【ML on Kubernetes】第 7 章:模型部署和自动化
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
使用 Seldon Core 理解模型推理
使用 Python 包装模型
将模型容器化
使用 Seldon 控制器部署模型
使用 Seldon Core 打包、运行和监控模型
介绍 Apache Airflow
了解DAY
探索 Airflow功能
了解 Airflow组件
验证 Airflow 安装
配置 Airflow DAG 存储库
配置 Airflow 运行时映像
在 Airflow 中自动化 ML 模型部署
使用管道编辑器创建管道
概括
在上一章中,您看到了该平台如何使您能够以自主方式构建和注册模型。在本章中,我们将扩展机器学习( ML ) 工程领域,以对部署活动的部署、监控和自动化进行建模。
您将了解该平台如何提供模型打包和部署功能,以及如何实现它们的自动化。您将从注册表中获取模型,将其打包为容器,并将模型部署到平台上以作为 API 使用。然后,您将使用平台提供的工作流引擎自动执行所有这些步骤。
部署模型后,它就可以很好地用于训练它的数据。然而,现实世界发生了变化。您将看到该平台如何让您观察模型的性能。本章讨论监控模型性能的工具和技术。性能数据可用于决定模型是否需要在新数据集上重新训练,或者是否是时候为给定问题构建新模型了。
在本章中,您将了解以下主题:
- 使用 Seldon Core 理解模型推理
- 使用 Seldon Core 打包、运行和监控模型
- 了解 Apache Airflow
- 在 Airflow 中自动化 ML 模型部署
技术要求
本章包括一些动手设置和练习。您将需要一个使用Operator Lifecycle Manager配置的正在运行的 Kubernetes 集群。第 3 章“探索 Kubernetes”中介绍了构建这样的 Kubernetes 环境。在尝试本章中的技术练习之前,请确保您有一个正常工作的 Kubernetes 集群,并且在您的 Kubernetes 集群上安装了开放数据中心( ODH )。第 4 章“机器学习平台剖析”中介绍了 ODH 的安装。
使用 Seldon Core 理解模型推理
在里面以前的章,你建立了模型。这些模型由数据科学团队构建,用于生产并服务于预测请求。在生产中使用模型的方法有很多,例如将模型嵌入到面向客户的程序中,但最常见的方法是将模型公开为 REST API。然后,任何应用程序都可以使用 REST API。一般来说,在生产环境中运行和服务模型是称为模型服务。
但是,一旦模型投入生产,就需要对其性能进行监控,并且需要进行更新以满足预期标准。托管模型解决方案使您不仅可以为模型提供服务,还可以监控其性能并生成可用于触发模型重新训练的警报。
Seldon 是一家总部位于英国的公司,它创建了一套工具来管理模型的生命周期。Seldon Core 是一个开源框架,有助于公开 ML 模型以作为 REST API 使用。Seldon Core 自动公开 REST API 的监控统计信息,平台的监控组件Prometheus可以使用这些统计信息。要将您的模型公开为平台中的 REST API,需要执行以下步骤:
- 为您的模型编写一个特定于语言的包装器以作为服务公开。
- 将您的模型容器化。
- 定义和使用 Kubernetes中的 Seldon 部署自定义资源( CR )使用模型的推理图部署模型
接下来,我们将详细了解这三个步骤。
使用 Python 包装模型
让我们来看看如何您可以应用前面的步骤。在第 6 章,机器学习工程中,您向 MLflow 服务器注册了实验详细信息和模型。回想一下,模型文件存储在 MLflow 的工件中并命名为model.pkl。
让我们获取模型文件并围绕它编写一个简单的 Python 包装器。包装器的工作是使用 Seldon 库将模型方便地公开为 REST 服务。您可以在chapter7/model_deploy_pipeline/model_build_push/Predictor.py的代码中找到包装器的示例。这个包装器的关键组件是一个名为predict的函数,该函数将从 Seldon 框架创建的 HTTP 端点调用。图 7.1显示了一个简单的Python使用joblib模型的包装器:
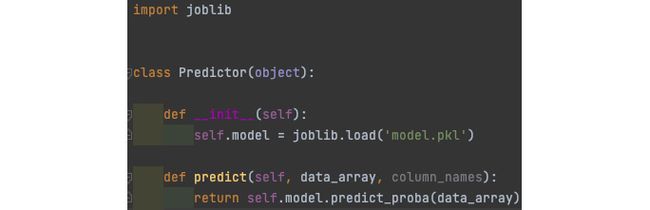
图 7.1 – 模型预测的 Python 语言包装器
predict函数接收从 HTTP 请求序列化的numpy数组( data_array ) 和一组列名 ( column_names )。该方法以numpy数组或值或字节列表的形式返回预测结果。语言包装器还有更多可用的方法,完整列表可在Seldon Python Component — seldon-core documentation获得. 请注意,在本书后面的章节中,您将看到一个更全面的推理示例,该示例将在预测之前为数据转换提供额外的包装器。但是,对于这一章,我们尽量保持简单。
语言包装器已经准备好,下一阶段是容器化模型和语言包装器。
将模型容器化
你会怎么放入容器中?让我们从一个列表开始。您将需要模型和包装文件。您将需要容器中可用的 Seldon Python 包。拥有所有这些包后,您将使用 Seldon 服务来公开模型。图 7.2显示了一个Docker文件,它正在构建一个这样的容器。该文件在第 7 章/model_deployment_pipeline/model_build_push/Dockerfile.py中可用。
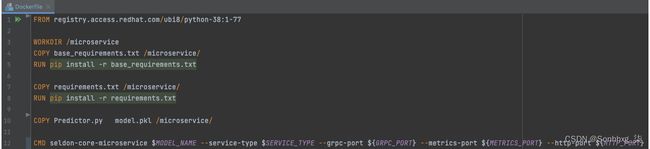
图 7.2 – 将模型打包为容器的 Docker 文件
现在,让我们了解一下 Docker 文件的内容:
- 第 1 行表示模型服务的基本容器映像。我们选择了 Red Hat 提供的免费映像,但您可以根据自己的方便进行选择。此映像可以是您组织的基础映像,其中包含标准版本的 Python 和相关软件。
- 在第 3 行中,我们创建了一个微服务目录来将所有相关的工件放置在我们的容器中。
- 在第 4 行,我们需要构建容器的第一个文件是base_requirements.txt。该文件包含 Seldon Core 系统的包和依赖项。你可以在chapter7/model_deployment_pipeline/model_build_push/base_requirements.txt找到这个文件。在此文件中,您将看到 Seldon Core 包和joblib包已被添加。
图 7.3显示了base_requirements.txt文件:

图 7.3 – 将 Seldon 和 Joblib 添加到容器的文件
- 第 5 行使用base_requirements.txt文件将 Python 包安装到容器中。
- 在第 7 行和第 8行中,当您训练模型时,您可能会使用不同的包。在推理过程中,可能需要一些包;例如,如果您在使用库进行模型训练之前已完成输入数据缩放,则可能需要相同的库在推理时应用缩放。
在第 6 章,机器学习工程中,您注册了实验细节和模型。与 MLflow 服务器。回想一下,模型文件与包含用于训练名为requirements.txt的模型的包的文件一起存储在工件中。使用 MLflow 生成的requirements.txt文件,您可以安装运行模型所需的包,或者您可以选择自行将这些依赖项添加到自定义文件中。图 7.4显示了第 6 章机器学习工程中提到的 MLflow 快照。您可以在model.pkl文件旁边看到requirements.txt文件。

图 7.4 – MLflow 运行工件
第 10 行:添加语言包装文件和模型文件到容器。
第 11 行:在这里,您正在使用seldon-core-microservice服务器来启动推理服务器。请注意,这里已经传递了参数,在下一节中,您将看到我们如何传递这些参数:
- MODEL_NAME:这是包含模型的语言包装器中 Python 类的名称。
- SERVICE_TYPE:此参数包含在推理管道中创建的服务类型。回想一下,推理管道可能包含模型执行或数据转换,或者它可能是异常值检测器。对于模型执行,此参数的值为MODEL。
- GRPC_PORT : 端口Google 远程过程调用( gRPC )端点将侦听模型推理。
- METRICS_PORT:将公开服务性能数据的端口。请注意,这是服务的性能数据,而不是模型。
- HTTP_NAME:您将通过 HTTP 为模型提供服务的 HTTP 端口。
现在,我们有一个Docker 文件形式的容器规范。接下来,我们将了解如何使用 Seldon 控制器在 Kubernetes 平台上部署容器。
使用 Seldon 控制器部署模型
我们的机器学习平台提供了一个 Seldon 控制器,这是一个作为 pod 运行的软件,可帮助部署您在上一节中构建的容器。请注意,我们平台中的控制器是现有 Seldon 算子的扩展。在撰写本文时,Seldon 算子与 Kubernetes 1.22 版本不兼容,因此我们扩展了现有算子以与 Kubernetes 平台的最新和未来版本一起工作。
请参阅第 4 章,机器学习平台剖析,了解如何安装 ODH 以及它如何在 Kubernetes 集群上工作。以等效的方式,Seldon 控制器也由 ODH 运营商安装。manifests/ml-platform.yaml文件包含用于安装 Seldon 控制器的配置。图 7.5显示了设置:

