VS2019 C++调用pytorch Faster-RCNN全过程(Libtorch+opencv)
前言
目标检测网络根据阶段数主要有one-stage和two-stage两大类。
one-stage:直接通过调整先验框得到预测框 (速度更快)
two-stage:先生成建议框,再通过调整建议框得到预测框 (精度更高)
此前我们已经通过Darknet成功实现了在C++中调用one-stage的网络模型YOLO-V3(☞vs2019使用Darknet调用YOLOV3模型并测试(CPU+GPU))。
Faster-RCNN,是two-stage模型中较为经典的网络,本博客将介绍如何通过使用Libtorch实现在C++中调用 Faster-RCNN进行检测。
本博客使用的源代码是来自于bubbliiiing大佬。具体实现过程为博主自主摸索实现,可能比较笨,但至少是能够实现目标的。仅供大家参考,欢迎大家积极讨论交流。
实现
1 模型转换(.pth->.pt)
注意:
faster-rcnn中nms、Roi-pool等操作无法用LIbtorch实现,故无法直接将模型一次导出。
为解决这一问题,可将模型的整体检测代码分为两大部分,分别是可通过libtorch序列化导出的和只能利用C++实现的部分。

分批次导出可序列化部分,再配合C++端的代码,实现完整检测过程。
模型准备
加载模型,导入权值,进入eval模式。

1:num_classes
"predict":预测模式
"resnet50":主干特征提取网络
.pth:训练好的模型权值文件
Backbone导出(所有导出过程建议在CPU上运行,以免后续出现错误)
(1)删除网络其他部分,仅保留主干特征提取

(2)修改模型forward()(nets\frcnn中)

(3)序列化模型,保存生成的backbone.pt

**600*750为输入模型的图像尺寸大小**,应根据自身情况设定(通过打断点调试查看输出)
![]()
卷积部分导出
(1)删除网络其他部分,仅保留三次卷积部分

(2)修改模型forward()(nets\frcnn中)

(3)修改rpn中的generate_anchor_base()(rpn.py中)
为方便后续计算,将其输出修改为Tensor类型


(4)修改rpn中的forward()(rpn.py中)

anchor= ....... ,以下的代码全部注释掉(建议框生成部分需在C++中实现)
修改返回参数列表为:rpn_locs, rpn_fg_scores, anchor
(5)修改_enumerate_shifted_anchor()(rpn.py中)
anchor_base已修改为Tensor类型,故对应计算应相应做出调整。

(6)序列化模型,保存生成的rpn.pt

1*1024*38*47为主干特征提取后输出的特征层的size,应根据自身情况设定
ROIhead导出
(1)删除网络其他部分,仅保留 ROIhead部分

(2)修改模型forward()(nets\frcnn中)

(3)修改head中的forward()(classifier.py中)
注释掉ROIPool部分(需利用C++实现),直接假设其输出的结果为head的输入
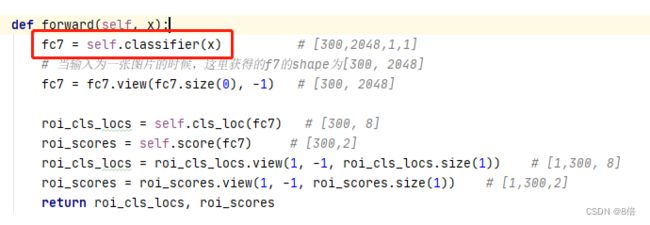
(4)序列化模型,保存生成的roihead.pt

