基于BiLSTM+CRF的医疗领域命名实体识别
文章目录
- 1. 数据介绍
- 2. 项目任务
-
-
- 2.1 数据标注
- 2.2 数据预处理
- 2.3 网络搭建
- 2.4 损失函数
- 2.5 推理解码(预测)
-
- 3. 训练模型
-
-
- 3.1 模型评估指标
- 3.2 其他训练技巧
-
- 4. 结果
1. 数据介绍
原始数据集主要包括病例和医疗命名实体字典, 病例数据如下图所示,每份病例都存储在一个txt文件中

医疗命名实体字典如下所示

2. 项目任务
2.1 数据标注
本次使用双向最大匹配+实体词典进行实体自动标注;具体过程参考:双向最大匹配和实体标注:你以为我只能分词? 采用的实体标注格式为BIO;BIO格式就是说,对于实体词,第一个字标注为B,其他的字标注为I;对于非实体词,每个字都标注为O
补充:前向最大匹配法原理
(1)计算词典中实体的最大长度,作为截取句子片段的最大长度
(2)对句子进行分词和标注的一个原则是:单个词(实体)的长度尽可能大。所以会先按最大长度从句子中截取片段,去词典中匹配,匹配中了,就切分出来
(3)按最大长度匹配不中,那么最大长度减一,再去截取句子片段,去词典中匹配,直到匹配中,或者截取的长度减小至一
注意:前向匹配是指从左向右匹配,后向指从右向左
例:
假设句子为:我最近双下肢疼痛,我该咋办,句子中有个两个实体,出现在实体词典中:双下肢疼痛、疼痛,假设实体词典中的最大长度为10



双向最大匹配就是,将前向最大匹配的切分结果,和后向最大匹配的结果进行比较,按一定的规则选择其一作为最终的结果
(1)如果前向和后向切分结果的词数不同,则取词数较少的那个
(2)如果词数相同 :(a)切分结果相同,则返回任意一个;(b)切分结果不同,则返回单字较少的那个
数据标注任务的分析
双向最大匹配算法不仅可以用于分词,也可以用于序列标注,速度快且准确率高,不会分出奇怪的词或实体,但也难以正确处理未登录词。由于完全依赖词典,通用性不强,所以比较适用于处理具体领域的任务,比如医疗领域
2.2 数据预处理
关于数据
标注好的医疗实体数据集,训练集、验证集和测试集的数量分别为:101218 / 7827 / 16804,医疗实体有15类:
数据如下形式:
预处理
(1)首先将标注好的数据集,整理成样本,每个样本是一个句子; 即将上面格式整理成如下列表形式
[[['无', 'O'], ['长', 'B-Dur'], ['期', 'I-Dur'], ['0', 'O'], ['0', 'O'], ['0', 'O'], ['年', 'O']], [样本2]]
(2)将IOB格式转换成IOBES格式【IOBES这种标记方式按道理是更好的,因为提供了更丰富的信息,用特定的符号来标记开头和结尾,便于在预测时提取实体】
(3)建立字与id的映射,标签与id的映射, 将样本转换成id,最后进行词嵌入
(4)其他处理:(a)对句子进行分词后,提取的词长度特征,作为字向量特征的补充,每个字的长度特征为0~3的一个id,后面我们把这个id处理为20维的向量,和100维的字向量进行拼接,得到120维的向量。(b)构造batch时采用桶机制,可以加快训练速度
句子:
"循环系统由心脏、血管和调节血液循环的神经体液组织构成"
分词结果:
['循环系统', '由', '心脏', '、', '血管', '和', '调节', '血液循环', '的', '神经', '体液', '组织', '构成']
长度特征:
[1, 2, 2, 3, 0, 1, 3, 0, 1, 3, 0, 1, 3, 1, 2, 2, 3, 0, 1, 3, 1, 3, 1, 3, 1, 3]
数据处理参考:BiLSTM+CRF命名实体识别:达观杯败走记(上篇)
2.3 网络搭建
总体网络结构:embedding层—BiLSTM层—Linear层—CRF层