图 7.5 – 清单文件的 MLFlow 部分
让我们验证一下 Seldon 控制器是否在集群中正确运行:
kubectl get pods –n ml-workshop | grep -i seldon您应该看到以下响应:

图 7.6 – Seldon 控制器吊舱
Seldon 控制器 pod 由 ODH 操作员安装,它们监视 Seldon 部署 CR。这个此资源的架构由 Seldon Deployment自定义资源定义( CRD ) 定义;您可以在manifests/odhseldon/cluster/base/seldon-operator-crd-seldondeployments.yaml找到 CRD 。创建 Seldon Deployment CR 后,控制器会部署与 CR 关联的 Pod。图 7.7显示了这种关系:

图 7.7 – 部署 Seldon 服务的平台组件
让我们来看看这Seldon Deployment CR 的不同组件。您可以在chapter7/manual_model_deployment/SeldonDeploy.yaml中找到一个简单的示例。
Seldon Deployment CR 包含 Seldon 控制器在 Kubernetes 集群上部署模型所需的所有信息。Seldon 部署 CR 包含三个主要部分:
- 一般信息:这是描述apiVersion、kind和其他 Kubernetes 相关信息的部分。您将 Seldon 部署的标签和名称定义为任何其他 Kubernetes 对象。您可以在以下屏幕截图中看到它包含对象的标签和注释:

图 7.8 – Seldon 部署 – Kubernetes 相关信息
- 容器规范:第二部分是您提供有关容器位置、部署和服务的水平 pod 扩展配置的详细信息。请注意,这与您在 precedin 中构建的容器相同g部分。图 7.7包含chapter7/manual_model_deployment/SeldonDeploy.yaml文件中包含此信息的部分。
请注意,容器为图像对象采用一个数组,因此您可以添加更多图片给它。图像键将包含您的容器的位置。env数组定义了可用于 pod 的环境变量。回想一下,在上一节的 Docker 文件中,已经使用了这些变量。MODEL_NAME的值为Predictor,它是您用作包装器的类的名称。SERVICE_TYPE的值为MODEL,表示该容器提供的服务类型。
最后一部分是hpaSpec,Seldon 控制器会将其转换为Kubernetes Horizontal Pod Autoscaler对象。通过这些设置,您可以在服务推理调用时控制 pod 的可扩展性。对于以下示例,maxReplicas设置为1,因此不会有任何新的 pod,但您可以为每个部署控制此值。如果以下示例中 Pod 的 CPU 利用率超过 80%,则可扩展性将发挥作用;但是,由于maxReplica为1,因此不会创建任何新的 Pod。

图 7.9 – Seldon 部署 – Seldon 服务容器
- 推理图:部分在图形键下为您的服务构建推理图。推理图将具有不同的节点,您将定义每个节点将使用的容器。您将看到有一个children键,它带有一个对象数组,您可以通过这些对象定义推理图。对于这个例子,graph只有一个节点,而children键没有与之关联的信息;但是,在后面的章节中,您将看到如何构建具有更多节点的推理图。
图下的其余字段定义推理图的第一个节点。name字段的值与您在容器部分中给出的名称相对应。请注意,这是 Seldon 知道哪个容器将在推理图的此节点上提供服务的关键。
另一个重要的部分是记录器部分。Seldon 可以自动将请求和响应转发到记录器部分下提到的 URL 。这转发请求和响应的能力可用于多种场景,例如出于审计/法律原因存储有效负载或应用数据漂移算法来触发再训练或其他任何事情。请注意,如果需要,Seldon 也可以转发到 Kafka,但这超出了本书的范围。
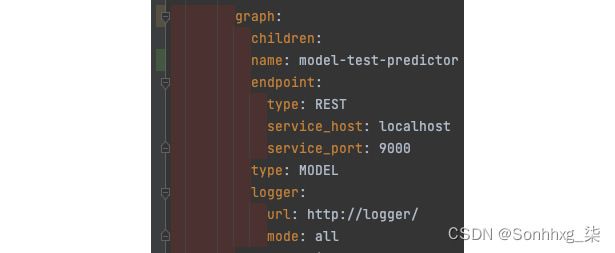
图 7.10 – Seldon 部署 – 推理图
使用常规kubectl命令创建 Seldon 部署 CR 后,Seldon 控制器将部署 pod,并且该模型将可作为服务使用。
接下来,我们将继续打包和部署您在第 6 章机器学习工程中构建的基本模型。
使用 Seldon Core 打包、运行和监控模型
在这个部分,你将要包裹和从您在第 6 章机器 学习工程中构建的模型文件构建容器。然后,您将使用 Seldon 部署来部署和访问模型。在本书的后面部分,您将自动化该过程,但要手动完成,就像您将在本节中所做的那样,我们将进一步加强您对组件及其工作方式的理解。
在开始本练习之前,请确保您已使用公共 Docker 注册表创建了一个帐户。我们将使用免费的quay.io作为我们的注册表,但您可以自由使用您喜欢的注册表:
1.让我们首先验证 MLflow 和 Minio(我们的 S3 服务器)是否在我们的集群中运行:
kubectl get pods -n ml-workshop | grep -iE 'mlflow|minio'您应该看到以下响应:

图 7.11 – MLflow 和 Minio 在平台上运行
2.获取 MLflow 的入口列表,并使用以下输出中的mlflow URL 登录到 MLflow:
kubectl get ingresses.networking.k8s.io -n ml-workshop您应该看到以下响应:

图 7.12 – Kubernetes 集群中的入口
3.进入 MLflow UI 后,导航到您在第 6 章机器学习工程中记录的实验。实验的名称是HelloMIFlow。
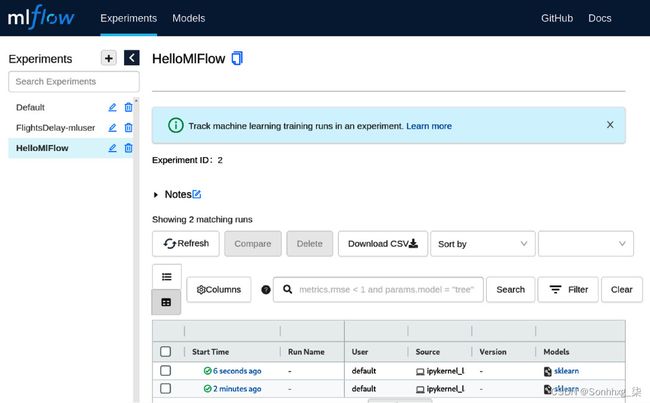
图 7.13 – MlFlow 实验跟踪
4.选择这第一的从右手边跑控制板要得到到运行的详细信息页面。在Artifacts部分,单击model.pkl,您将在右侧看到一个小的下载箭头图标。使用 图标从此屏幕下载model.pkl和requirements.txt文件。
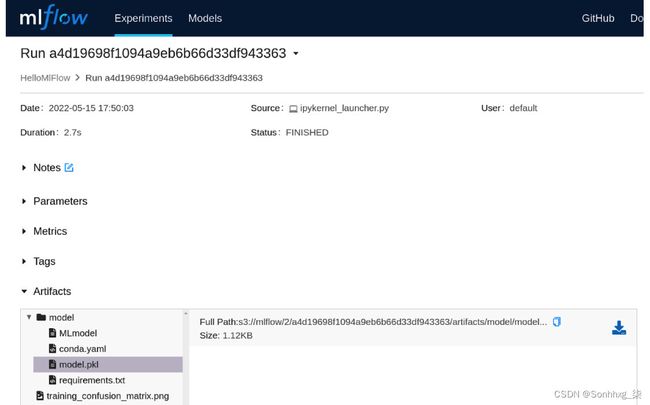
图 7.14 – MLflow 实验跟踪 – 运行细节
5.前往文件夹在哪里你有克隆的本书附带的代码库。如果您还没有这样做,请在您的本地计算机上克隆https://github.com/PacktPublishing/Machine-Learning-on-Kubernetes.git存储库。
6.然后,进入chapter7/model_deploy_pipeline/model_build_push文件夹,将上一步下载的两个文件复制到这个文件夹中。最后,此文件夹将包含以下文件:
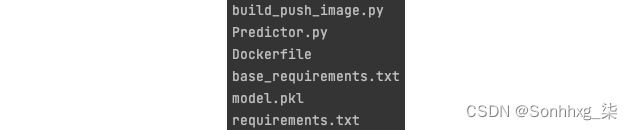
图 7.15 – 将模型打包为容器的示例文件
笔记
最后两个文件是您刚刚复制的文件。所有其他文件都来自您克隆的代码存储库。
好奇的人会注意到,您从 MLFlow 服务器下载的requirements.txt文件包含运行 notebook 进行模型训练时所需的包。并非所有这些包(例如mlflow)都需要执行保存的模型。为了简单起见,我们将把它们全部添加到我们的容器中。
7.现在,让's 在本地机器上构建容器:
docker build -t hellomlflow-manual:1.0.0 。你应该看这下列的回复:
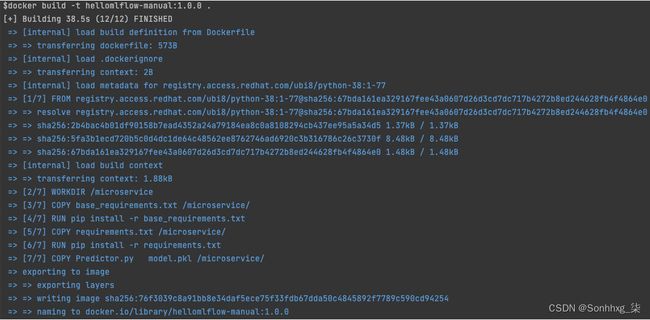
图 7.16 – 将模型打包成一个容器
8.下一步是标记容器并将其推送到您选择的存储库。在将映像推送到存储库之前,您需要拥有一个具有映像注册表的帐户。如果您没有,可以在https://hub.docker.com或https://quay.io创建一个。创建注册表后,您可以运行以下命令来标记和推送图像:
docker tag hellomlflow-manual:1.0.0 /hellomlflow-manual:1.0.0
docker push /hellomlflow-manual:1.0.0 你应该看这下列的回复。你会注意到,在以下屏幕截图中,我们将quay.io/ml-on-k8s称为我们的注册表:
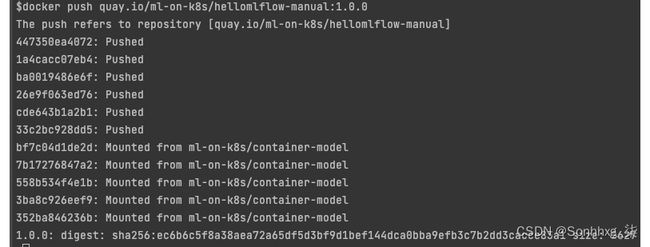
图 7.17 – 将模型推送到公共存储库
9.现在您的容器在注册表中可用,您将需要使用 Seldon Deployment CR 将其部署为服务。打开chapter7/manual_model_deployment/SeldonDeploy.yaml文件,调整镜像位置。
在我修改第 16 行(根据我的图像位置)后,您可以看到该文件,如下所示:
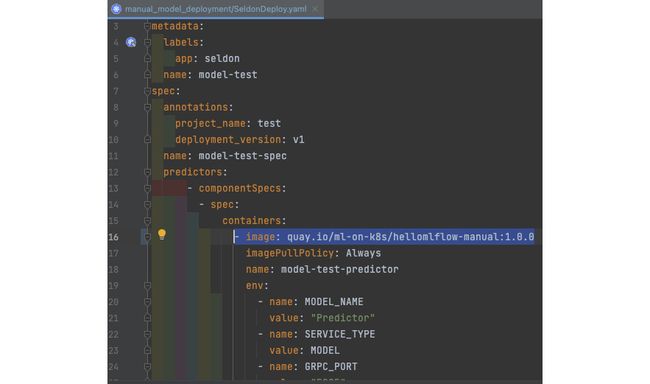
图 7.18 – Seldon 部署 CR 与映像位置
10.让我们部署这模型作为一项服务通过部署chapter7/manual_model_deployment/SeldonDeploy.yaml文件。运行以下命令:
kubectl create -f chapter7/manual_model_deployment/SeldonDeploy.yaml -n ml-workshop您应该看到以下响应:
图 7.19 – 创建 Seldon 部署 CR
11.验证容器是否处于运行状态。运行以下命令:
kubectl get pod -n ml-workshop | grep model-test-predictor您会注意到,您在SeldonDeploy.yaml文件 ( model-test-predictor ) 的图形部分中输入的名称是容器名称的一部分。
您应该看到以下响应:
图 7.20 – 在 Seldon Deployment CR 之后验证 pod
12.伟大的!您有一个作为服务运行的模型。现在,让我们看看创建的 pod 中有什么为了我们由 Seldon 控制器。运行以下命令以获取列表容器里面我们的在下面:
export POD_NAME=$(kubectl get pod -o=custom-columns=NAME:.metadata.name -n ml-workshop | grep model-test-predictor)
kubectl get pods $POD_NAME -o jsonpath='{.spec.containers[*].name}' -n ml-workshop您应该看到以下响应:
图 7.21 – Seldon pod 内的容器
您将看到有两个容器。一个是model-test-predictor,也就是我们构建的镜像,第二个容器是seldon-container-engine,也就是 Seldon 服务器。
model-test-predictor容器具有模型,并使用语言包装器通过 HTTP 和 gRPC 公开模型。您可以使用以下命令查看日志以及从model-test-predictor公开了哪些端口:
kubectl logs -f $POD_NAME -n ml-workshop -c model-test-predictor您应该看到以下响应(以及其他日志):

图 7.22 – 显示端口的容器日志
您可以看到服务器已准备好在9000上为 HTTP 和在6005上为指标服务器进行调用。该指标服务器将具有基于 Prometheus 的监控在/prometheus端点上公开的数据。你可以看到这个在这下列的部分日志:![]()
图 7.23 – 显示 Prometheus 端点的容器日志
第二个容器是seldon-container-engine,它对推理图进行编排并将有效负载转发到您在 Seldon Deployment CR 的记录器部分中配置的服务。
13.在此步骤中,您将了解 Seldon Deployment CR 为您创建的 Kubernetes 对象。一种简单的查找方法是运行以下命令。此命令依赖于 Seldon 控制器,它使用标签键将其创建的对象标记为seldon-deployment-id,值是您的 Seldon 部署 CR 的名称,即model-test:
kubectl get all -l seldon-deployment-id=model-test -n ml-workshop您应该看到以下响应:

图 7.24 – Seldon 控制器创建的 Kubernetes 对象
您可以看到使用您在 Seldon Deployment CR 中提供的配置为 Seldon 控制器创建了Deployment 对象、服务和Horizontal Pod Autoscaler ( HPA ) 对象。部署最终会为您的 pod 创建 pod 和副本集。Seldon 控制器使我们可以轻松地在 Kubernetes 平台上部署我们的模型。
14.您可能已经注意到 Seldon Deployment CR 没有创建入口对象。让我们创建入口对象那我们可以从外部调用我们的模型这簇通过如下运行命令。入口对象由chapter7/manual_model_deployment/Ingress.yaml中的文件创建。确保根据您的配置调整主机值,就像您在前面的章节中所做的那样。您还会注意到入口正在将流量转发到端口8000。Seldon 为该端口提供侦听器,该端口编排推理调用。此服务在名为seldon-container-engine的容器中可用:
kubectl create -f chapter7/manual_model_deployment/Ingress.yaml -n ml-workshop您应该看到以下响应:
图 7.25 – 为我们的服务创建入口对象
通过发出以下命令验证入口是否已创建:
kubectl get ingress -n ml-workshop | grep model-test您应该看到以下响应:
图 7.26 – 验证我们服务的入口
15.由于我们的 Seldon Deployment CR 引用了一个记录器 URL,因此您将部署一个简单的 HTTP 回显服务器,它只会打印它收到的调用。这将帮助我们验证有效负载是否已转发到 Seldon Deployment CR 的记录器部分中配置的 URL。一个非常简单的回显服务器能够是创建通过这以下命令:
kubectl create -f chapter7/manual_model_deployment/http-echo-service.yaml -n ml-workshop您应该看到以下响应:

图 7.27 – 创建一个简单的 HTTP 回显服务器来验证有效负载日志
通过发出以下命令来验证 pod 是否已创建:
kubectl get pods -n ml-workshop | grep logger您应该看到以下响应:
图 7.28 – 验证一个简单的 HTTP 回显服务器
16.让我们调用我们的模型来预测一些东西。上一章我们开发的模型用处不大,但是会帮助我们理解和验证打包和部署模型的整个过程。
回想一下第 6 章机器学习工程,hellomlflow笔记本的输入形状为(4,2),输出形状为(4,)。
![]()
图 7.29 – 模型的输入和输出
因此,如果我们想至发送数据到在我们的模型中,它将是一个整数对数组,例如 [ 2,1 ]。当您调用您的模型时,输入数据需要在名为data的键下的ndarray字段中。输入如下所示。这是 Seldon 服务期望发送给它的数据的格式:

图 7.30 – 作为 HTTP 有效负载的模型输入
17.接下来是模型的 REST 端点。这将是您在第 13 步中创建的入口和标准 Seldon URL。最终形式如下:http://
就我而言,这将转换为http://model-test.192.168.61.72.nip.io/api/v1.0/predictions。
现在,您拥有了用于发送此请求的有效负载和 URL。
18.在此步骤中,您将调用您的模型。我们正在使用常用的命令行选项进行此调用;但是,您可以选择使用其他软件(例如 Postman)来进行此 HTTP 调用。
您将在调用中使用POST HTTP 动词,然后提供服务的位置。您必须传递Content-Type标头才能提及 JSON 内容和这身体是通过使用curl 程序的data-raw标志:
curl -vvvv -X POST 'http:///api/v1.0/predictions' \--header 'Content-Type: application/json' \--data-raw '{ "data": { "ndarray": [[2,1]] }}' 最终请求应如下所示。在进行此调用之前,请确保根据您的入口位置更改 URL:
curl -vvvv -X POST 'http://model-test.192.168.61.72.nip.io/api/v1.0/predictions' \--header 'Content-Type: application/json' \--data-raw '{ "data": { "ndarray": [[2,1]] }}'您应该看到以下响应。请注意,命令的输出显示了与我们的模型相同形状的数组,即(4,),它位于以下屏幕截图中的ndarray键下:

图 7.31 – 模型推理调用的输出负载
19.现在,让我们验证模型有效负载是否已登录到我们的回显服务器。您正在验证 Seldon 捕获输入和输出并将其发送到所需位置以进行进一步处理的能力,例如漂移检测或审计日志记录:
export LOGGER_POD_NAME=$(kubectl get pod -o=custom-columns=NAME:.metadata.name -n ml-workshop | grep logger)
kubectl logs -f $LOGGER_POD_NAME -n ml-workshop您将看到输入和输出有效负载有单独的记录。您可以使用ce-requestid密钥相关日志中的两条记录。以下屏幕截图显示主要的领域这捕获的推理调用的输入有效负载:
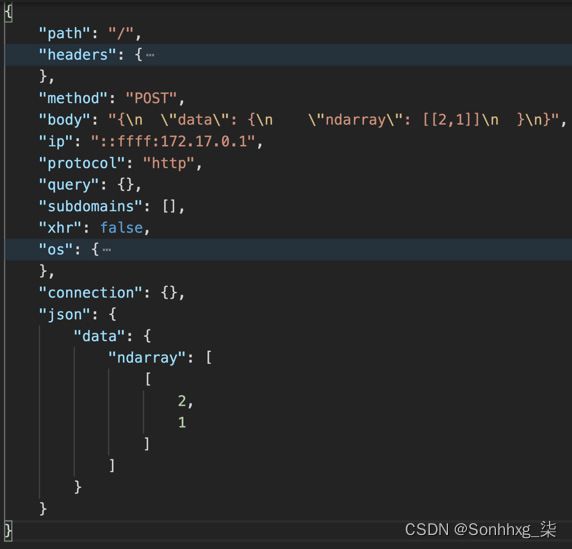
图 7.32 – 捕获的输入负载转发到 echo pod
下面的截图显示推理调用的输出负载的主要字段:
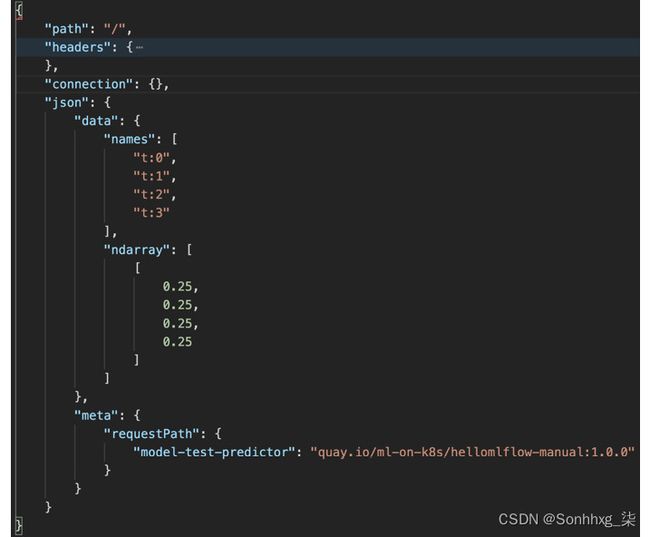
图 7.33 – 捕获的输出负载转发到 echo pod
20.现在,让我们核实那服务监控数据由 Seldon 引擎捕获,可供我们使用和记录。请注意,Prometheus 的工作方式是重复抓取,因此此数据处于当前状态,Prometheus 服务器负责调用此 URL 并记录在其数据库中。
此信息的 URL 格式如下。入口与您在步骤 13中创建的相同:
http:///prometheus 对于我的入口,这将转化为以下内容:
http://model-test.192.168.61.72.nip.io/prometheus打开一个浏览器并访问其中的 URL。您应该看到以下响应:

图 7.34 – 访问 Prometheus 格式的监控数据
您会发现捕获了很多信息,包括响应时间、每个状态码(200、400、500 等)的 HTTP 响应数、数据捕获、服务器性能以及公开 Go 运行时指标。我们鼓励您通过这些参数来了解可用数据。在后面的章节中,您将看到如何收集和绘制这些数据以可视化模型推理服务器的性能。
你已经完成了一个伟大的处理这个练习。目的的这个部分是展示使用 Seldon Core 部署模型所涉及的步骤和组件。在下一节中,您将了解平台的工作流组件 Airflow,在接下来的几章中,所有这些步骤都将使用 ML 平台中的组件实现自动化。
介绍 Apache Airflow
Apache Airflow 是一个设计用于以编程方式创作、执行、调度和监控工作流的开源软件。工作流是一系列任务,可以包括数据管道、ML 工作流、部署管道,甚至基础设施任务。它由 Airbnb 作为工作流管理系统开发,后来作为 Apache 软件基金会孵化计划中的一个项目开源。
虽然大多数工作流引擎使用 XML 来定义工作流,但 Airflow 使用 Python 作为定义工作流的核心语言。工作流中的任务也是用 Python 编写的。
Airflow 有很多特性,但我们将在本书中只介绍 Airflow 的基本部分。本节绝不是 Airflow 的详细指南。我们的重点是向您介绍 ML 平台的软件组件。让我们从 DAG 开始。
了解DAY
工作流程能够可以简单地定义为一系列任务。在气流,任务序列遵循称为有向无环图(DAG)的数据结构。如果您还记得您的计算机科学数据结构,那么 DAG 由节点和单向顶点组成,其组织方式确保没有循环或循环。因此,Airflow 中的工作流称为 DAG。
图 7.35显示了数据管道工作流的典型示例:

图 7.35 – 典型的数据管道工作流程
图 7.36中的示例工作流由方框表示的任务组成。这些任务的执行顺序由箭头的方向决定:

图 7.36 – 并行执行的示例工作流
其他例子一个工作流程如图 7.36所示。在此示例中,存在并行执行的任务。生成报告任务将等待两个转换数据任务完成。这称为执行依赖,并且这是 Airflow 正在解决的问题之一。任务只有在上游任务完成后才能执行。
只要图中没有循环,您就可以随意配置工作流程,如图 7.37所示:
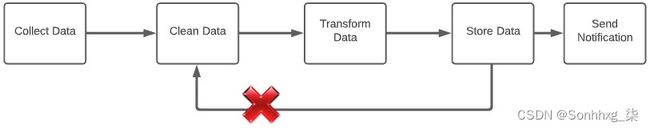
图 7.37 – 带有循环的示例工作流
在图 7.37的示例中,Clean Data任务将永远不会被执行,因为它依赖于Store Data任务,该任务也不会被执行。Airflow 只允许非循环图。
如图所示,DAG 是一系列任务,Airflow 中常见的任务类型有以下三种:
- Operators:可用于执行某些操作的预定义任务,它们可以串在一起形成管道或工作流。您的 DAG 大部分(如果不是全部)由运算符组成。
- Sensors:运算符的子类型,用于基于外部事件的一系列其他运算符。
- TaskFlow :用@task装饰的自定义 Python 函数。这允许您将常规 Python 函数作为任务运行。
空气流动运算符是可扩展的,这意味着有相当多的许多由社区创建的预定义运算符,您可以简单地使用。您将在以下练习中主要使用的运算符之一是笔记本操作员。此运算符允许您将任何 Jupyter 笔记本作为 DAG 中的任务运行。
那么,使用 DAG 执行一系列任务有哪些优势呢?仅仅编写一个可以顺序执行其他脚本的脚本还不够吗?好吧,答案就在于 Airflow 提供的功能,我们将在接下来探索这些功能。
探索 Airflow功能
优点与cron作业和脚本相比,Airflow 带来的功能可以通过其功能进行详细说明。让我们先来看看其中的一些功能:
- 失败和错误管理:如果任务失败,Airflow 会优雅地处理错误和失败。可以将任务配置为在失败时自动重试。您还可以配置它重试的次数。
就执行顺序而言,典型工作流中有两种类型的任务依赖,可以在 Airflow 中进行管理,这比编写脚本要容易得多。
- 数据依赖关系:某些任务可能需要先处理其他任务,因为它们需要其他任务生成的数据。这可以在 Airflow 中进行管理。此外,Airflow 允许将少量元数据从一个任务的输出作为输入传递给另一个任务。
- 执行依赖项:您可以在一个小型工作流中编写执行依赖项脚本。然而,想象一下在 Bash 中编写一个包含一百个任务的工作流脚本,其中一些任务可以同时运行,而另一些只能按顺序运行。我想这是一项相当艰巨的任务。Airflow 通过创建 DAG 来帮助简化这一过程。
- 可扩展性:气流可以水平扩展到多台机器或容器。工作流中的任务可以在不同的节点上执行,同时由公共调度程序集中编排。
- 部署:Airflow 可以使用 Git 来存储 DAG。这使您可以连续为您的工作流程部署新的更改。Sidecar 容器可以自动从包含 DAG的git存储库中获取更改。这使您可以实现 DAG 的持续集成。
下一步是了解 Airflow 的不同组件。
了解 Airflow组件
Airflow 包含多个作为独立服务运行的组件。图 7.38显示了 Airflow 的组件及其交互:
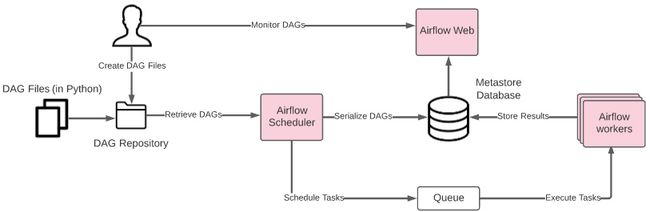
图 7.38 – 气流组件
三大核心服务空气流动。Airflow Web提供用户界面,用户可以在其中直观地监控 DAG 和任务并与之交互。气流调度器是一个负责为 Airflow Worker 调度任务的服务。调度不仅仅意味着按照预定的时间执行任务。它还涉及以特定顺序执行任务,同时考虑到执行依赖性和故障管理。气流工作者是执行任务的服务。这也是 Airflow 的主要可扩展点。运行的 Airflow Worker 越多,可以同时执行更多任务。
DAG 存储库是文件系统中的一个目录,其中以 Python 编写的 DAG 文件由调度程序存储和检索。我们平台中配置的 Airflow 实例包括一个边车容器,用于将 DAG 存储库与远程git存储库同步。这通过简单地将 Python 文件推送到 Git 来简化 DAG 的部署。
我们不会在本书中深入研究 Airflow。目标是让您学习到能够在 Airflow 中以最少的 Python 编码创建管道的程度。您将使用 Elyra 笔记本管道构建器功能以图形方式构建 Airflow 管道。如果您想了解更多有关 Airflow 以及如何在 Python 中以编程方式构建管道的信息,我们建议您从 Apache Airflow 非常丰富的文档开始,网址为https://airflow.apache.org/docs/apache-airflow/stable/concepts/overview .html。
现在您已经对 Airflow 有了基本的了解,是时候看看它的实际应用了。在第 4 章,机器学习平台剖析中,您安装了一个全新的 ODH 实例。这个过程也为您安装了 Airflow 服务。现在,让我们验证这个安装。
验证 Airflow 安装
验证这一点Airflow 在您的集群中运行正常,您需要执行以下步骤:
1.通过执行以下命令检查是否所有 Airflow pod 都在运行:
kubectl get pods -n ml-workshop | grep airflow您应该看到三个 Airflow 服务 pod 处于运行状态,如图 7.39中的屏幕截图所示。验证所有 pod 都处于Running状态:

图 7.39 – 处于 Running 状态的 Airflow pod
2.通过查看ap-airflow2的入口主机获取 Airflow Web 的 URL 。您可以通过执行以下命令来执行此操作:
kubectl get ingress -n ml-workshop | grep airflow您应该会看到类似于图 7.39的结果。记下ap-airflow2入口的主机值。IP 地址在您的环境中可能不同:
![]()
图 7.40 – ml-workshop 命名空间中的气流入口
3.导航到https://airflow.192.168.49.2.nip.io。注意域名是ap-airflow2入口的主机值。您应该会看到 Airflow Web UI,如图 7.41所示:
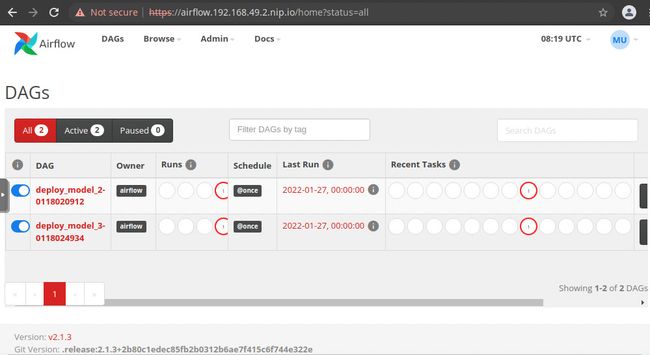
图 7.41 – Apache Airflow 的主屏幕
如果能够加载 Airflow 登陆页面,则说明 Airflow 安装有效。您一定还注意到,在列出 DAG 的表中,已经存在 DAG目前处于失败状态。这些是位于https://github.com/airflow-dags/dags/中的现有 DAG 文件,这是默认配置的 DAG 存储库。您将需要为您的实验创建自己的 DAG 存储库。下一节将提供有关如何执行此操作的详细信息。
配置 Airflow DAG 存储库
DAG 存储库是一个Git 存储库,Airflow 在其中提取代表您的管道或工作流的 DAG 文件。要将 Airflow 配置为指向您自己的 DAG 存储库,您需要创建一个 Git 存储库并将 Airflow Scheduler 和 Airflow Web 指向此 Git 存储库。您将使用GitHub创建此存储库。以下步骤将指导您完成整个过程:
1.转到https://github.com创建一个 GitHub 存储库。这要求您有一个现有的 GitHub 帐户。出于本练习的目的,我们将此存储库命名为 airflow-dags。记下新 Git 存储库的 URL。它应该如下所示:https ://github.com/your-user-name/airflow-dags.git 。我们假设您已经知道如何在 GitHub 上创建新存储库。
2.通过编辑kfdef(Kubeflow 定义)对象来编辑您的 ODH 实例。您可以通过执行以下命令来执行此操作:
kubectl edit kfdef opendatahub-ml-workshop -n ml-workshop你应该显示kfdef清单文件的vim编辑器,如图 7.42所示。按i开始编辑。
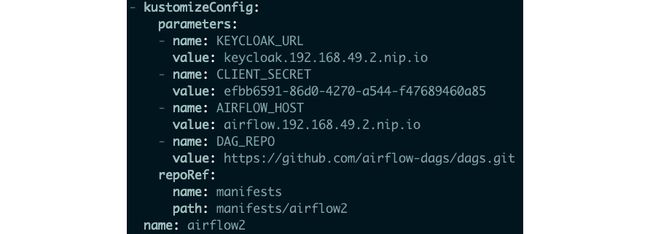
图 7.42 – vim 编辑器显示定义 Airflow 实例的部分
3.将DAG_REPO参数的值替换为您在步骤 1中创建的 Git 存储库的 URL 。编辑后的文件应该如图 7.43中的屏幕截图所示。按Esc,然后按:,然后键入wq并按Enter保存您对kfdef对象所做的更改。
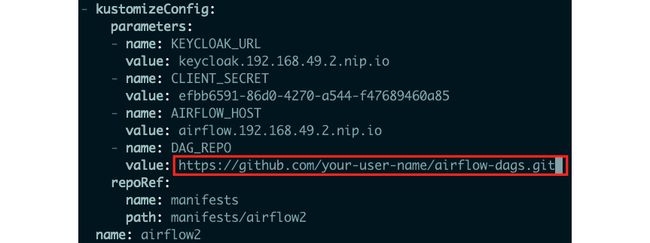
图 7.43 – 编辑后 DAG_REPO 参数的值
更改将由 ODH 操作员获取,并将应用于受影响的 Kubernetes 部署对象,在本例中为 Airflow Web 和 Airflow Scheduler部署。此过程将需要几分钟才能完成。
4.通过检查 Airflow 部署来验证更改。您可以通过运行以下命令来查看部署对象的应用清单来执行此操作:
kubectl get deployment app-aflow-airflow-scheduler -o yaml -n ml-workshop | grep value:.*airflow-dags.git这应该返回包含 GitHub 存储库 URL 的行。
5.因为这个存储库是新的并且是空的,所以当您打开 Airflow Web UI 时应该看不到任何 DAG 文件。要验证 Airflow Web 应用程序,导航到您的 Airflow URL,或刷新您现有的浏览器选项卡,您应该会看到一个空的 Airflow DAG 列表,类似于图 7.44中的屏幕截图:
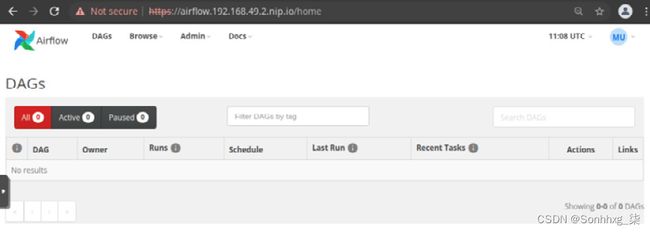
图 7.44 – Empty Airflow DAG 列表
现在你已经验证了您的 Airflow 安装并将 DAG 存储库更新到您自己的git存储库,是时候充分利用 Airflow 了。
配置 Airflow 运行时映像
空气流动可以通过使用 Airflow 库编写 Python 文件来创作管道或 DAG。但是,也可以从 Elyra 笔记本以图形方式创建 DAG。在本节中,您将从 Elyra 创建一个 Airflow DAG,将其推送到 DAG 存储库,然后在 Airflow 中执行它。
要进一步验证 Airflow 设置并测试配置,您需要运行一个简单的Hello world管道。按照步骤创建一个包含两个任务的管道。您将创建 Python 文件、管道并配置要在整个过程中使用的运行时映像:
1.如果您没有正在运行的 notebook 环境,请导航到 JupyterHub,单击Start My Server并选择要运行的 notebook 映像来启动 notebook 环境,如图 7.45所示。这次我们使用Base Elyra Notebook Image,因为我们不需要任何特殊的库。

