github项目复现和讲解之--------ML-for-SQL-Injection
机器学习SQL注入
- 相关算法基础
-
- SVM算法
- Adaboost算法
- 决策树
- 随机森林
- KNN
- 贝叶斯
复现原文
相关算法基础
作者的readme
ML-for-SQL-Injection 机器学习检测SQL注入
本项目是使用机器学习算法来分类SQL注入语句与正常语句:
使用了SVM,Adaboost,决策树,随机森林,逻辑斯蒂回归,KNN,贝叶斯等算法分别对SQL注入语句与正常语句进行分类。
data是收集的样本数据 file中存放的是训练好的各个模型 featurepossess.py是对原始样本进行预处理,提特征。
sqlsvm.py等py文件是训练模型 testsql是对训练好的模型进行测试,用准确率来度量模型效果
那我们先挨个补充每个算法的一点基础知识
SVM算法
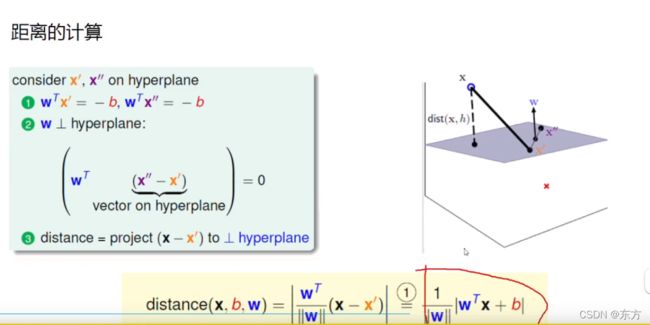
这有一个距离的计算。
用法向量的模来求点到平面的距离。

训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以 SVM 不太容易产生 overfitting。
SVM 训练出来的模型完全依赖于支持向量,即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
一个 SVM 如果训练得出的支持向量个数比较少,那么SVM 训练出的模型比较容易被泛化。
Adaboost算法
算法原理
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。
优点
(1)精度很高的分类器
(2)提供的是框架,可以使用各种方法构建弱分类器
(3)简单,不需要做特征筛选
(4)不用担心过度拟合
实际应用
(1)用于二分类或多分类
(2)特征选择
(3)分类人物的baseline
决策树
优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是O(log2m)。 m为样本数。
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
我们再看看决策树算法的缺点::
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动(特别是在节点的末梢),导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
随机森林
这个森林和树是有关系的,
森林 刚好可以弥补 树的缺点。
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现
KNN
流程:
1) 计算已知类别数据集中的点与当前点之间的距离
2) 按距离递增次序排序
3) 选取与当前点距离最小的k个点
4) 统计前k个点所在的类别出现的频率
5) 返回前k个点出现频率最高的类别作为当前点的预测分类
优点:
1、简单有效
2、重新训练代价低
3、算法复杂度低
4、适合类域交叉样本
5、适用大样本自动分类
缺点:
1、惰性学习
2、类别分类不标准化
3、输出可解释性不强
4、不均衡性
5、计算量较大
贝叶斯
朴素贝叶斯分类的优缺点
优点:
(1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化医学即可!)
(2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
缺点:
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
有了这些算法基础,
直接拿项目的代码来实践学习
我又去找了GitHub最新分支,
然后还是错误。最后发现引用用一个文件下的.py文件的函数的时候,
原文代码没有加包名。
我手动加上以后不报错了。
之后又是一个bug
cannot import name 'joblib'
原因:
安装的Scikit-learn版本太高,我安装的版本是0.23.1
解决方法:
需要将Scikit-learn版本降到0.21以下
pip uninstall joblib scikit-learn sklearn
pip install Scikit-learn==0.20.4
或者直接安装joblib:
pip install joblib
现在终于到代码环节:
先看第一个
featureprosess,这个py是提取特征的
需要用正则表达式的知识