cuda在ubuntu的安装使用分享
前言
之前给大家分享过opencv在jetson nano 2gb和ubuntu设备中使用并且展示了一些人脸识别等的小demo。但是对于图像处理,使用gpu加速是很常见 .(以下概念介绍内容来自百科和网络其他博主文章)
GPU介绍(从GPU诞生之日起,GPU的设计逻辑与CPU的设计逻辑相差很多。GPU从诞生之日起,它的定位是3D图形渲染设备。在设计GPU时从其功能出发,把更多的晶体管用于数据处理。这使得GPU相比CPU有更强的单精度浮点运算能力。人们为了充分利用GPU的性能,使用了很多方法。这)加速处理是比较常见的。
在而GPU加速的软件实现中我们可能会听到 opengl opencl cuda这些名词。下面再给大家分别介绍一下这几种区别:
OpenGL(英语:Open Graphics Library,译名:开放图形库或者“开放式图形库”)是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API)。这个接口由近350个不同的函数调用组成,用来绘制从简单的图形比特到复杂的三维景象。而另一种程序接口系统是仅用于Microsoft Windows上的Direct3D。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发。
OpenCl(是由苹果(Apple)公司发起,业界众多著名厂商共同制作的面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境。便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。)
从2007年以后,基于CUDA和OpenCL这些被设计成具有近似于高阶语言的语法特性的新GPGPU语言,降低了人们使用GPGPU的难度,平缓了开始时的学习曲线。使得在GPGPU领域,OpenGL中的GLSL逐渐退出了人们的视线。来源:
简单说OpenCL与OpenGL一样,都是基于硬件API的编程。OpenGL是针对图形的,而OpenCL则是针对并行计算的API,而针对并行计算下面还有一个cuda。
CUDA(Compute Unified Device Architecture,统一计算架构)是由英伟达NVIDIA所推出的一种整合技术,是该公司对于GPGPU的正式名称。透过这个技术,使用者可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。NVIDIA行销的时候,往往将编译器与架构混合推广,造成混乱。实际上,CUDA可以相容OpenCL或者自家的C-编译器。无论是CUDA C-语言或是OpenCL,指令最终都会被驱动程式转换成PTX代码,交由显示核心计算。
通俗的介绍,cuda是nvidia公司的生态,它前者是配备完整工具包、针对单一供应商(NVIDIA)的成熟的开发平台,opencl是一个开源的标准。
CUDA是NVIDIA GPU编程语言, OpenCL是异构计算库。CUDA和C++虽然都可以用nvcc编译,但C++只能在CPU上跑,CUDA只能在GPU上跑;而OpenCL并不局限于某个计算设备,旨在将同样的任务通过其提供的抽象接口在多种硬件上运行(CPU,GPU,FPGA,etc)
跨平台性和通用性上OpenCL占有很大优势(这也是很多National Laboratory使用OpenCL进行科学计算的最主要原因)。OpenCL支持包括ATI,NVIDIA,Intel,ARM在内的多类处理器,并能支持运行在CPU的并行代码,同时还独有Task-Parallel Execution Mode,能够更好的支持Heterogeneous Computing。这一点是仅仅支持数据级并行并仅能在NVIDIA众核处理器上运行的CUDA无法做到的。
在开发者友好程度CUDA在这方面显然受更多开发者青睐。原因在于其统一的开发套件(CUDA Toolkit, NVIDIA GPU Computing SDK以及NSight等等)、非常丰富的库(cuFFT, cuBLAS, cuSPARSE, cuRAND, NPP, Thrust)以及NVCC(NVIDIA的CUDA编译器)所具备的PTX(一种SSA中间表示,为不同的NVIDIA GPU设备提供一套统一的静态ISA)代码生成、离线编译等更成熟的编译器特性。相比之下,使用OpenCL进行开发,只有AMD对OpenCL的驱动相对成熟。 来源
今天的主题来自介绍cuda的使用,前面这部分概念性的介绍(来源都是网络,只有一小部分是自己写的)只是帮助大家好理解今天要使用的cuda,那么开始进入正题。(自己本身的电脑带NVIDIA的显卡,以及手里面有jetson nano的NVIDIA板卡,所以才使用cuda,其他朋友使用请注意自己手中的硬件是否有NVIDIA的显卡)。
接下来,我大致分为三个部分介绍,一、cuda并行计算原理介绍 ,二、cuda环境安装和直接使用,三、opencv中cuda安装和使用
作者:良知犹存
转载授权以及围观:欢迎关注微信公众号:羽林君
或者添加作者个人微信:become_me
cuda并行计算原理介绍
GPU背景介绍
GPU里有很多Compute Unit(计算单元), 这些单元是由专门的处理逻辑, 很多register, 和L1 cache 组成. Memory access subsystem 把GPU 和RAM 连起来(通常是个L2 cache). Threads 以SIMT的形式运行: 多个thread共享一个instruction unit. 对NV GPU来说, 32 thread 组成一个warps, 对AMD GPU 来说, 64 threads 叫做一个wave fronts. 本文只使用warp的定义. 想达到最高速度, 一定要讨论SIMT, 因为它影响着memory access 也会造成code的序列化(serialization, parallelism的反面)
kernel function里会指出哪些code由一条thread处理, host program会决定多少条thread来处理一个kernel. 一个work group 里的thread可以通过barrier synchronization, 共享L1 cache 来互相协力. 再由compute unit处理这些work group. 能同时被conpute unit 运行的work group数量有限, 所以很多得等到其他完成之后再运行. 需要处理的work group的size和数量还有最大并行数量被称为kernel的execution configuration(运行配置).