图 7.45 – JupyterHub 登陆页面显示选择了 Base Elyra Notebook Image
2.在你的Elyra 浏览器,导航到Machine-Learning-on-Kubernetes/chapter7/model_deploy_pipeline/目录。
3.打开一个新的管道编辑器。您可以通过选择菜单项File>New>Pipeline Editor来执行此操作,如图 7.46所示。左侧浏览器中将出现一个名为untitled.pipeline的新文件。
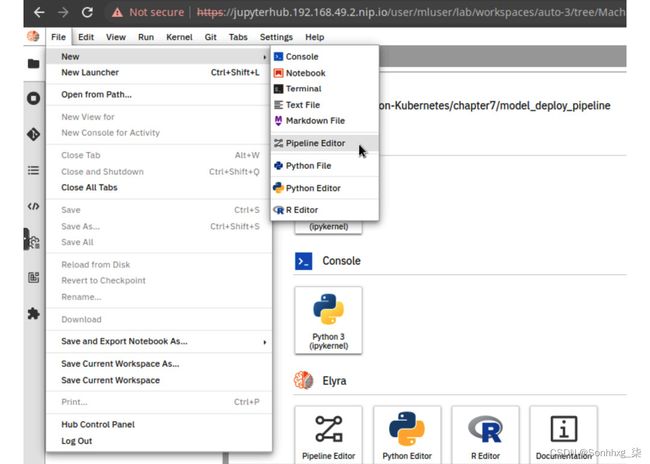
图 7.46 – Elyra 笔记本
4.右键点击在untitled.pipeline文件上并将其重命名为hello_world.pipeline。
5.创建两个包含以下行的具有相同内容的 Python 文件:print('Hello airflow!')。您可以通过选择菜单项File > New Python File 来执行此操作。然后,将文件重命名为hello.py和world.py。您的目录结构应该类似于图 7.47中的屏幕截图:
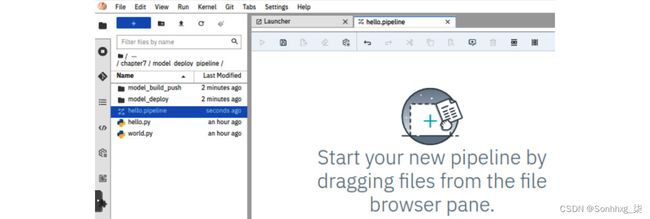
图 7.47 – 显示 hello.pipeline 文件的 Elyra 目录结构
6.通过将hello.py文件拖到管道编辑器窗口中来创建具有两个任务的管道。对world.py做同样的事情。通过将任务框右侧的小圆圈拖动到另一个框来连接任务。生成的管道拓扑应该如图 7.48 所示。保存管道单击顶部工具栏中的保存图标。
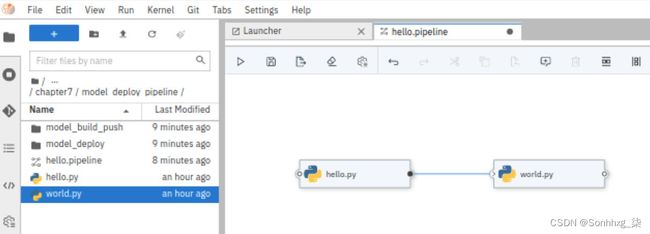
图 7.48 – 任务拓扑
7.在我们可以运行这个管道之前,我们需要配置每个任务。因为每个任务都将作为 Kubernetes 中的容器运行,所以我们需要知道该任务将使用哪个容器镜像。选择左侧工具栏上的运行时图像图标。然后,单击+按钮添加一个新的运行时映像,如图 7.49所示:
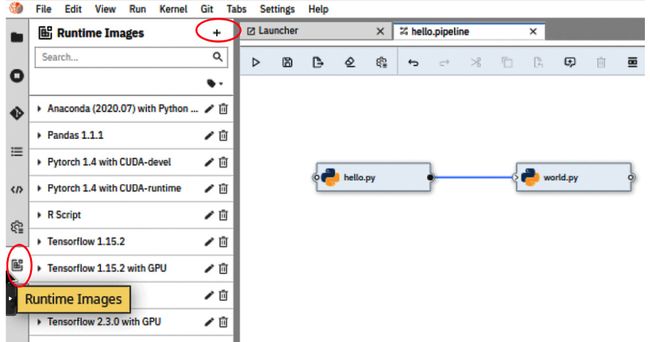
图 7.49 – 在 Elyra 中添加新的运行时映像
8.在Add new Runtime Image对话框,添加Kaniko Container Builder镜像的细节,如图 7.50 所示,然后点击SAVE & CLOSE按钮。
这个容器镜像 ( Quay ) 包含构建 Docker 文件并将镜像从 Kubernetes 内推送到镜像注册表所需的工具。此映像还可以从 MLflow 模型注册表中提取 ML 模型和元数据。在下一节中,您将使用此映像来构建托管您的 ML 模型的容器。这个容器镜像是为了本书的目的而创建的。您可以将任何容器镜像用作管道任务的运行时镜像,只要该镜像可以在 Kubernetes 上运行。

图 7.50 – 为 Kaniko builder 添加新的 Runtime Image 对话框
9.加上另一个名为Airflow Python Runner的运行时映像。容器镜像位于Quay。该镜像可以运行任何 Python 3.8 脚本,并与 Kubernetes 和 Spark 操作符进行交互。在下一节中,您将使用此镜像将容器镜像部署到 Kubernetes。关于Add new Runtime Image对话框字段值,请参见图 7.51,然后点击SAVE & CLOSE按钮:
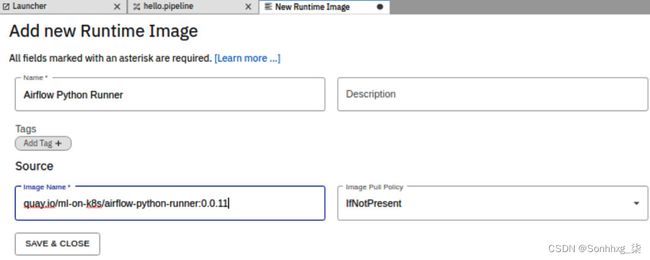
图 7.51 – 为 Airflow Python Runner 添加新的 Runtime Image 对话框
10.将图像从远程存储库拉到 Kubernetes 集群的本地 Docker 守护程序。这将通过使用已拉入本地 Docker 实例的运行时映像来帮助加快 Airflow 中任务的启动时间。
您可以通过在运行 Minikube 的同一台机器上运行以下命令来执行此操作。此命令允许您将 Docker 客户端连接到您内部的 Docker 守护程序Minikube虚拟机(VM):
eval $(minikube docker-env)11.通过在运行 Minikube 的同一台机器上运行以下命令来拉取Kaniko Container Builder映像。这会将镜像从quay.io拉取到 Minikube中的 Docker 守护进程:
docker pull quay.io/ml-on-k8s/kaniko-container-builder:1.0.012.通过在同一命令中运行以下命令来拉取Airflow Python Runner映像运行 Minikube 的机器:
docker pull quay.io/ml-on-k8s/airflow-python-runner:0.0.1113.将Kaniko Container Builder运行时映像分配给hello.py任务。您可以通过右键单击任务框并选择“属性”上下文菜单项来执行此操作。任务的属性将显示在管道编辑器的右侧窗格中,如图 7.52所示。使用Runtime Image下拉框,选择Kaniko Container Builder。
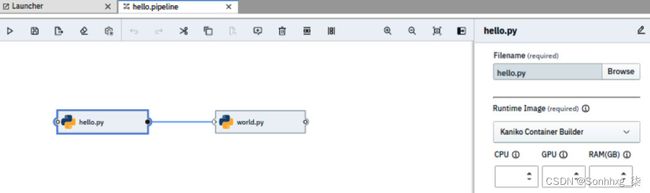
图 7.52 – 在管道编辑器中设置任务的运行时映像
笔记
如果在下拉列表中没有看到新添加的运行时映像,则需要关闭并重新打开管道编辑器。这将刷新运行时映像列表。
14.将Airflow Python Runner运行时映像分配给world.py任务。这是类似于Step 10,但针对world.py任务。有关6运行时映像值,请参见图 7.53 :
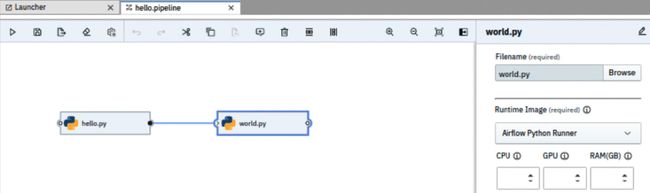
图 7.53 – 在管道编辑器中设置任务的运行时映像
15.您刚刚创建了一个包含两个任务的 Airflow 管道,其中每个任务使用不同的运行时。但是,在我们可以在 Airflow 中运行这条管道之前,我们需要告诉 Elyra Airflow 在哪里。为此,请选择Elyra 左侧工具栏上的Runtimes图标,如图 7.54所示:

图片 7.54 – 运行时工具栏
16.点击+按钮并选择New Apache Airflow 运行时菜单项。根据以下数值填写详细信息或见图7.55:
- Apache Airflow UI Endpoint是 Airflow UI 当前正在侦听的位置。这并不重要,因为 Elyra 不直接与 Airflow UI 交互。将值设置为 Airflow UI 的 URL。这看起来像https://airflow.192.168.49.2.nip.io,其中 IP 地址部分是您的 Minikube 的 IP 地址。
- Apache Airflow 用户命名空间是 Kubernetes 命名空间,将在其中创建所有任务的 pod。将此设置为ml-workshop。这是所有 ML 平台工作负载的命名空间。
- GitHub DAG 存储库是您在上一部分“配置 Airflow DAG 存储库”中创建的 DAG 存储库。这遵循github-username/airflow-dags格式。将github-username替换为您的 GitHub 用户名。
- GitHub DAG 存储库分支是 GitHub 存储库中的分支,Elyra 将在其中推送 DAG 文件。将此设置为main。
- GitHub 个人访问令牌是您的 GitHub 用户令牌,有权推送到您的 DAG 存储库。您可以在https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token参考 GitHub 文档以创建个人访问令牌。
- Cloud Object Storage Endpoint是任何 S3 存储 API 的端点 URL。Airflow 使用它来发布 DAG 执行的工件和日志。您将为此使用相同的 Minio 服务器。将值设置为http://minio-ml-workshop:900。这是 Minio 服务的 URL。我们没有使用 Minio 的ingress,因为 JupyterHub 服务器与 Minio 服务器运行在同一个 Kubernetes 命名空间上,这意味着 Minio 服务可以通过其名称来寻址。
- Cloud Object Storage 用户名是 Minio 用户名,即minio。
- Cloud Object Storage Password是 Minio 密码,即minio123。
正确填写所有字段后,点击保存并关闭按钮。
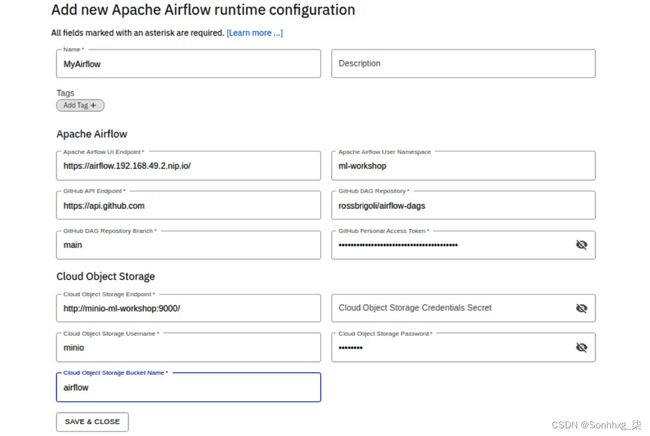
图 7.55 – 添加新的 Apache Airflow 运行时配置
17.跑过通过单击管道编辑器顶部工具栏中的“播放”按钮,在 Airflow中创建管道。这将打开一个运行管道对话框。选择Apache Airflow 运行时作为运行时平台和MyAirflow作为运行时配置,然后点击OK。参考图 7.56:
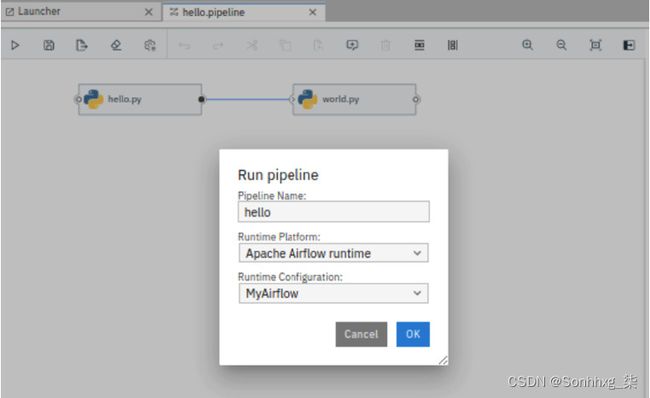
图 7.56 – 运行管道对话框
这个动作生成一个 Airflow DAG 文件并将该文件推送到配置为 DAG 存储库的 GitHub 存储库。您可以通过检查 GitHub 存储库中是否有新推送的文件来验证这一点。
18.打开Airflow网站。您应该会看到新创建的 DAG,如图 7.57所示。如果没有看到,请刷新 Airflow 页面几次。有时,DAG 需要几秒钟才能出现在 UI 中。

图 7.57 – 显示正在运行的 DAG 的气流
DAG 应该会在几分钟内成功。如果确实失败,您需要查看这些步骤以确保您设置了正确的值并且您没有错过任何步骤。
您刚刚使用 Elyra 的图形管道编辑器创建了一个基本的 Airflow DAG。默认情况下,生成的 DAG 配置为仅运行一次,由@once注释指示。在现实世界中,您可能不想直接从 Elyra 运行 DAG。您可能想要向 DAG 文件添加其他自定义项。在这种情况下,而不是运行 DAG通过单击播放按钮,使用导出功能。这会将管道导出到 DAG 文件中,您可以进一步自定义该文件,例如设置计划。然后,您可以将自定义的 DAG 文件推送到 DAG 存储库以将其提交给 Airflow。
您刚刚验证了您的 Airflow 设置,添加了 Airflow 运行时配置,并将 Elyra 与 Airflow 集成。现在是时候构建一个真正的部署管道了!
在 Airflow 中自动化 ML 模型部署
你有见过在前面的部分中,如何手动将 ML 模型打包到 Kubernetes 上运行的 HTTP 服务中。您还了解了如何在 Airflow 中创建和运行基本管道。在本节中,您将通过创建 Airflow DAG 来自动化模型部署过程,从而将这些新知识放在一起。您将创建一个简单的 Airflow 管道,用于从以下位置打包和部署 ML 模型这MLflow 模型注册到 Kubernetes。
使用管道编辑器创建管道
类似于在上一节中,您将使用 Elyra 的管道编辑器来创建模型构建和部署 DAG:
1.如果您没有正在运行的 Elyra 环境,请通过导航到 JupyterHub,单击Start My Server并选择要运行的笔记本图像来启动笔记本环境,如图 7.45所示。让我们使用Base Elyra Notebook Image,因为这一次,我们不需要任何特殊的库。
2.在您的 Elyra 浏览器中,导航到Machine-Learning-on-Kubernetes/chapter7/model_deploy_pipeline/目录。
3.打开一个新的管道编辑器。您可以通过选择菜单项File>New>Pipeline Editor来执行此操作,如图 7.46所示。左侧浏览器中将出现一个名为untitled.pipeline的新文件。
4.右键单击untitled.pipeline文件并将其重命名为model_deploy.pipeline。您的目录结构应该类似于图 7.58中的屏幕截图:
图 7.58 – Elyra 显示空的管道编辑器
5.你会构建一个包含两个任务的管道。第一个任务将从 MLflow 模型注册表中提取模型工件,使用 Seldon 核心将模型打包为容器,然后将容器映像推送到映像存储库。要创建第一个任务,请将build_push_image.py文件从model_build_push目录拖放到管道编辑器的工作区。此操作将在管道编辑器窗口中创建一个新任务,如图 7.59所示:
图 7.59 - 显示 build_push_image 任务的 Elyra 管道编辑器
6.第二任务将从镜像存储库中提取容器镜像并将其部署到 Kubernetes。通过将deploy_model.py文件从model_deploy 目录拖放到管道编辑器工作区中来创建第二个任务。此操作将在管道编辑器中创建第二个任务,如图 7.60所示:
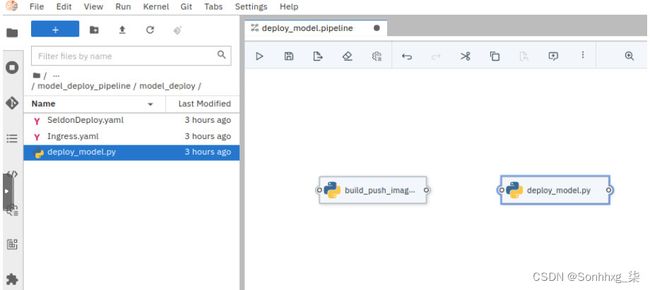
图 7.60 - 显示 deploy_model 任务的 Elyra 管道编辑器
7.连接通过将build_push_image.py任务右侧的小圆圈拖动到deploy_model.py任务框来执行两个任务。任务拓扑应该如图 7.61 所示。记下红色框中突出显示的箭头的方向。

图 7.61 – DAG 的任务拓扑
8.通过右键单击该框并选择Properties来配置build_push_image.py任务。编辑器右侧会出现一个属性面板,如图 7.62所示。选择Kaniko Container Builder作为此任务的运行时映像。

图 7.62 – 带有显示 Kaniko Builder 运行时属性面板的管道编辑器
9.添加文件通过单击“添加依赖项”按钮并选择以下文件,将依赖项添加到build_push_image.py 。此任务的文件依赖关系也显示在图 7.62中。以下列表描述了每个文件的作用:
- Dockerfile – 这是构建的 Docker 文件,用于生成包含 ML 模型和 Predictor Python 文件的容器映像。
- Predictor.py – 这是 Seldon 用来定义推理图的 Python 文件。您已在上一节中看到此文件。
- Base_requirements.txt – 这是一个常规文本文件,其中包含运行此模型所需的 Python 包列表。这由Docker 文件中的pip install命令使用。
10.此时,您应该对整个管道的功能有所了解。因为管道需要将容器映像推送到注册表,所以您需要一个容器注册表来保存您的 ML 模型容器。在您选择的容器注册表中创建一个新存储库。对于本书中的练习,我们将使用Docker Hub作为示例。我们假设您知道如何在https://hub.docker.com中创建新的存储库。将此新存储库称为 mlflowdemo。
11.创建镜像存储库后,为build_push_image.py任务设置环境变量,如图 7.63所示。以下是您需要设置的六个变量:
- MODEL_NAME是在 MLflow 中注册的 ML 模型的名称。您在前面的部分中使用了名称mlflowdemo 。将此变量的值设置为mlflowdemo。
- MODEL_VERSION是在 MLflow 中注册的 ML 模型的版本号。放此变量的值为1。
- CONTAINER_REGISTRY是容器注册表 API 端点。对于 Docker Hub,可在Docker Hub获得。将此变量的值设置为https://index.docker.io/v1/。
- CONTAINER_REGISTRY_USER是将图像推送到图像注册表的用户的用户名。将此设置为您的 Docker Hub 用户名。
- CONTAINER_REGISTRY_PASSWORD是 Docker Hub 用户的密码。在生产中,您不想这样做。您可以使用秘密管理工具来提供您的 Docker Hub 密码。但是,为了简化本练习,您将 Docker Hub 密码作为环境变量。
- CONTAINER_DETAILS是图像将被推送到的存储库的名称,以及图像的名称和标签。这包括您的用户名/mlflowdemo:latestv格式的 Docker Hub 用户名。
通过单击管道编辑器顶部工具栏中的保存图标来保存更改:

图 7.63 – build_push_image.py 任务的示例环境变量
12.配置deploy_model.py任务,通过设置运行时镜像、文件依赖和环境变量,如图 7.64所示。您需要设置四个环境变量,如下表所示:
- MODEL_NAME是在 MLflow 中注册的 ML 模型的名称。您在前面的部分中使用了名称mlflowdemo 。将此变量的值设置为mlflowdemo。
- MODEL_VERSION是在 MLflow 中注册的 ML 模型的版本号。将此变量的值设置为1。
- CONTAINER_DETAILS是将图像推送到的存储库的名称以及图像名称和标记。这包括your-username/mlflowdemo:latest格式的 Docker Hub 用户名。
- CLUSTER_DOMAIN_NAME是您的 Kubernetes 集群的 DNS 名称,在本例中为 Minikube 的 IP 地址,即
.nip.io 。例如,如果minikube ip命令的响应为192.168.49.2,则集群域名为192.168.49.2.nip.io。这用于配置 ML 模型 HTTP 服务的入口,使其可在 Kubernetes 集群外部访问。
保存通过单击管道编辑器顶部工具栏中的保存图标进行更改。
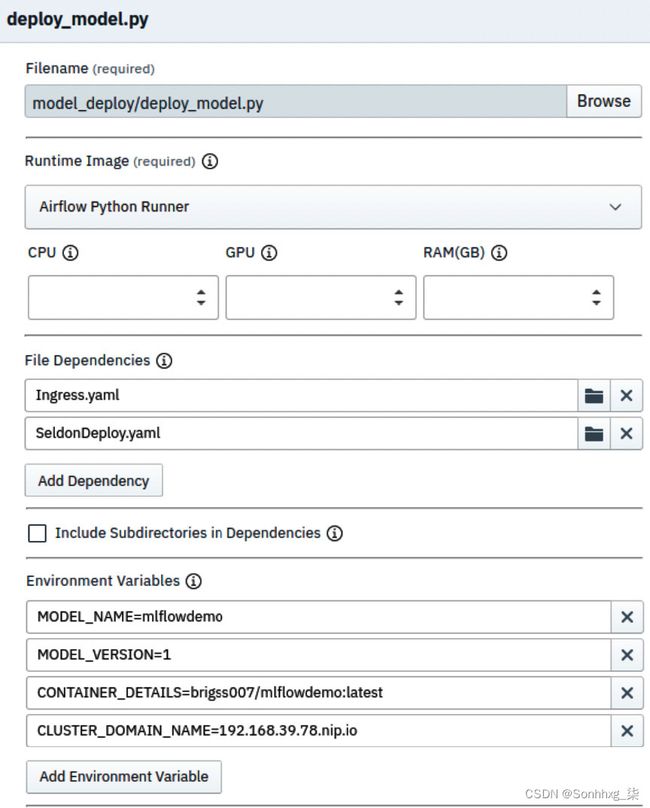
图 7.64 – deploy_model.py 任务的属性
13.您现在已准备好运行管道。从管道编辑器的顶部工具栏中点击Play按钮。这将打开运行管道对话框,如图 7.65所示。在Runtime Platform下选择Apache Airflow 运行时,在Runtime Configuration下选择MyAirflow。单击确定按钮。这将生成 Airflow DAG Python 文件并将其推送到 Git 存储库。
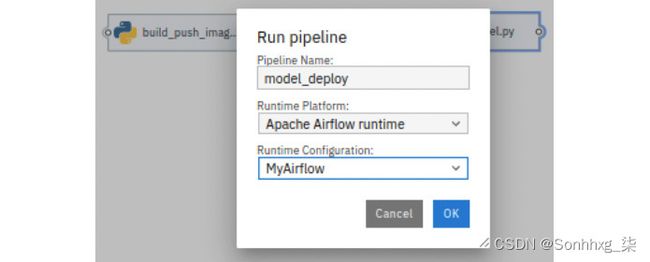
图 7.65 – 运行管道对话框
14.一旦DAG 成功生成并推送到git存储库,您应该会看到如图 7.66所示的对话框。单击确定。
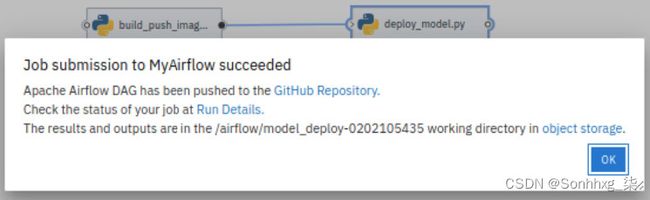
图 7.66 – DAG 提交确认对话框
15.导航到 Airflow 的 GUI。你应该会看到一个新的 DAG,标记为model_deploy-some-number,出现在 DAG 表中,它应该很快就会开始运行,如图 7.67所示。作业的薄荷绿色表示它当前正在运行。深绿色表示成功。
笔记
如果您没有看到新的 DAG,请刷新页面,直到看到为止。Airflow 可能需要几秒钟才能与 Git 存储库同步。
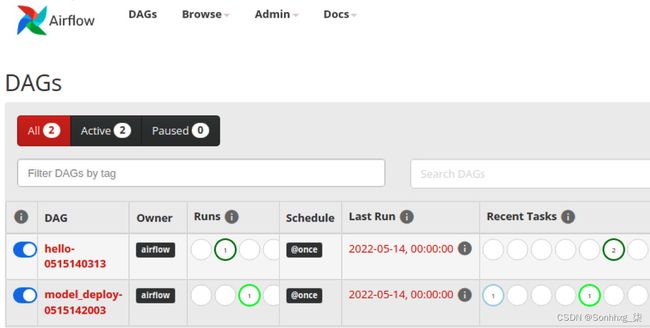
图 7.67 – 显示 model_deploy DAG 的 Airflow GUI
16.同时,你可以通过单击 DAG 名称并选择Graph View选项卡来探索 DAG。它应该显示您在 Elyra 的管道编辑器中设计的任务拓扑,如图 7.68所示。您可以通过选择<> 代码选项卡进一步探索 DAG 。这将显示生成的 DAG 源代码。
图 7.68 – Airflow 中 model_deploy DAG 的图表视图
17.经过几次分钟,作业应该会成功,您应该会看到Graph View中所有任务的轮廓变为深绿色。您还可以通过查看 Kubernetes 中的 pod 来探索这些任务。运行以下命令,您应该会看到两个状态为Completed的 Pod,如图 7.69所示。这些 pod 是管道中已成功执行的两个任务:
kubectl 获取 pods -n ml-workshop\
您应该看到以下响应:
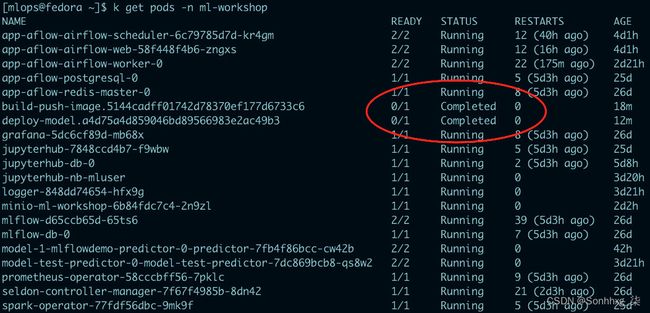
图 7.69 – 具有 Completed 状态的 Kubernetes pod
您刚刚使用 Elyra 的管道编辑器 Seldon Core 创建了一个完整的 ML 模型构建和部署管道,由 Airflow 编排并部署到 Kubernetes。
Seldon Core 和 Airflow 是大型工具,具有更多我们尚未涵盖的功能,并且本书不会完全涵盖。我们为您提供了必要的知识和技能,让您可以开始进一步探索这些工具作为您的 ML 平台的一部分。
概括
恭喜!你做到了这一步!
到目前为止,您已经看到并使用了 JupyterHub、Elyra、Apache Spark、MLflow、Apache Airflow、Seldon Core 和 Kubernetes。您已经了解了这些工具如何解决 MLOps 试图解决的问题。而且,您已经看到所有这些工具在 Kubernetes 上运行良好。
我们想在平台上向您展示更多的东西。但是,我们只能写这么多,因为您看到的每个工具的功能都足以填满整本书。
在下一章中,我们将退后一步,看看到目前为止所构建的大图。然后,您将开始在示例用例上端到端使用平台。在接下来的章节中,您将扮演不同的角色,例如数据科学家、ML 工程师、数据工程师和 DevOps 人员。