embedding层
将预训练的100维字向量和20维的词的长度特征向量拼接构成120的向量送入BiLSTM层中
BiLSTM层和Linear层
BiLSTM中隐层神经源个数为128, BiLSTM的输出为[seq_length, batchsize, 2*num_hidden], 后接全连接网络[2*num_hidden, num_tags], 输出为[seq_length, batchsize, num_tags]
BiLSTM的输入是词嵌入,输出是输入序列每个词的对应各个标注的分数,如下图所示:
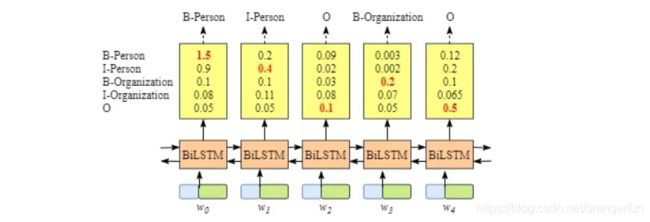
可以发现,可以直接用BiLSTM命名实体识别模型,即每次选择输出分数最高的标签作为当前词的标注。当时这样有可能会出现部分明显的错误,比如O后面接I-Person或B-Person后接I-Organization等。
其实LSTM的输出就是CRF的发射矩阵(emmisions)
CRF层
CRF层可以向最终的预测标签添加一些约束,以确保它们是有效的。这些约束可以由CRF层在训练过程中从训练数据集自动学习, CRF层训练的就是找到transition矩阵
关于网络模型具体参见:
BiLSTM上的CRF,用命名实体识别任务来解释CRF(1)
BiLSTM+CRF命名实体识别:达观杯败走记(下篇)
2.4 损失函数
CRF损失函数由真实路径得分和所有可能路径的总得分组成。在所有可能的路径中,真实路径的得分应该是最高的。
l o s s = P r e a l P 1 + P 2 + . . . P n loss = \frac{P_{real}}{P_1+P_2+...P_n} loss=P1+P2+...PnPreal
当我们训练一个模型时,通常我们的目标是最小化我们的损失函数,因此变成如下形式
l o s s = − l o g P r e a l P 1 + P 2 + . . . P n loss =-log \frac{P_{real}}{P_1+P_2+...P_n} loss=−logP1+P2+...PnPreal
真实路径 P r e a l P_{real} Preal很好算,只需将emission矩阵和transition矩阵中得分相加即可
难点在于如何计算所有路径得分总和,一种方法是列举出所有路径,然后分别计算分数,最后相加,此法复杂度太高
另一种方法是使用类似动态规划的思想,先计算 w 0 w_0 w0的所有可能路径的总分。然后,我们用总分来计算 w 0 → w 1 w_0→w_1 w0→w1。最后,我们使用最新的总分来计算 w 0 → w 1 → w 2 w_0→w_1→w_2 w0→w1→w2。我们需要的是最后的总分。
具体参见:
BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数
2.5 推理解码(预测)
模型训练好了后使用维特比算法进行解码,总体思路和上面的计算总体路径得分差不多,在每个迭代中,存储以每个标签为结尾的路径的最大得分,中间加入了 a l p h a 0 alpha_0 alpha0和 a l p h a 1 alpha_1 alpha1两个变量来记录每个标签和索引的最大得分
具体参见:
BiLSTM上的CRF,用命名实体识别任务来解释CRF(3)推理
3. 训练模型
3.1 模型评估指标
使用了两种评估指标,分别是
(1)基于所有token标签的评测
基于所有token标签的评测,是一种宽松匹配的方法,就是把所有测试样本的真实标签展成一个列表,把预测标签也展成一个列表,然后直接计算Precision、Recall和F1值
(2)考虑实体边界+实体类型的评测
考虑实体边界和实体类型的评测方法,是一种精准匹配的方法,只有当实体边界和实体类别同时被标记正确,才能认为实体识别正确, 本次使用的是CoNLL-2000的一个评估脚本 来评估
3.2 其他训练技巧
用F1宏平均作为early stop的监控指标,同时使用了学习率衰减和梯度截断
4. 结果
测试集上F1宏平均为0.976,验证集上最好的F1值为0.9784