kernel 的占用率就是指同时运行的thread数量除以最大数量. 传统建议就是提升这个占用率来获得更好的性能, 但也有一些其他因素比如ILP, MLP, instruction latencies, 也很关键.内容来源
- GPU架构特点
首先我们先谈一谈串行计算和并行计算。我们知道,高性能计算的关键利用多核处理器进行并行计算。
当我们求解一个计算机程序任务时,我们很自然的想法就是将该任务分解成一系列小任务,把这些小任务一一完成。在串行计算时,我们的想法就是让我们的处理器每次处理一个计算任务,处理完一个计算任务后再计算下一个任务,直到所有小任务都完成了,那么这个大的程序任务也就完成了。

串行计算的缺点非常明显,如果我们拥有多核处理器,我们可以利用多核处理器同时处理多个任务时,而且这些小任务并没有关联关系(不需要相互依赖,比如我的计算任务不需要用到你的计算结果),那我们为什么还要使用串行编程呢?为了进一步加快大任务的计算速度,我们可以把一些独立的模块分配到不同的处理器上进行同时计算(这就是并行),最后再将这些结果进行整合,完成一次任务计算。下图就是将一个大的计算任务分解为小任务,然后将独立的小任务分配到不同处理器进行并行计算,最后再通过串行程序把结果汇总完成这次的总的计算任务。
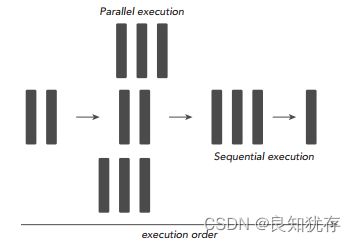
所以,一个程序可不可以进行并行计算,关键就在于我们要分析出该程序可以拆分出哪几个执行模块,这些执行模块哪些是独立的,哪些又是强依赖强耦合的,独立的模块我们可以试着设计并行计算,充分利用多核处理器的优势进一步加速我们的计算任务,强耦合模块我们就使用串行编程,利用串行+并行的编程思路完成一次高性能计算。
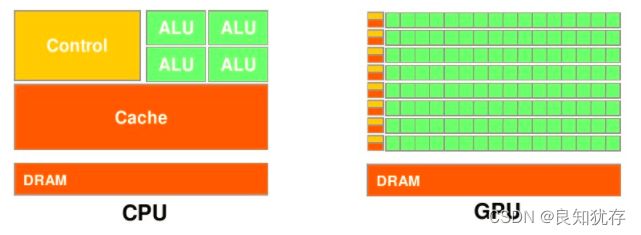
接下来我们谈谈CPU和GPU有什么区别,他们俩各自有什么特点,我们在谈并行、串行计算时多次谈到“多核”的概念,现在我们先从“核”的角度开始这个话题。首先CPU是专为顺序串行处理而优化的几个核心组成。而GPU则由数以千计的更小、更高效的核心组成,这些核心专门为同时处理多任务而设计,可高效地处理并行任务。也就是,CPU虽然每个核心自身能力极强,处理任务上非常强悍,无奈他核心少,在并行计算上表现不佳;反观GPU,虽然他的每个核心的计算能力不算强,但他胜在核心非常多,可以同时处理多个计算任务,在并行计算的支持上做得很好。
GPU和CPU的不同硬件特点决定了他们的应用场景,CPU是计算机的运算和控制的核心,GPU主要用作图形图像处理。图像在计算机呈现的形式就是矩阵,我们对图像的处理其实就是操作各种矩阵进行计算,而很多矩阵的运算其实可以做并行化,这使得图像处理可以做得很快,因此GPU在图形图像领域也有了大展拳脚的机会。下图表示的就是一个多GPU计算机硬件系统,可以看出,一个GPU内存就有很多个SP和各类内存,这些硬件都是GPU进行高效并行计算的基础。

现在再从数据处理的角度来对比CPU和GPU的特点。CPU需要很强的通用性来处理各种不同的数据类型,比如整型、浮点数等,同时它又必须擅长处理逻辑判断所导致的大量分支跳转和中断处理,所以CPU其实就是一个能力很强的伙计,他能把很多事处理得妥妥当当,当然啦我们需要给他很多资源供他使用(各种硬件),这也导致了CPU不可能有太多核心(核心总数不超过16)。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境,GPU有非常多核心(费米架构就有512核),虽然其核心的能力远没有CPU的核心强,但是胜在多, 在处理简单计算任务时呈现出“人多力量大”的优势,这就是并行计算的魅力。内容来源
整理一下两者特点就是:
- 1.CPU:擅长流程控制和逻辑处理,不规则数据结构,不可预测存储结构,单线程程序,分支密集型算法
- 2.GPU:擅长数据并行计算,规则数据结构,可预测存储模式
CUDA存储器类型:
每个线程拥有自己的 register寄存器 and loacal memory 局部内存
每个线程块拥有一块 shared memory 共享内存
所有线程都可以访问 global memory 全局内存
还有,可以被所有线程访问的
只读存储器:
constant memory (常量内容) and texture memory
a. 寄存器Register
寄存器是GPU上的高速缓存器,其基本单元是寄存器文件,每个寄存器文件大小为32bit.
Kernel中的局部(简单类型)变量第一选择是被分配到Register中。
特点:每个线程私有,速度快。
b. 局部存储器 local memory
当register耗尽时,数据将被存储到local memory。
如果每个线程中使用了过多的寄存器,或声明了大型结构体或数组,
或编译器无法确定数组大小,线程的私有数据就会被分配到local memory中。
特点:每个线程私有;没有缓存,慢。
注:在声明局部变量时,尽量使变量可以分配到register。如:
unsigned int mt[3];
改为: unsigned int mt0, mt1, mt2;
c. 共享存储器 shared memory
可以被同一block中的所有线程读写
特点:block中的线程共有;访问共享存储器几乎与register一样快.
d. 全局存储器 global memory
特点:所有线程都可以访问;没有缓存
e. 常数存储器constant memory
用于存储访问频繁的只读参数
特点:只读;有缓存;空间小(64KB)
注:定义常数存储器时,需要将其定义在所有函数之外,作用于整个文件
f. 纹理存储器 texture memory
是一种只读存储器,其中的数据以一维、二维或者三维数组的形式存储在显存中。
在通用计算中,其适合实现图像处理和查找,对大量数据的随机访问和非对齐访问也有良好的加速效果。
特点:具有纹理缓存,只读。
threadIdx,blockIdx, blockDim, gridDim之间的区别与联系
在启动kernel的时候,要通过指定gridsize和blocksize才行
dim3 gridsize(2,2); // 2行*2列*1页 形状的线程格,也就是说 4个线程块
gridDim.x,gridDim.y,gridDim.z相当于这个dim3的x,y,z方向的维度,这里是2*2*1。
序号从0到3,且是从上到下的顺序,就是说是下面的情况:
具体到 线程格 中每一个 线程块的 id索引为:
grid 中的 blockidx 序号标注情况为: 0 2
1 3
dim3 blocksize(4,4); // 线程块的形状,4行*4列*1页,一个线程块内部共有 16个线程
blockDim.x,blockDim.y,blockDim.z相当于这个dim3的x,y,z方向的维度,
这里是4*4*1.序号是0-15,也是从上到下的标注:
block中的 threadidx 序号标注情况 0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
1. 1维格子,1维线程块,N个线程======
实际的线程id tid = blockidx.x * blockDim.x + threadidx.x
块id 0 1 2 3
线程id 0 1 2 3 4
2. 1维格子,2D维线程块
块id 1 2 3
线程id 0 2
1 3
块id 块线程总数
实际的线程id tid = blockidx.x * blockDim.x * blockDim.y +
当前线程行数 每行线程数
threadidx.y * blockDim.x +
当前线程列数
threadidx.x
更加详细信息,大家可以参考这两篇文章:
https://www.cnblogs.com/skyfsm/p/9673960.html
https://github.com/Ewenwan/ShiYanLou/tree/master/CUDA
安装cuda使用环境
cuda使用中 首先我们直接安装CUDA toolkit (cuDNN是用于配置深度学习使用,本次我没有使用到,就是下载cuDNN的库放置到对应的链接库目录,大家可以自行去搜索安装),然后直接调用cuda的api进行一些计算的测试,还有是可以安装opencv中的cuda接口,通过opencv中的cuda使用。
直接使用cuda
直接安装CUDA ,首先需要下载安装包
- CUDA toolkit(toolkit就是指工具包)
- cuDNN 注:cuDNN 是用于配置深度学习使用(这次我没有使用就没有下载)
官方教程
CUDA:Installation Guide Windows :: CUDA Toolkit Documentation(链接)

- 注:按照自己版本去查看资料,打开链接后,右上角处有一个older选项,大家可以选择自己对应的版本文档。
cuDNN:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation(链接)
安装cuda要注意一个版本匹配问题,就是我们不同的显卡是对应不同的驱动。所以第一步就是查看显卡驱动版本,我使用的是Ubuntu,和window安装有些区别。第一如果我们安装过自己的显卡驱动,
使用 nvidia-smi命令查看支持的cuda版本
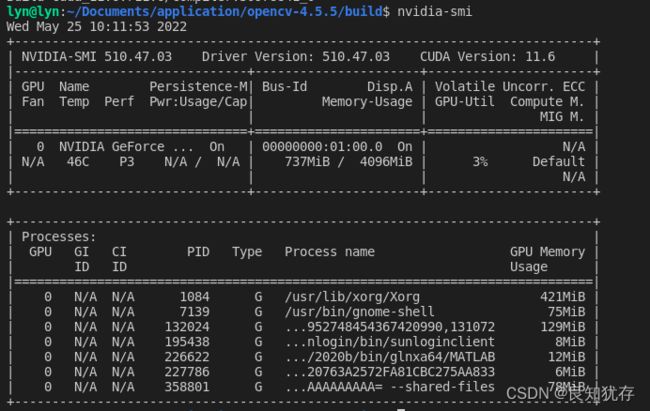
如果没有安装可以选择ubuntu的bash界面搜索附加驱动,然后进行安装。参考
当然由于ubuntu本身也有不同的版本支持,大家也可以直接到驱动的官网进行查找,里面有专门的ubuntu20适配版本选项,其中由于我使用的是ubuntu20,而CUDA11.0以上版本才支持Ubuntu20.04,所以直接就选择了最新的。
官方地址:https://developer.nvidia.com/cuda-toolkit-archive
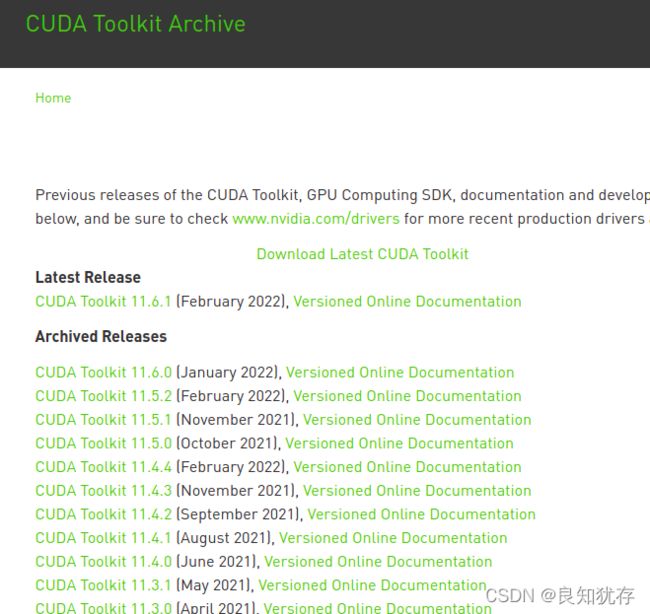
选择CUDA Toolkit 11.6.0之后,里面有几种选项,分别是本地deb安装、网络下载安装和可执行文件安装,我因为网络不太顺畅原因选择了第一个选项,最后下载下载下来的deb文件有2.7G,大家做好下载大文件的准备。
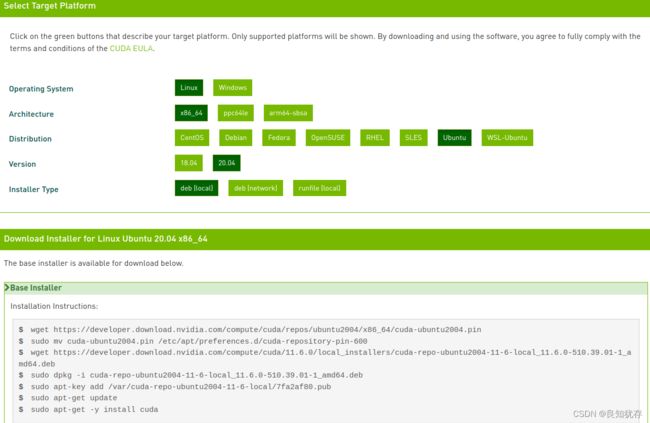
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.6.0/local_installers/cuda-repo-ubuntu2004-11-6-local_11.6.0-510.39.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-6-local_11.6.0-510.39.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-6-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
这时候cuda就安装好了,接下来就是使用了。
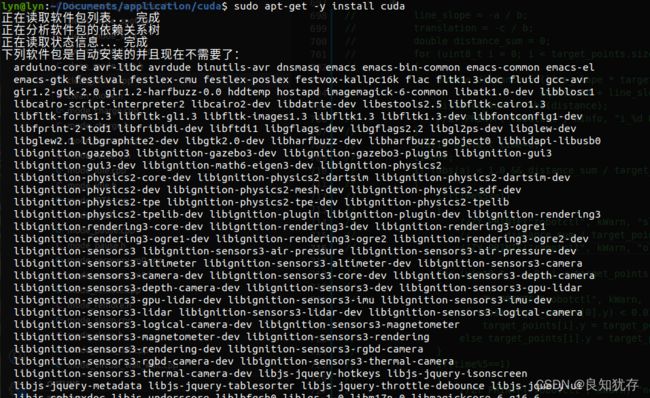
大家可以使用cuda命令,tab就可以出现对应的命令,或者使用nvcc编译对应的cuda的.cu文件进行验证。

大家可以通过以下链接里面的文档指导写符合自己需要的功能:
https://docs.nvidia.com/cuda/archive/11.6.0/cuda-c-programming-guide/index.html
下面官网API文件目录:
Versioned Online Documentation

官方示例:

接下来开始进行cuda的使用:输出hello world
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
using namespace std;
__global__ void kernel(void) { //带有了__global__这个标签,表示这个函数是在GPU上运行
printf("hello world gpu \n");
}
int main() {
kernel<<<1, 1>>>();//调用除了常规的参数之外,还增加了<<<>>>修饰,其中第一个1,代表线程格里只有一个线程块;第二个1,代表一个线程块里只有一个线程。
cudaError_t cudaStatus;
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
}
return 0;
}
这里面记得使用cudaDeviceSynchronize函数,等待GPU完成运算。如果不加的话,你将看不到printf的输出
编译选项 nvcc test_cuda_hello.cu
这个程序中GPU调用的函数和普通的C程序函数的区别
- 函数的调用除了常规的参数之外,还增加了<<<>>>修饰。
- 调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。
- 以线程格(Grid)的形式组织,每个 线程格 由若干个 线程块(block)组成,
- 而每个线程块又由若干个线程(thread)组成。
- 是以block为单位执行的。
接下来,我们再来使用一个demo,使用一个简单的计算,将其放置于GPU进行计算
// 输入变量 以指针方式传递===================================
#include
#include
#include
#include
// 输入变量 全部为指针 类似数据的引用
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c)
{
*d_c = *d_a + *d_b;
}
int main(void)
{
// CPU变量
int h_a,h_b, h_c;
// CPU 指针 变量 指向 GPU数据地址
int *d_a,*d_b,*d_c;
// 初始化CPU变量
h_a = 1;
h_b = 4;
// 分配GPU 变量内存
cudaMalloc((void**)&d_a, sizeof(int));
cudaMalloc((void**)&d_b, sizeof(int));
cudaMalloc((void**)&d_c, sizeof(int));
// 输入变量 CPU 拷贝到 GPU 右 到 左
cudaMemcpy(d_a, &h_a, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &h_b, sizeof(int), cudaMemcpyHostToDevice);
// 调用核函数
gpuAdd << <1, 1 >> > (d_a, d_b, d_c);
// 拷贝GPU数据结果 d_c 到 CPU变量
cudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("Passing Parameter by Reference Output: %d + %d = %d\n", h_a, h_b, h_c);
// 清理GPU内存 Free up memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
CUDA代码中比较重要的函数:
cudaMalloc
与C语言中的malloc函数一样,只是此函数在GPU的内存你分配内存。
addKernel<<<1, size>>>
这里就涉及了GPU和主机之间的内存交换了,cudaMalloc是在GPU的内存里开辟一片空间,
然后通过操作之后,这个内存里有了计算出来内容,再通过cudaMemcpy这个函数把内容从GPU复制出来。可以在设备代码中使用cudaMalloc()分配的指针进行设备内存读写操作;cudaMalloc()分配的指针传递给在设备上执行的函数;但是不可以在主机代码中使用cudaMalloc()分配的指针进行主机内存读写操作(即不能进行解引用)。
cudaFree
与c语言中的free()函数一样,只是此函数释放的是cudaMalloc()分配的内存。
cudaMemcpy
与c语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。此外与C中的memcpy()一样,以同步方式执行,即当函数返回时,复制操作就已经完成了,并且在输出缓冲区中包含了复制进去的内容。 相应的有个异步方式执行的函数cudaMemcpyAsync().
该函数第一个参数是目的指针,第二个参数是源指针,第三个参数是复制内存的大小,第四个参数告诉运行时源指针,这是一个什么类型的指针,即把内存从哪里复制到哪里。第四个参数可以选用以下的形式:参考