300*1024*14*14为ROIpool后输出的tensor的size,应根据自身情况设定
2 C++部署
libtorch导入PT模型
const string model_path1 = "backbone.pt";
const string model_path2 = "rpn.pt";
const string model_path3 = "roihead.pt";
torch::jit::script::Module module1, module2, module3;
try
{
module1 = torch::jit::load(model_path1);
module2 = torch::jit::load(model_path2);
module3 = torch::jit::load(model_path3);
}
catch (const c10::Error& e)
{
std::cerr << "模型导入失败..\n";
exit(-1);
}
std::cout << "模型导入成功\n";
module1.eval(); //模型测试模式(关闭bn和dropout)
module2.eval();
module3.eval();
利用回归参数信息生成建议框信息 (loc2bbox)
具体过程就是按照python代码,在C++端对应实现,这里我就直接给出,有兴趣的可以具体看看。(求,)
torch::Tensor loc2bbox(torch::Tensor src_bbox, torch::Tensor loc, c10::DeviceType device)
{
if (src_bbox.sizes()[0] == 0)
{
return torch::zeros((0, 4));
}
at::Tensor src_width = torch::unsqueeze(src_bbox.index({ at::indexing::Slice(), 2 }) - src_bbox.index({ at::indexing::Slice(), 0 }), -1);
at::Tensor src_height = torch::unsqueeze(src_bbox.index({ at::indexing::Slice(), 3 }) - src_bbox.index({ at::indexing::Slice(),1 }), -1);
auto src_ctr_x = torch::unsqueeze(src_bbox.index({ at::indexing::Slice(), 0 }), -1) + 0.5 * src_width;
auto src_ctr_y = torch::unsqueeze(src_bbox.index({ at::indexing::Slice(), 1 }), -1) + 0.5 * src_height;
auto dx = loc.index({ at::indexing::Slice(), 0 }).unsqueeze(-1);
auto dy = loc.index({ at::indexing::Slice(), 1 }).unsqueeze(-1);
auto dw = loc.index({ at::indexing::Slice(), 2 }).unsqueeze(-1);
auto dh = loc.index({ at::indexing::Slice(), 3 }).unsqueeze(-1);
auto ctr_x = dx * src_width + src_ctr_x; //中心坐标
auto ctr_y = dy * src_height + src_ctr_y;
auto w = torch::exp(dw) * src_width; //宽高信息
auto h = torch::exp(dh) * src_height;
auto dst_bbox = torch::zeros_like(loc).to(device); //[n,4]
dst_bbox.index({ at::indexing::Slice(), 0 }).unsqueeze(-1) = ctr_x - 0.5 * w;
dst_bbox.index({ at::indexing::Slice(), 1 }).unsqueeze(-1) = ctr_y - 0.5 * h;
dst_bbox.index({ at::indexing::Slice(), 2 }).unsqueeze(-1) = ctr_x + 0.5 * w;
dst_bbox.index({ at::indexing::Slice(), 3 }).unsqueeze(-1) = ctr_y + 0.5 * h;
return dst_bbox;
}
非极大值抑制 (nms_cpu)
这里的nms.cpp用的是MMCV库中自带的文件。可在anaconda prompt 中安装此库,再在相应位置进行寻找,复制到项目目录下即可。(评论区留下邮箱也可)

注意: 在cpp文件中需做如下修改

==> 使得张量数据在内存中连续分布
此外,在测试的cpp文件中,要对该函数进行声明(注意书写位置)

