Java基础之刨根问底第4集——原始数据类型
原文转自我自己的个人公众号:https://mp.weixin.qq.com/s/lMRG115HoWVKP0Acxu5kVw(由于是拷贝过来的,如果排版有问题,请看公众号文章)
-
本系列不适合初学者,读者应具备一定的Java基础。
-
考虑到目前行业中使用最广的版本,本系列依据Java8编写。
原始数据类型
Java的数据类型实际上可以分成两个维度,一个是语言规范中的数据类型,另一个是JVM的数据类型。语言中的数据类型最终都会编译成预期对应的一个JVM数据类型。如下图所示:

在Java语言规范中,共有8种原生数据类型,如上图所示,其中boolean类型在JVM中是没有的,编译后,boolean会作为int来交给JVM处理,如果是boolean型的数组,编译时会作为byte数组进行处理,在处理时,true用1表示,false用0表示(程序语言通常按照非零即真的原则设计)。
JVM中还有一个语言层面没有的原始数据类型——returnAddress,这个类型在“Java基础之刨根问底第1集——JVM的结构”中介绍过,该类型的数据用来表示当前执行的JVM指令的位置。
下面来详细看看每个数据类型的特点。可以将上面的八种原生数据类型分为两组:整型类型和浮点型类型。
-
整型类型
1. byte
byte在内存中占8位,是一个有符号的二进制补码整数。8位意味着每个byte占1个字节,有符号则表示这个字节中的第一位是符号位——0表示正数,1表示负数。二进制补码则是则是在计算机中的表示方法,补码意味着可以将减法当作加法来计算,提高了运算效率。
简单介绍下补码的运算规则。正数的补码和原码是一样的,负数的补码是在原码的基础上取反(符号位不取反)后加一。例如:9的二进制原码是00001001,补码也是00001001,-5的源码是10000101(第一位是1表示负数),补码则是11111011。这样一来,9-5就变为了9+(-5补码),结果就是100000100 ,注意:相加后左侧最高位溢出了,变成了9位,去掉溢出的位后结果是00000100,这个结果依然是补码,不过因为最高位的符号位是0,表示是正数,因此原码和补码一样,00000100的十进制就是4,因此得出9-5=4。
总共8位,最高位用于符号位后,剩余的七位二进制可以表示的范围是-128(-2的七次方)到127(2的七次方-1)。
2. short
与byte的不同点在于,short用16位表示,也就是在内存中占两个字节,因此short的范围是-32768到32767。
3. int
int的范围比short更大,用32位表示,占4个字节,范围是-2的31次方到2的31次方-1。
需要注意的是,从Java8开始,可以使用int的包装器类型Integer来声明一个无符号的int型,范围则是0到2的32次方-1。
4. long
long的范围就更大了,用64位标识,占8个字节,范围是-2的63次方到2的63次方-1。
和int一样,long的包装器类型Long也可以声明无符号的long,范围是2的64次方-1。
5. char
char的范围是\u0000(十进制的0)到\uffff(十进制的65535)。因为char是无符号的,用16位表示,因此理论上也可以作为short的无符号型来用(如下图所示),不过不建议这样用,因为在语义上会有歧义。

6. boolean
虽然在JVM中,是用int型来处理boolean的,但在语言规范上,并不能向char那样用整型赋值,只能使用true或者false。
-
浮点型类型
1. float
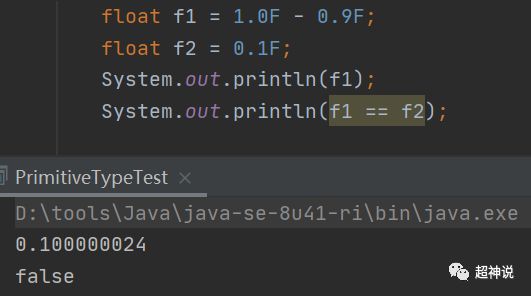
float用于存储有小数的值,用32位标识,占4个字节,Java语言中的浮点数遵循IEEE 754标准,该标准定义了在计算机中如何表示浮点数,我看了下,太学术了,有兴趣的朋友可以自行查看该标准。虽然float用于存储小数,但当需要非常精确的计算时(例如与钱有关的计算)是不能用的。
下面举一个float丢失精度的例子:
2. double
double用64位标识,占8个字节,精度要比float高一些,同样遵循IEEE 754标准。与float一样的是,也不能用于精确计算(例如与钱有关的计算)。
还是float中的例子,换成double后如下所示:
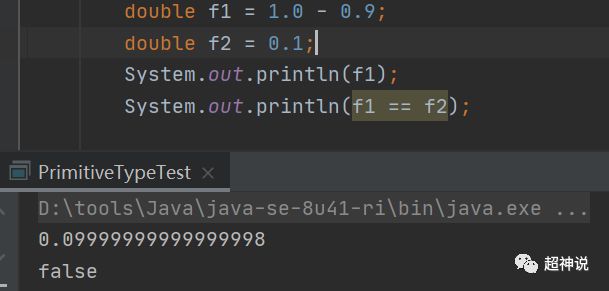
小数点的位数是多了,说明double的精度确实比float高,但依然不够精确。
不知道有没有人发现,在float的例子中,我在数字后面加了F后缀,而double中并没有任何后缀。这是因为Java默认使用的是double类型,因此声明一个小数,默认就是double类型的。当然,double类型可以用D后缀显式的标记。类似的是,Java默认的整形是int,如果要声明long型的,可以加后缀L。这里要注意的一点是,虽然我用大写字母的后缀,但小写的也是一样的,不过,建议使用大写的形式,因为小写的l和1比较像,容易混淆。
如果需要精确的计算,应使用BigDecimal,如下所示:

精度进一步增加了,但依然不够精确,难道BigDecimal也不行吗?其实是可以的,这里不行的原因是因为在构造函数中是用double型的1.0来创建BigDecimal对象的,double类型本身就是有精度丢失的,因此需要用字符串来构建,如下图所示:
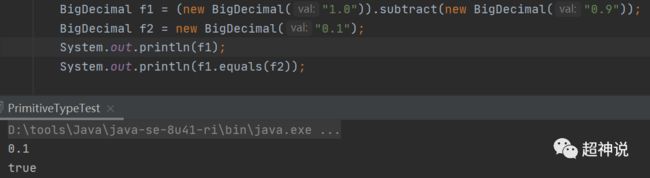
这样就OK了。结论:浮点型的表示和计算都是有精度丢失的,float的精度低,double的精度高,但都不能用于精确计算(如与钱相关的),如果要精确的计算,一定要使用字符串类型的数字来构造BigDecimal对象。
以上就是java语言中的8种原始类型的介绍。
下面进一步看一下一些更细节的点:
-
默认值
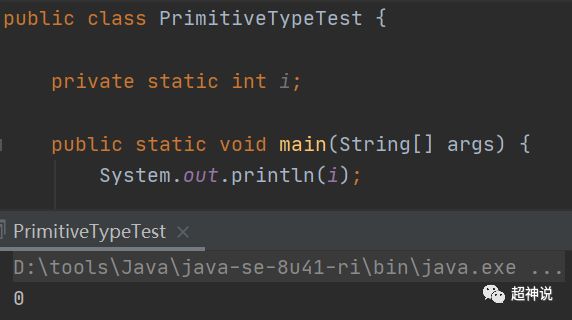
在上面的介绍中,每个类型都有默认值,也就是说如果声明的时候不设置初始值,就会使用默认值。看看下面的例子:
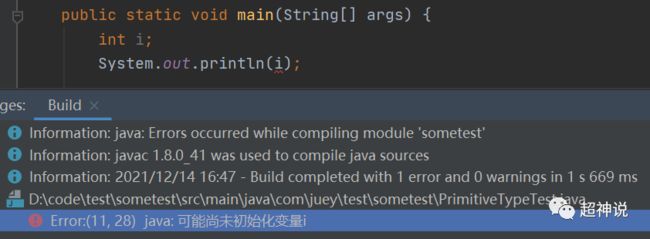
竟然报错了!不是有默认值吗?为什么这里会报错?实际上,默认值只对类的字段(Field)有效,对于方法中的变量是无效的。至于原因,回想一下在“Java基础之刨根问底第1集——JVM的结构”中,分析变量的存储位置时,类字段(Field)是存在运行时常量池中的,而方法中的变量则会存入本地变量表中。在类初始化的时候,运行时常量池就被初始化了,也是在这个时候,默认值被设置上去,而本地变量表中的变量只有在使用的时候才会被push到操作数栈中,这也使得编译器没有机会为本地变量设置默认值。
将上面的例子应用到类字段(Field)中,默认值就会生效了,如下:
-
同样是整形和浮点型,为什么又细分为多个?
在介绍8种原始数据类型的时候,分为了整型和浮点型两类,整型中细分为byte、short、int、long、char、boolean,浮点型细分为float和double。这样细分的目的在于两点:
-
节省内存:每个细分类型所占用的位数是不同的,因此在数据量很大的时候使用合适的类型会很好的节约内存。
-
增加可读性:每个细分类型的取值范围不同,因此可以隐含的告诉开发人员变量的约束。
下面我测试了一下不同类型的内存占用情况,测试代码如下所示:
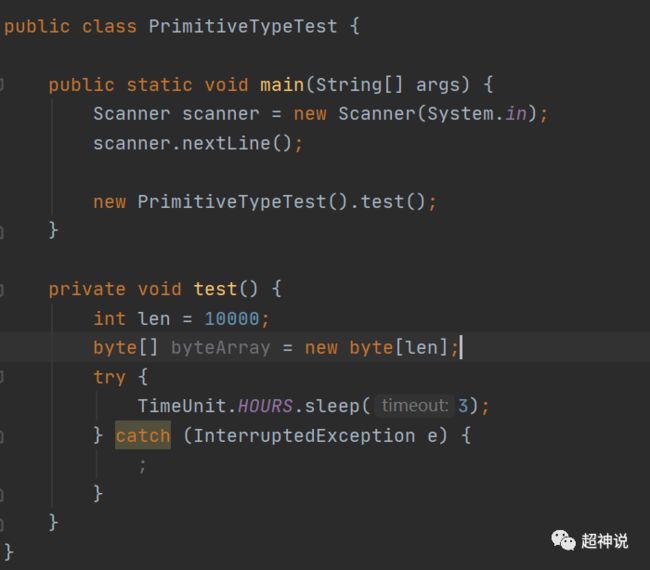
代码比较简单,测试的思路是这样的:首先程序运行后,因为Scanner的存在,会需要人为的在命令行中输入任意字符,才会继续调用test方法。在输入任意字符前,用jmap -histo来查看目前程序中各个对象的内存占用情况,然后输入字符让程序执行test方法,在test方法中声明和初始化了一个长度是10000的byte数组,然后休眠3小时,这时候再用jmap -histo查看对象的内存占用情况,然后进行对比。结果如下所示:
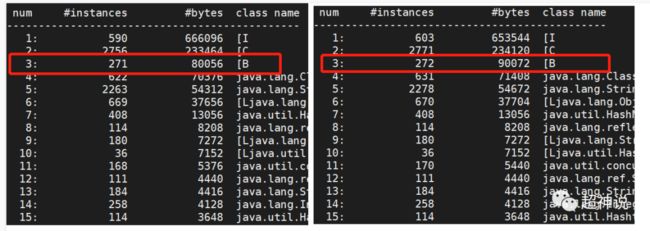
上图中左边是第一次执行jmap的结果,右边是第二次的结果,第3行标红的[B,表示byte型数组。对比后可以看出,创建数组前,byte数组的实例有271个,占用80056字节,执行test创建数组后,实例变为了272,增长了1个,占用字节数变为90072。增长的这一个就是我们程序中的长度10000的byte数组,(90072-80056)/10000=1.0016,这就验证了byte占1个字节(8位)。
解释一下为什么是1.00016而不是1,我尝试将数组长度从1开始一直向上增加,发现,数组初始化时,内存空间并不是和数组长度一一对应的,而是会先申请一个整块的内存,例如,在我测试byte数组时,数组长度从1到8,都是占24个字节,然后随着长度的增加,达到一个阈值时就会再申请8个字节。所以实际情况应该是(90072-80056-预先申请的)/10000=1。
这里的1万个byte的数组占10kb,换成double数组后,如下图所示:

double数组在上图中的class name是[D,可以看到左边是没有的,执行test方法后,才会出现1个[D,就是我们程序中的double数组。占的字节数是80016,每个double占8个字节(64位),相比1万个byte占据的10kb,这里的80kb就大出许多了。
-
使用下划线来分割数字
从Java7开始,可以在数字中加入下划线来增加可读性,下面是官方文档中给出的一些列子:
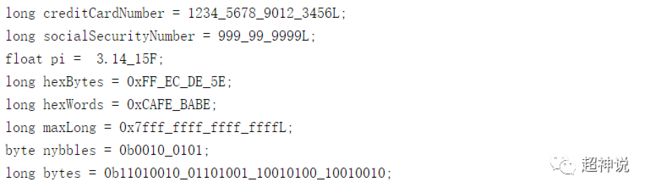
不能在以下位置使用下划线:
1.数字的开始或末尾
2.小数点两侧
3.F、L等后缀前面
4.数字中的字符中(例如0_x52就是错误的)
-
原始类型和对应的包装类
Java中的每个原始类型都有与之对应的一个包装类,下面是每个类型和包装类的对应关系:

那么原始类型和包装类型有什么区别呢?
在介绍int的时候,已经讲过int不支持无符号型,而Integer可以支持无符号的相关操作。所以说,包装类通常会扩展一些原始类型的能力。
在使用上,大部分情况原始类型和包装类可以互相赋值,这依赖于Java的自动装箱(Boxing)和自动拆箱(Unboxing)功能。在将原始类型赋值于包装类时会自动装箱,用原始类型的值构建对应的包装类;相反,将包装类型赋值给原始类型时,会调用包装类的xxValue方法(如果是Byte就是byteValue())。
原始类型和包装类在使用上最大的区别我觉得应该是原始类型一定要赋值(没有赋值的类字段(Field)因为编译器会设置默认值所以相当于是赋值了),而包装类则可以为null。
以上就是本集的全部内容。