- cudaMemcpyHostToDevice:从主机复制到设备;
- cudaMemcpyDeviceToHost:从设备复制到主机;
- cudaMemcpyDeviceToDevice:从设备复制到设备;
- cudaMemcpyHostToHost:从主机复制到主机;
调用的核函数前面已经介绍过,此处不再赘述。还有其他函数大家可以自行参考官网的API介绍。
大家也可以看《GPU高性能编程CUDA实战》这本书
opencv中cuda库安装与使用
除了直接使用cuda,opencv也有相应的cuda的库,调用cuda从而在opencv实现gpu加速功能。这就需要安装CUDA,并从OpenCV编译安装时候安装好对应cv::cuda库。
首先要使用cv::cuda里面对应的cv::cuda::add 、cv::cuda::multiply,我们需要安装opencv要配合OpenCV Contrib库。
OpenCV Contrib库是非官方的第三方开发扩充库。通过这个库,我们能使用如dnn、相机标注、3D成像、ArUco、物体追踪,甚至是需付费的SURF、SIFT特征点提取算法
安装OpenCV Contrib也是需要和opencv进行版本匹配的。大家可以在下面位置进行对应版本下载:
- contrib库:https://github.com/opencv/opencv_contrib/tags
- opencv版本:https://opencv.org/releases.html
对与我个人而言,opencv版本是 4.4.5
$ pkg-config opencv4 --modversion
4.4.5
下载好对应的opencv和opencv_contrib库,开始进行编译,和之前单独opencv编译类似,解压下载好的文件,然后在opencv建立一个build目录,在里面进行cmake 编译。
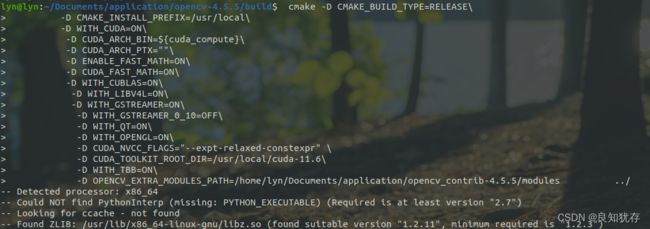
在这里给大家在注解一些相关选项的含义:
cmake -D CMAKE_BUILD_TYPE=Release\
-D ENABLE_CXX11=ON\
-D CMAKE_INSTALL_PREFIX=/usr/local\
-D WITH_CUDA=ON\
-D CUDA_ARCH_BIN=${cuda_compute}\
-D CUDA_ARCH_PTX=""\
-D ENABLE_FAST_MATH=ON\
-D CUDA_FAST_MATH=ON\
-D WITH_CUBLAS=ON\
-D WITH_LIBV4L=ON\
-D WITH_GSTREAMER=ON\
-D WITH_GSTREAMER_0_10=OFF\
-D WITH_QT=ON\
-D WITH_OPENGL=ON\
-D CUDA_NVCC_FLAGS="--expt-relaxed-constexpr" \
-D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-11.6\
-D WITH_TBB=ON\
-D OPENCV_EXTRA_MODULES_PATH=/home/lyn/Documents/application/opencv_contrib-4.5.5/modules ../
-
CUDA_ARCH_BIN=${cuda_compute} 显卡算力,大家可以对照我最后给算力查询自行查询,也可以进行系统自己查找匹配版本。
-
WITH_QT=ON\ 这是是QT的编译选项 大家可以按照自己需要选择是否用QT进行编译开与关。
-
CUDA_TOOLKIT_ROOT_DIR 这是自己电脑安装的cuda 版本
-
OPENCV_EXTRA_MODULES_PATH=/home/lyn/Documents/application/opencv_contrib-4.5.5/modules 这是解压好后的opencv_contrib目录
安装时候可能会遇到如下问题:
In file included from /home/lyn/Documents/application/opencv-4.5.5/build/modules/python_bindings_generator/pyopencv_custom_headers.h:7,
from /home/lyn/Documents/application/opencv-4.5.5/modules/python/src2/cv2.cpp:88:
/home/lyn/Documents/application/opencv_contrib-4.5.5/modules/phase_unwrapping/misc/python/pyopencv_phase_unwrapping.hpp:2:13: error: ‘phase_unwrapping’ in namespace ‘cv’ does not name a type
2 | typedef cv::phase_unwrapping::HistogramPhaseUnwrapping::Params HistogramPhaseUnwrapping_Params;

打开-D ENABLE_CXX11=ON 打开C++11的选项 (这就是上面命令使用C++11的原因)
最后编译成功:

sudo make install这个时候opencv中的cuda库就安装好了
介绍一个简单例子:
CMakeLists.txt文件
# 声明要求的 cmake 最低版本
cmake_minimum_required( VERSION 2.8 )
# 声明一个 cmake 工程
project(opencv_cuda)
# 设置编译模式
set( CMAKE_BUILD_TYPE "Debug" )
set( CMAKE_CXX_FLAGS "-std=c++11")
#添加OPENCV库
find_package(OpenCV REQUIRED)
#添加OpenCV头文件
include_directories(${OpenCV_INCLUDE_DIRS})
#显示OpenCV_INCLUDE_DIRS的值
message(${OpenCV_INCLUDE_DIRS})
add_executable(target test_cuda_cv.cpp)
# 将库文件链接到可执行程序上
target_link_libraries(target ${OpenCV_LIBS} )
test_cuda_cv.cpp文件
#include
#include "opencv2/opencv.hpp"
#include
#include
#include
int main (int argc, char* argv[])
{
//Read Two Images
cv::Mat h_img1 = cv::imread( "/home/lyn/Documents/work-data/test_code/opencv/learn_code/"
"opencv_tutorial_data-master/images/sp_noise.png");
cv::Mat h_img2 = cv::imread( "/home/lyn/Documents/work-data/test_code/opencv/learn_code/"
"opencv_tutorial_data-master/images/sp_noise.png");
// cv::Mat h_img2 = cv::imread("/home/lyn/Documents/work-data/test_code/opencv/learn_code/c++/build/filter_line.png");
// cv::namedWindow( "1", cv::WINDOW_FREERATIO);
// cv::imshow("1",h_img1);
// cv::namedWindow( "2", cv::WINDOW_FREERATIO);
// cv::imshow("2",h_img2);
cv::Mat h_result1;
#if 0
// cv::add(h_img1, h_img2,h_result1);//加法操作 api
