【Python】Python时间序列预测 | 经典季节性分解
今天给大家分享一种方法,,时间序列预测之seasonal_decompose使用移动平均线对时间序列数据进行季节性分解,Python实现和原理介绍。这是我在学习时间序列异常检测时遇到的一个问题,通过收集资料并整理出一文,希望能对大家有所帮助!
![]()
原理介绍
![]()
季节性分解原理
所谓分解就是将时序数据分离成不同的成分,分解有:长期趋势Trend、季节性Seasonality和随机残差Residuals。
季节性分解是将时间序列抽象分解为系统和非系统组件。
系统组件 :具有一致性或重复性的时间序列的组成部分,可以进行描述和建模。
非系统组件 :无法直接建模的时间序列的组成部分。
给定的时间序列被认为包括三个系统组件,包括等级,趋势,季节性和一个称为噪声的非系统组件。
这些组件定义如下:
等级Level:时间序列中的平均值。
趋势Trend:时间序列中的增加或减少值。
季节性Seasonality:时间序列中重复的短期周期。
随机残差Residuals :时间序列中的随机变化。
decompose数据分解模型主要有两类:相加模型additive和相乘模型multiplicative。
官方解释是:
相加模型
相乘模型
其中,是均值项, 是趋势项,是季节性周期项,是残值项。一般的,理想的分解模型中残值项应该是一个均值为0的随机变量。
两种模型的分解思路一致,首先通过对数据应用卷积滤波器去除季节性成分。每个时期的平滑序列的平均值就是返回的季节性成分。
这里以相加模型(additive)为例介绍。
STEP1分解趋势项,采用中心化移动均值的方法
当 为奇数时:
当 为偶数时:
其中 为趋势项, 为时间序列频率, 为时间序列长度。结果为长度为 的时间序列,为便于后续的向量计算,当超过上述下标的定义域时,其值,如
STEP2分解季节性周期项
采用原始时间序列减去趋势项
将各个周期内相同频率下的值平均化,得到季节项
figure
将
figure中心化,得到中心化的季节项figure,代码可表述为
STEP3 计算残差项
函数解析
statsmodels.tsa.seasonal.seasonal_decompose(
x,model = ‘additive‘,
filt = None,period = None,two_side = True,
extrapolate_trend = 0)参数:
x:array_like,被分解的数据。model:{“additive”, “multiplicative”}, optional
"additive"(加法模型)和"multiplicative"(乘法模型)
fil:tarray_like, optional
用于滤除季节性成分的滤除系数。滤波中使用的具体移动平均法由two_side确定。
period:int, optional系列的时期。
如果x不是pandas对象或x的索引没有频率,则必须使用。
如果x是具有时间序列索引的pandas对象,则覆盖x的默认周期性。
two_sided:bool, optional滤波中使用的移动平均法。
如果为True(默认),则使用filt计算居中的移动平均线。
如果为False,则滤波器系数仅用于过去的值。
extrapolate_trend:int or ‘freq’, optional
如果设置为> 0,则考虑到许多(+1)最接近的点,由卷积产生的趋势将在两端外推线性最小二乘法(如果two_side为False,则为单一个最小二乘)。
如果设置为“频率”,请使用频率最近点。设置此参数将导致趋势或残油成分中没有NaN值。
三种方法获取三个值。
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid![]()
举例说明
![]()
生成数据
import numpy as np
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.randint(1, 10,
size=(365, 1)),
columns=['value'],
index=pd.date_range('2021-01-01',
periods=365, freq='D'))乘法序列分解
乘法法序列 = Level * Trend * Seasonality * Error
result_mul = seasonal_decompose(df['value'],
model='multiplicative',
