口语语言理解最新进展及前沿
口语语言理解
作为任务型对话系统的核心组件,目的是为了获取用户询问语句的框架语义表示信息,进而将这些信息为对话状态的追踪模块 D S T DST DST,
以及自然语言生成模块 N L G NLG NLG所使用
S L U SLU SLU任务通常包含以下两个任务:
- 意图识别任务: intent detection
- 槽位填充任务:slot filling
以图1的句子「I like to watch action movie」为例,这两个任务的输出对应分别为Watch Movie和O, O, O, B-movie-type,I-movie-type, I-movie-type

意图标注和槽位标注(BIO模式)
一般来将,我们可以将意图分类视作为一个句分类问题,研究也主要基于怎样对句子粒度的特征进行更好的表示,从传统特征表示到CNN,到基于RNN一系列模型等等,更好的句子表示被不断的挖掘。
意图识别问题可以被视作为一个序列分类问题,流行的方法从 C R F CRF CRF到 R N N RNN RNN再到 L S T M LSTM LSTM等等,研究为了对,对话单句里面的词进行更好的表示而不断挖掘。
传统的方法一般将意图识别和槽位填充视作两个独立的任务。忽视了这两个任务之间的共享信息,比如如果一个句子的意图是WatchMovie,那么这个句子就更可能包含movie name的槽位而不是music name的槽位。
考虑到这一点,随着对于联合模型的进一步挖掘,如图2所示,目前最好的工作,已经在 S L U SLU SLU领域的两个最广泛使用的数据集
ATIS[1]和SNIPS[2]上取得了96.6%和97.1%的槽位填充表现和98%到99%的意图识别表现。

图2 近期模型表现的趋势,目前SOTA(State-of-the-art)的工作在2020年取得了96.6%和97.1%的槽位填充表现和98%到99%的意图识别表现
如此高的分数不禁留给了我们研究者一个问题:我们已经完美地解决了口语语言理解这个任务了吗?
我们将通过领域综述的方式解答这个问题,我们的综述内容主要包含三个方面:
- 最近SLU领域进展的全面总结
- 复杂情境下研究的挑战和机遇
- SLU全面的代码,数据集等资源。
领域模型的分类
我们在本survey中提供了多元化的角度对模型进行了分类和归纳:
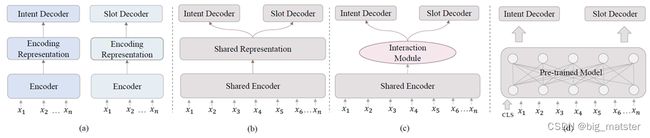
a:单任务模型、b是隐式联合建模、c是显式联合建模、d为预训练范式。
按照是否将意图识别任务和槽位填充任务看作联合任务。也可以将模型分类为单任务模型和联合模型。
- Single model:单任务模型
- Joint model:联合模型
单 任务工作主要集中在联合模型兴起之前,我们在文章中介绍了一些经典的两个任务上的单模型工作,比如RNN类型的探索,LSTM的引入,与CRF重构结合,句子信息利用上下文的探索等,并且为这些工作整理了结果。
意图识别和槽位填充任务的经典单模型工作。

在联合模型中,我们又可以根据共享信息是采用一个共享编码器隐式学习的,还是专门设计机构去进行任务之间交互的,去将联合模型分为隐式联合和显式联合 - Implicit Joint: 隐式联合
- Explicit Joint: 显式联合
隐式联合模型中我们介绍了采用共享编码器的Joint ID and SF模型[7],将注意力机制引入的Attention bi-RNN模型[8]等等模型。我们节选了部分经常被使用作为baseline的模型,将他们的结果整理到表格中,方便研究者进行查阅。
意图识别和槽位填充任务联合模型表现

在显式联合里面又可以根据交互的信息指导的利用方向将模型分为利用意图指导槽位的单方向交互(Single Flow Interaction)和两个方向互相交互的同时也使用槽位预测信息指导意图识别的双方向交互(Bidirectional Flow Interaction),单向交互包含了Slot-Gated模型[9],Self-Attention模型[10]和Stack-Propagation模型[11]等,双向交互介绍了Bi-Model[12],SF-ID[13],co-interactive transformer[14]等模型。
- 预训练范式
- 非预训练范式
此外,随着预训练模型的兴起,我们又将模型根据是否使用预训练模型的信息提取编码分为预训练范式的和非预训练范式的。当下研究中预训练在SLU的具体使用和其在一般的句子分类任务和序列分类任务的使用类似,以BERT模型为例,研究一般在句子的开头加入[CLS]符号作为句子信息的聚合锚定位置,然后将**[CLS]位置的编码作为句子的编码**,将其他位置的编码作为对应词的编码。我们介绍了BERT-Joint[15],Joint BERT +CRF[16]这些较为朴素直接的方法,和将编码器切换为预训练编码器进一步提升性能的Stack-Propagation +BERT[11],co-interactive transformer +BERT[14]等等相关的工作。
以我们提出的分类方式作为线索,我们可以更加清晰全面的对于当下研究提出的模型进行概括归类,深化我们对于领域研究的理解。
更复杂情境下的口语理解
新领域与挑战
我们之前的一个设定中,假定了一个单领域、单语言、单句对话等等较为强的假设下解决问题的情景。而在真实场景中,领域是较为灵活的,语言是较为多变的,单句对话情况是居于少数不利于用户体验的,所以该假定实际上限制了我们的应用能力,离我们的真实生活应用场景还有一段不小的距离。
我们在综述中对如下所述诸多重要的、具有更加复杂设定的新研究领域进行了相关工作的介绍与研究中所包含的挑战的总结
上下文的口语理解
实际情景中完成一个任务需要多轮次对话,多次的来-回而互相关联对话考验我们的系统能够更加有效的去获取上下文信息,我们介绍了领域的一项相关工作,包括采用记忆网络结构、动态利用上下文信息聚合等。
总结了该领域包含的主要挑战有如何更好的将上下文信息进行聚合,以及如何克服远距离获取有效信息的障碍。
多意图口语理解
在亚马逊内部语音数据集上,52%的对话都是具有多意图的,对句子能够多意图的设定能够更好的接近真实生活场景。
为了我们介绍了一项相关工作,包括:联合进行多意图分类和槽位填充任务模型和进行多意图和槽位填充交互的模型等等,我么总结了当下的挑战主要在于,解决如何有效的对多意图和槽位填充进行交互和缺少相关的表中数据等问题。
中文口语理解
中文社区需要中文口语理解以进行相关的工作,我们介绍了一项相关工作,如字粒度编码和词粒度和字粒度结合信息的编码的方法。
当下中文口语理解所面临的挑战是,如何有效的将词语信息集成以及如何处理特有的中文分词多种分词引发的问题。
跨领域口语理解
对于单个领域的假设,我们限制了模型的表现,实际上我们的模型虽然在具有大量数据上的单领域语料上取得了良好的表现,但是却无法在切换到新领域后仍然保持相关的表现,限制了模型在实际使用中的实用性。
我们将当前的跨领域模型分类为隐式的多领域的信息编码共享和多领域的模型编码交互两类,介绍了一些相关的工作。我们总结该领域主要的挑战还有领域之间的信息的转化和领域零资源情景下模型表现。
- 领域之间的信息转化
- 领域零资源情境下的模型表现。
跨语言口语理解
我们这里所指的跨语言口语理解是指赋予模型在英语语言与语料训练之后能具有直接在其它语言上进行使用的能力,鉴于我们拥有充足的英语资源而在其他语言以及其他诸多小语种内没有那么多的资源,这个领域也逐渐引起大家的重视。
我们介绍了一些相关的工作,包含一些专门为跨语言口语理解提出来的数据集以及为了不同语言的词语更好地对齐的数据增强方法。我们总结该领域的研究主要的挑战有解决不同词语之间的对齐,和用来处理新语言不断出现的模型的生成性。
低资源口语理解
我们之前设定的假设我们具有相对充足的语料进行训练,但是实际上随着应用的快速部署,经常有新出现的对话情境下的数据很少甚至没有数据的情况。
我们将这些情况对应的研究分类为:少样本口语理解、零资源口语理解、和无监督口语理解,三个类别,我们对其进行了相关概念和工作的介绍。
我们总结该领域的挑战主要在于,当前还很少有演技专注于如何在低资源条件下,充分利用意图和槽位的连接以及当前公开用于衡量模型能力的Benchmark仍旧缺少.
总结
- 慢慢的将该领域的知识点,啥的全部都将其搞彻底,研究透彻。
*慢慢的理解该领域的全部研究内容都行啦的理由与打算。