[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
SCNet:通过自我对比的背景原型增强Few-Shot语义分割
论文地址
摘要
大多数先进小样本分割都利用了度量学习框架,该框架通过将每个像素与学习到的前景原型进行匹配来进行分割。然而,只使用前景原型会导致分类偏倚。为了解决这一问题,本文在Few-Shot语义分割中引入了一种互补的自对比任务。我们的新模型能够关联每一个区域上的原型,无论这个区域是属于前景还是背景。为此,我们直接从查询图像中生成自我对比的背景原型,利用该原型构建完整的样本对,从而实现互补和辅助的分割任务,以实现更好的分割模型的训练。
存在的问题及解决方案
过往的工作通常的思路是利用支持特征产生更精细的原型来指导查询分割,例如PFENet。然而,这些方法由于其不完整的特征比较而限制了泛化能力。
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第1张图片](http://img.e-com-net.com/image/info8/c1f0d823afcd41f38e5cd40033a3955f.jpg)
在以前的工作中,只有前景原型是由支持图像生成的。因此,如图1所示,在以往方法的训练过程中,由于只有前景原型可用,因此将查询图像中的整个背景特征视为负样本。这将导致FSS的一个问题,因为一些新的类对象(测试集中的)可能会出现在基础训练集中,并在训练起见作为背景来处理。
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第2张图片](http://img.e-com-net.com/image/info8/728b5a4b811c45848ed9ae12ff9a00c3.jpg)
从图2中可以看到,新类(novel-class)对象在基类fold中的占比很高。例如,有23.5%的新类对象隐藏在PASCAL-5i的Fold-2的训练图像中。因此,在测试过程中,以前的方法往往简单地将新类对象“记住”为背景,这对于后续的分割指导显然是不利的。
我们解决这一问题的思路是在训练集中生成背景原型,从而构造完整的特征对进行比较,即额外构造背景原型的正对和负对,如图1所示。通过这种方式,我们可以减轻“记住”训练集中的新类对象作为背景的先验偏见。
此外,背景被定义为FSS中除了带注释的对象之外的任何区域。因此,很难保证支持图像背景与查询图像背景的语义相似。与之前的方法同样生成背景原型不同,我们提出仅从查询特征中提取背景原型,以确保预测时背景原型与背景特征之间的相似性。即以自我对比的方式对查询特征进行比较。
方法
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第3张图片](http://img.e-com-net.com/image/info8/da31408af91d446890051b907c14be29.jpg)
具体来说,我们提出的SCNet的管道如图3所示。它由两个并行分支组成,类特定(class-specific)的分支和类不可知(class-agnostic)的分支。每个分支有两个子模块,原型生成和特征对齐。与其他双分支方法不同的是,我们的两个分支同时学习前景和背景原型的特征比较。类特定分支在前景特征和查询特征之间进行学习,其目标是对查询图像中的前景区域进行分割。类不可知分支在查询特征之间进行学习,它鼓励背景原型拉出背景特征,而推开前景特征。为了进一步生成更精细的背景原型,我们使用kmeans聚类算法对整个查询特征图进行分组,并以自我对比的方式引导特征比较。
Learning to Compare between Support-Query Pair
前景原型 p s p^s ps由掩码平均池化(mask average
pooling (MAP))生成:

我们首先将 p s p^s ps扩展为与查询特征 F q F^q Fq相同的形状,然后在通道维度上将它们连接起来:
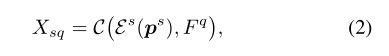
其中 E \mathcal{E} E表示扩展操作, C \mathcal{C} C表示连接操作。为了获得更好的查询图像 I q I^q Iq的掩码,我们遵循以前的工作(CANet),使用卷积模块 g ϕ g_{\phi} gϕ来编码融合的特征 X s q X_{sq} Xsq:
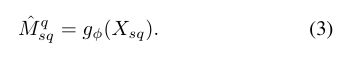
这里, g ϕ g_{\phi} gϕ二值分类的方式进行像素级特征比较,它验证特征图 F q F^q Fq中的像素是否与 E s ( p s ) \mathcal{E}^{s}\left(p^{s}\right) Es(ps)中相应位置的原型相匹配。
Learning to Compare in Query Image
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第4张图片](http://img.e-com-net.com/image/info8/8fb9ff5576584b5f9a30f44b3114065a.jpg)
与支持图像为特定类提供掩码注释的类特定分支不同,我们的类不可知分支从查询特征 F q F^q Fq中进行自我学习,因为查询图像的背景区域不包含任何注释。如图4所示,为了获得查询图像的背景原型,我们首先在特征级别上使用k-means聚类将其划分为 n n n个区域(如3个区域)。然后,使用MAP生成这些区域的原型 { p i q , i = 1 , 2 , ⋯ , n } \left\{\boldsymbol{p}_{i}^{q}, i=1,2, \cdots, n\right\} {piq,i=1,2,⋯,n}。然后使用 g ϕ g_{\phi} gϕ进行特征比较,在这个区域,监督 g ϕ g_{\phi} gϕ的ground-truth是覆盖背景区域的掩码"1"。对于聚类区域之外的区域,也就是前景区域,给它分配相应的前景原型会得到一个trivial的解决方案,即一个全"1"的掩码。
我们随机选择一个背景原型作为前景区域,如图4(b)中的白色正方形所示。
Background Prototypes Generation
特定类的分支提取具有支持特征映射的原型,并将其与查询特征进行比较,因为在支持和查询图像中都有相同类的对象。但是,很难保证在支持-查询对背景中存在相似的语义。因此,直接用查询特征来估计背景原型更为合适。为此,一种简单的方法是直接在查询特征的背景区域上应用全局掩码平均池化来获得其背景原型。但是由于背景通常比前景更加多样化,所以简单的掩码平均池化实际上是无效的。为了解决这一问题,我们提出根据查询特征在特征空间中的语义分布对查询特征进行空间划分。
众所周知,高级语义特征通常是由网络的更深层提取出来的。因此,我们不使用来自中间层的特征 F q F^q Fq,而是使用更高级的特征 F ˉ q \bar{F}^{q} Fˉq来分组 F q F^q Fq的背景。为了将 F ˉ q \bar{F}^{q} Fˉq划分成 n n n个区域,我们使用经典的k-means聚类,优化问题可以被表示为:
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第5张图片](http://img.e-com-net.com/image/info8/962f8985707e49af9a9f024c92ad69b8.jpg)
其中dist(·)表示标准余弦距离, r i k ∈ { 0 , 1 } r_{i k} \in\{0,1\} rik∈{0,1}是一个二元指示变量, F ‾ i q ∈ F ˉ q \overline{\boldsymbol{F}}_{i}^{q} \in \bar{F}^{q} Fiq∈Fˉq, u k u_k uk表示第 k k k个聚类的中心,最优的 r i k ∗ r_{ik}^* rik∗和 u k ∗ u_{k}^* uk∗通过迭代优化得到。
使用 r i k ∗ r_{ik}^* rik∗可以很容易地得到 F q F_q Fq的第 k k k个聚类区域的背景原型。首先重构第 k k k个二值指示向量 { r i k } i = 1 h w ∈ R h w \left\{r_{i k}\right\}_{i=1}^{h w} \in \mathbf{R}^{h w} {rik}i=1hw∈Rhw成 M ˉ k q ∈ R h × w \bar{M}_{k}^{q} \in \mathbf{R}^{h \times w} Mˉkq∈Rh×w。因此, M ˉ k q \bar{M}_{k}^{q} Mˉkq表示哪些空间位置属于第 k k k个聚类,这些位置等于1,其他位置为零。注意 M ˉ k q \bar{M}_{k}^{q} Mˉkq可能会包含前景,所以我们检查 M ˉ k q \bar{M}_{k}^{q} Mˉkq和前景掩码 M q M^q Mq之间的交集来更新 M ˉ k q \bar{M}_{k}^{q} Mˉkq:
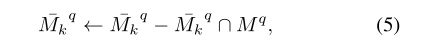
最后使用MAP来生成原型:

Feature Alignment for Complete Comparison
类特定分支只鼓励前景特征相互靠近,而远离查询图像的背景特征。如前面所讨论的那样,这种学习方法容易迫使模型在训练过程中"记住"除基类外的类都是背景类,限制了模型的泛化能力。因此,在我们的工作中,我们使用完整的特征比较来缓解这个问题。
首先,将每个原型 p k q p_k^q pkq进行扩展来填充 M ˉ i , j , k q \bar{M}_{i, j, k}^{q} Mˉi,j,kq值为1的相应位置。然后将所有展开的原型 p k q ( k = 1 , 2 , ⋯ , n ) \boldsymbol{p}_{k}^{q}(k=1,2, \cdots, n) pkq(k=1,2,⋯,n)和它们对应的查询特征进行连接:
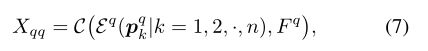
通过这种方法,我们实现了对每个背景原型的正对构造。同时,为了构造负对,我们从所有背景原型中随机选择一个负对,并将其与查询图像中前景特征的每个位置密集配对。
我们将上述对所有背景原型的展开操作记为 E q ( ⋅ ) \mathcal{E}^{q}(\cdot) Eq(⋅):
![]()
最后,用卷积模块 g ϕ g_{\phi} gϕ编码 X q q X_{qq} Xqq,学习更好的比较度量。
Learning to Completely Compare
无论是 X s q X_{sq} Xsq还是 X q q X_{qq} Xqq,它们的共同特点是前景与背景的特征比较。合理的做法是,如果这些比较是在相同的语义上(即前景类或背景聚类),模型应该在这些位置输出预测1,否则输出预测0。也就是说,对于类特定的分支,它的目标标签应该是查询映像的掩码 M q M^q Mq,而对于类不可知的分支,它的目标标签应该是 1 − M q 1−M^q 1−Mq。因此,我们使用交叉熵损失,并将整体损失函数公式为:

实验结果
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第6张图片](http://img.e-com-net.com/image/info8/c059fb8a9d6d4703a1900c3f5401281e.jpg)
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第7张图片](http://img.e-com-net.com/image/info8/cf24cae83fb7438880f0668389f69a25.jpg)
![[小样本图像分割]SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes_第8张图片](http://img.e-com-net.com/image/info8/1a2a5e274368402da091fd797414f20a.jpg)
总结
本文将互补特征比较嵌入基于度量的Few-Shot语义分割(FSS)框架中,以提高FSS的性能。具体来说,不同于以往的工作只是单方面地利用提取的前景对象原型来预测前景掩模,我们提出计算背景原型并构造互补样本对,这使我们能够与双分支网络架构进行互补特征比较,即特定于类和不确定类的分支。为了在预测时保证原型与背景特征之间的相似性,我们建议单独从查询特征中提取背景原型,并以自我对比的方式进行特征比较。