cv::multiply(h_img1,cv::Scalar(2, 2, 2),h_result1);//乘法操作 api
#else
// 定义GPU数据
cv::cuda::GpuMat d_result1,d_img1, d_img2;
// CPU 到 GPU
d_img1.upload(h_img1);
d_img2.upload(h_img2);
// 调用GPU接执行 mat substract
// cv::cuda::add(d_img1, d_img2,d_result1);
cv::cuda::multiply(d_img1,cv::Scalar(2, 2, 2),d_result1);//乘法操作 api
// gpu 结果 到 cpu
d_result1.download(h_result1);
#endif
// 显示,保存
// cv::namedWindow( "Image1", cv::WINDOW_FREERATIO);
cv::imshow("Image1 ", h_img1);
// cv::namedWindow( "Image2", cv::WINDOW_FREERATIO);
cv::imshow("Image2 ", h_img2);
// cv::namedWindow( "Result_Subtraction", cv::WINDOW_FREERATIO);
cv::imshow("Result_Subtraction ", h_result1);
cv::imwrite("/home/lyn/Documents/work-data/test_code/opencv/learn_code/c++/result_add.png", h_result1);
cv::waitKey();
return 0;
}
大家也可以使用opencv中的其他cuda库,具体函数使用在下面
官方链接:https://docs.opencv.org/4.5.5/d1/d1e/group__cuda.html

大家可以在当前页面的版本选择中,选择和自己一致的opencv版本,进行参考:

例如我查询cv::cuda::add函数,就在 Operations on Matrices -> Per-element Operations
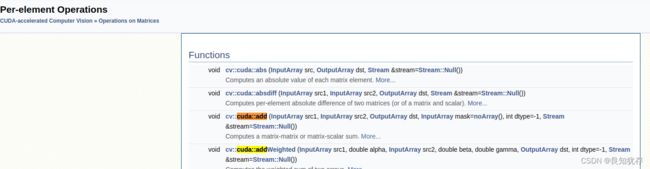
也可以看具体的数据结构含义:例如 cv::cuda::GpuMat
官方的解释是:具有引用计数的 GPU 内存的基本存储类。GpuMat类似于Mat,不过管理的是GPU内存,也就是显存。GpuMat和Mat相比,存在以下限制:
- 不支持任意尺寸(只支持2D,也就是二维数据)
- 没有返回对其数据的引用的函数(因为 GPU 上的引用对 CPU 无效)
- 不支持c++的模板技术。
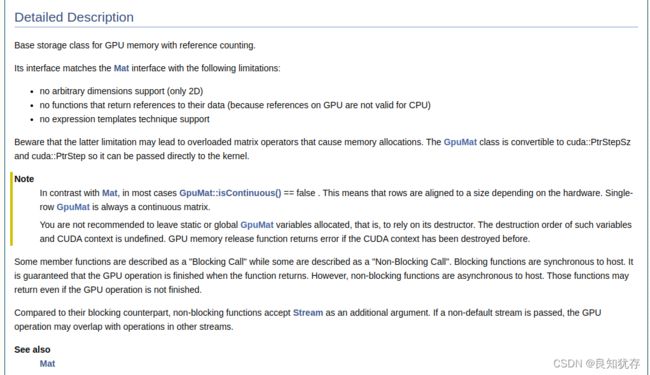
总之是很方便的,大家可以按照自己需要进行查询信息。
附录:这是官网提供算力表,大家可以参考选择自己的要求算力的显卡。
https://developer.nvidia.com/zh-cn/cuda-gpus

结语
这就是我自己的一些cuda的使用分享,因为篇幅所限,下一篇,我们聊聊cuda实际使用gpu加速和cpu使用的对比,以及它两使用场景分析。如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。
作者:良知犹存,白天努力工作,晚上原创公号号主。公众号内容除了技术还有些人生感悟,一个认真输出内容的职场老司机,也是一个技术之外丰富生活的人,摄影、音乐 and 篮球。关注我,与我一起同行。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
推荐阅读
【1】jetson nano开发使用的基础详细分享
【2】Linux开发coredump文件分析实战分享
【3】CPU中的程序是怎么运行起来的 必读
【4】cartographer环境建立以及建图测试
【5】设计模式之简单工厂模式、工厂模式、抽象工厂模式的对比
本公众号全部原创干货已整理成一个目录,回复[ 资源 ]即可获得。
