stata常用命令汇总——自用备查
‘将字符型转为数值,例如将行业分类变为数字编码、省份变为数值:
encode var, gen(var1)
有时,直接编码不能满足需求,例如要根据行业分类第一字母分类,C类行业根据前两个字符转变为数值,此时的代码为:
gen Ind = Indcd replace Ind = substr(Indcd,1,1) if substr(Indcd,1,1)!="C" replace Ind = substr(Indcd,1,2) if substr(Indcd,1,1)=="C"
encode Ind,gen(industry)
截取字符串的部分,例如经常建立年份,需要截取日期的前四个字符:
gen var1 = substr(var,1,4)
将所有空值全部替换成0值:
一个个变量replace 很麻烦,可以用以下简便方法
| mvencode _all, mv(0) |
如果使用上述命令,仍有一部分缺失值并未替换成0,可用下述命令强制转换
mvencode _all, mv(0) override
把字符串的日期格式转换为date格式
首先,CSMAR上下载的很多默认是“2020-05-21”这种格式,显然是date()函数不能识别的,首先要转换成“month\day\year”的格式
gen Year = substr(TradingDate ,1,4)
gen month = substr(TradingDate,6,7 )
replace month = substr(month,1,2 )
gen day = substr(TradingDate ,9,10)
gen Date = "month" + "/" + day + "/" + Year
gen date_back = date(Date,"MDY")
format date_back %td
导入excel,通常前两行是变量名称和单位,需要删掉:
drop in 1/2
将str格式转变为int或long格式:
destring var1 var2,replace
合并两个数据集merge:
merge 1:1 Stkcd year using "目录路径\数据.dta"
不生成_merge变量,并且保留_merge
merge 1:1 Stkcd year using "目录路径\数据.dta",keep(1 3) nogen
判断字符串有没有包含特定字符,例如筛选出年报,则日期要包含‘12-31’:
keep if strmatch(var, "*12-31*")
把类型转换成int:
recast int Year
排序(sort,gsort):
sort命令:在STATA中对观测值(行)根据特定变量进行升序排序。
gsort命令:在STATA中对观测值(行)进行升序或降序排列(多变量时可以是升序和降序的组合)。
sort完整代码:
sort varlist gsort完整代码:
gsort [+|-] varname [[+|-] varname ...] [, g(newvar) m]- [+|-]:[+]为升序,[-]为降序,默认升序;
- varname:排序依据的变量;
- [generate(newvar)]:生成表示排序顺序的新变量(1, 2, 3, ...)
- [mfirst]:missing first,将缺失值排在最前面,默认为排在最后
根据某一分隔符进行分割成多个变量:
split date,parse(", "" ") gen(ndate) notrim //根据,和空格进行分割
OLS或者固定效应模型后生成残差
predict e,residual
缩尾、截尾(Winsor2)
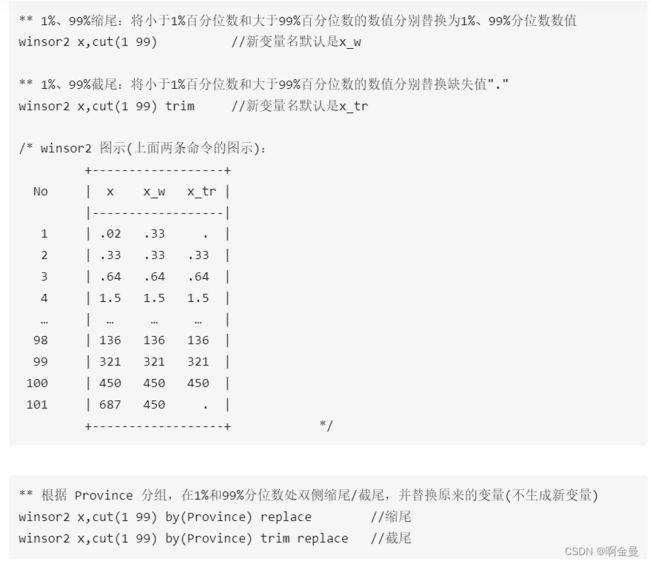
剔除前20%的数据(需要先排序)
egen p20 = pctile(invest), p(20)
egen p80 = pctile(invest), p(80)
N等分(来源:Stata将数值型变量N等分的几种方式 (baidu.com)
举例,已知各地GDP,想按照GDP将城市分为好中差三类。
转化为Stata任务:已经有变量GDP,根据GDP的值从小到大分三类生成变量type
Stata有三种实现方式,略有差异
1. 命令 egen 结合函数cut
egen type = cut(GDP), group(3)
N等分就选择group(N)
得到type取值为0、1、2
2. 命令generate 结合命令sort与函数group
sort GDP
generate type = group(3)
N等分就选择group(N),要先sort再生成,如果想从大到小排列则用 gsort -GDP
得到type取值为1、2、3
3. 外部命令astile
astile type = GDP, nq(3)
N等分就选择nq(N)
得到type的取值为1、2、3
注意:astile命令需要另外下载,ssc install astile, replace
有条件的计数:
count if price > 500
bys industry year: egen x = count(var) if var>= 0
删除重复值
duplicates drop Stkcd Year,force
长面板变短面板——reshape
有时省份等宏观层面的数据往往是以地区为行、年份为列,而经常的情况是我们需要面板数据:
参考链接:如何把国家统计局地区分省年度数据快速整理成省级面板数据 - 简书
互助问答第22期:在stata中将截面数据转为面板数据 - 知乎 (zhihu.com)
首先了解stata里面的reshape命令:

运用reshape语句时,重点就是对long和wide型数据中i和j的认识。回到图1,找到i,j,stub三要素。①Wide form中的id就是i;②inc80、inc81、inc82随时间变化的变量就是stub&j;③sex与id保持对应,不随j(时间)变化,不需要在代码中反映。
于是可以用 reshape long的语句将截面数据变为面板数据,wide form中i(id)变为long form中的i(id),sex与i自动保持一致,stub&j拆分为stub(inc)和j(year)。
reshape long inc, i(id) j(year)
*local i = A[2]
local i = substr(A[2],10,.) //提取数据指标:地区生产总值。
dis "`i'"
keep in 5/35 //保存5-35行数据
renvars B-U \ a2018 a2017 a2016 a2015 a2014 a2013 a2012 a2011
a2010 a2009 a2008 a2007 a2006 a2005 a2004 a2003 a2002
a2001 a2000 a1999 //变量重命名
gen id = _n
reshape long a, i(id) j(year) //把宽数据转为长数据
label variable a "`i'" //添加标签“地区生产总值”