extrapolate_trend='freq')
plt.rcParams.update({'figure.figsize': (10, 10)})
result_mul.plot().suptitle('Multiplicative Decompose')
plt.show()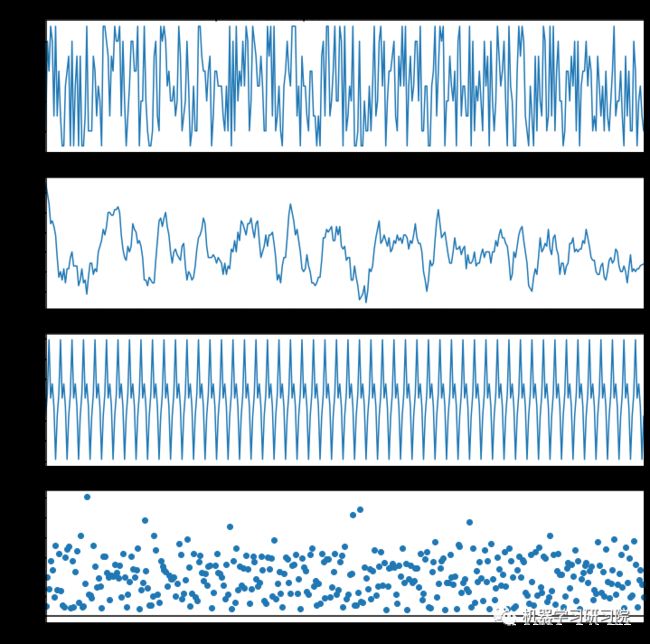
加法序列分解
加法序列 = Level + Trend + Seasonality + Error
result_add = seasonal_decompose(df['value'],
model='additive',
extrapolate_trend='freq')
plt.rcParams.update({'figure.figsize': (10, 10)})
result_add.plot().suptitle('Additive Decompose')
plt.show()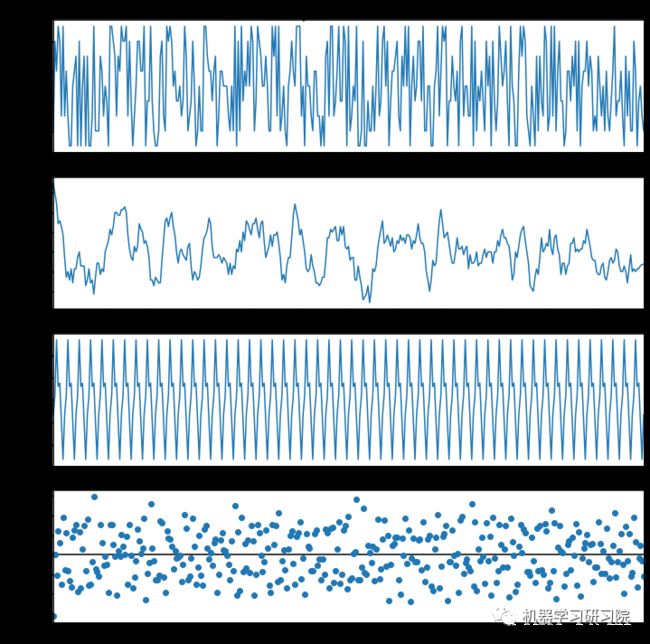
季节性分解工具的说明
季节性分解是一中工具,分解主要用于时间序列分析,作为分析工具,它可用于为问题提供预测模型。
它提供了一种思考时间序列预测问题的结构化方法,通常在建模复杂性方面,特别是在如何最佳地捕获给定模型中的每个组件方面。
在数据准备,模型选择和模型调整期间,可能需要考虑和解决每一个组件。可以在对趋势进行建模并从数据中减去趋势时明确地解决它,或者通过为算法提供足够的历史记录来隐式地解决趋势(如果趋势可能存在)。
季节性分解中加法模型或乘法模型均可能会或可能无法将的特定时间序列干净或完美地分解。因为现实世界的问题是混乱和嘈杂的。可能存在加法和乘法组件。可能会出现增长趋势,随后呈下降趋势。可能存在与重复季节性成分混合的非重复循环。
应用案例
在时间序列异常检测中,定义了这么一个函数,用于季节性检测,并输出最佳趋势,即用线性回归拟合最好的那个趋势线。
def check_seasonality(self, x, probable_periods):
"""
季节性检测
:param x:
:param probable_periods:
:return:
"""
# 先做个线性回归
series_r2, slope, reg_line = self.do_linear_regression(x)
best_r2 = series_r2
seasonality = False
best_trend = 0
for model_type in ['additive', 'multiplicative']:
# 乘法序列 = Trend * Seasonality * Error
# 加法序列 = Trend + Seasonality + Error
for period in probable_periods:
if not (2 * period > len(x.index)):
result = seasonal_decompose(pd.DataFrame(x.values, columns=['value']), model=model_type,
freq=period)
trend = result.trend.copy()
trend.dropna(inplace=True)
# 做个线性回归,拟合斜率
trend_r2, trend_slope, reg_trend_line = self.do_linear_regression(trend)
# 选择r2最大的那个趋势,作为最佳趋势
if trend_r2 > best_r2:
best_r2 = trend_r2
seasonality = True
best_trend = result.trend
return seasonality, best_trend参考资料
[1]https://blog.csdn.net/weixin_35757704/article/details/113039882
[2]https://www.jianshu.com/p/e2cc90e1c32d
[3]https://machinelearningmastery.com/decompose-time-series-data-trend-seasonality/

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群554839127,加入微信群请扫码:
