合
GET /hotel/_search
{
"size" : 0,
"aggs": {
"brangAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "asc"
}
},
"aggs": { # brands的子聚合 分组后对每组分别计算
"scoreAgg": {
"stats": { # 聚合类型 stats可以计算min max avg
"field": "score"
}
}
}
}
}
}
# 拼音分词器
# 上传到虚拟机中,elasticsearch的plugin目录
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
# 自动查询补全 要求文档类型必须是completion 内容是多个词条形成的数组
PUT test3
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
POST /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
api实现
void testSuggest() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().suggest(new SuggestBuilder().addSuggestion("title_suggest",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("hz")
.skipDuplicates(true).size(20)));
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("title_suggest");
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String string = option.getText().toString();
System.out.println(string);
}
}
}