==> 避免在测试文件中找不到nms_cpu函数标识符
至此,便可以成功使用nms_cpu函数了!(nms和roi_pool的CUDA版本,由于涉及到CUDA加速,相对更复杂,后面有机会将更新进来)
生成最终建议框 (loc2bbox + nms_cpu)
torch::Tensor get_proposals(
torch::Tensor loc,
torch::Tensor score,
torch::Tensor anchor,
const std::vector<int64_t>& img_shape, // (h, w) (600,750)
int nms_pre,
int nms_post,
float nms_thr,
int min_bbox_size,
c10::DeviceType device, //可按需求在GPU实现
float scal=1.0)
{
anchor = anchor.to(device); //必须加赋值对象
auto dst_bbox = loc2bbox(anchor, loc, device); //利用回归参数信息生成建议框
dst_bbox.index({ at::indexing::Slice(), 0 }) = torch::clamp(dst_bbox.index({ at::indexing::Slice(), 0 }), 0, img_shape[1]); //限制建议框超出边界
dst_bbox.index({ at::indexing::Slice(), 1 }) = torch::clamp(dst_bbox.index({ at::indexing::Slice(), 1 }), 0, img_shape[0]);
dst_bbox.index({ at::indexing::Slice(), 2 }) = torch::clamp(dst_bbox.index({ at::indexing::Slice(), 2 }), 0, img_shape[1]);
dst_bbox.index({ at::indexing::Slice(), 3 }) = torch::clamp(dst_bbox.index({ at::indexing::Slice(), 3 }), 0, img_shape[0]);
auto min_size = min_bbox_size * scal; //建议框的宽高的最小值不可以小于min_bbox_size
auto keep = torch::where(((dst_bbox.index({ at::indexing::Slice(), 2 }) - dst_bbox.index({ at::indexing::Slice(), 0 })) >= min_size) & ((dst_bbox.index({ at::indexing::Slice(), 3 }) - dst_bbox.index({ at::indexing::Slice(), 1 })) >= min_size))[0];
dst_bbox = dst_bbox.index({ keep, at::indexing::Slice() }); //[n,4]
score = score.index({ keep }); //n
//根据得分进行排序,取出建议框
auto order = torch::argsort(score, 0, true); //shape:n
//取出排名前nms_pre的框
if (nms_pre > 0)
{
order = order.index({ at::indexing::Slice(0, nms_pre) });
}
dst_bbox = dst_bbox.index({ order, at::indexing::Slice() }); //shape:[nms_pre, 4]
score = score.index({ order }); //shape:nms_pre
//对建议框进行非极大抑制
dst_bbox = dst_bbox.to(torch::kCPU);
score = score.to(torch::kCPU);
auto keep1 = nms_cpu(dst_bbox, score, nms_thr, 0); //CPU实现版
keep1 = keep1.slice(0, 0, nms_post);
dst_bbox = dst_bbox.index({ keep1 }); //得到最终建议框 shape:[300,4]
return dst_bbox;
}
ROI_POOl (ROIPool_forward_cpu)
//由建议框信息进行ROIPolling
auto batch_index = 0 * torch::ones((roi.sizes()[0])); //[300]
int a_size = batch_index.sizes()[0];
auto batch_index1 = batch_index.unsqueeze(-1); //[300,1]
auto rois_feature_map = torch::zeros_like(roi); //[300,4]
rois_feature_map.index({ at::indexing::Slice(), 0 }) = roi.index({ at::indexing::Slice(), 0 }) / img_size[1] * feats.sizes()[3];
rois_feature_map.index({ at::indexing::Slice(), 1 }) = roi.index({ at::indexing::Slice(), 1 }) / img_size[0] * feats.sizes()[2];
rois_feature_map.index({ at::indexing::Slice(), 2 }) = roi.index({ at::indexing::Slice(), 2 }) / img_size[1] * feats.sizes()[3];
rois_feature_map.index({ at::indexing::Slice(), 3 }) = roi.index({ at::indexing::Slice(), 3 }) / img_size[0] * feats.sizes()[2];
auto indices_and_rois = torch::cat({ batch_index1, rois_feature_map }, -1); //[300,5]
tuple<at::Tensor, at::Tensor> pool;
feats = feats.to(torch::kCPU);
pool = ROIPool_forward_cpu(feats , indices_and_rois, 1.0, 14, 14); //[300,1024,14,14]
ROIPool_forward_cpu()的定义在ROIPool_cpu.cpp中给出。ROIPool_cpu.cpp的实现代码如下:
#include
#include
int roi_start_w = round(offset_rois[1] * spatial_scale);
int roi_start_h = round(offset_rois[2] * spatial_scale);
int roi_end_w = round(offset_rois[3] * spatial_scale);
int roi_end_h = round(offset_rois[4] * spatial_scale);
// Force malformed ROIs to be 1x1
int roi_width = std::max(roi_end_w - roi_start_w + 1, 1);
int roi_height = std::max(roi_end_h - roi_start_h + 1, 1);
T bin_size_h = static_cast<T>(roi_height) / static_cast<T>(pooled_height);
T bin_size_w = static_cast<T>(roi_width) / static_cast<T>(pooled_width);
for (int ph = 0; ph < pooled_height; ++ph)
{
//cout << "ph= " << ph << endl;
for (int pw = 0; pw < pooled_width; ++pw)
{
//cout << "pw= " << pw << endl;
/*if (ph == 0 && pw == 0)
{
cout << "ph=0;pw=0;n= " << n << endl;
}*/
int hstart = static_cast<int>(floor(static_cast<T>(ph) * bin_size_h));
int wstart = static_cast<int>(floor(static_cast<T>(pw) * bin_size_w));
int hend = static_cast<int>(ceil(static_cast<T>(ph + 1) * bin_size_h));
int wend = static_cast<int>(ceil(static_cast<T>(pw + 1) * bin_size_w));
// Add roi offsets and clip to input boundaries
hstart = std::min(std::max(hstart + roi_start_h, 0), height);
hend = std::min(std::max(hend + roi_start_h, 0), height);
wstart = std::min(std::max(wstart + roi_start_w, 0), width);
wend = std::min(std::max(wend + roi_start_w, 0), width);
bool is_empty = (hend <= hstart) || (wend <= wstart);
for (int c = 0; c < channels; ++c) {
// Define an empty pooling region to be zero
T maxval = is_empty ? 0 : -FLT_MAX;
// If nothing is pooled, argmax = -1 causes nothing to be backprop'd
int maxidx = -1;
//const T* input_offset2 = input;
//const T* input_offset1 = input + channels * height* width*10;
auto bias = (long(roi_batch_ind) * channels + c) * height * width;
const T* input_offset = input + bias;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
int input_index = h * width + w;
if (input_offset[input_index] > maxval) {
maxval = input_offset[input_index];
maxidx = input_index;
}
}
}
int index = ((n * channels + c) * pooled_height + ph) * pooled_width + pw;
output[index] = maxval;
argmax_data[index] = maxidx;
} // channels
} // pooled_width
} // pooled_height
} // num_rois
}
std::tuple<at::Tensor, at::Tensor> ROIPool_forward_cpu(
const at::Tensor& input,
const at::Tensor& rois,
const float spatial_scale,
const int pooled_height,
const int pooled_width) {
AT_ASSERTM(input.device().is_cpu(), "input must be a CPU tensor");
AT_ASSERTM(rois.device().is_cpu(), "rois must be a CPU tensor");
at::TensorArg input_t{input, "input", 1}, rois_t{rois, "rois", 2};
at::CheckedFrom c = "ROIPool_forward_cpu";
at::checkAllSameType(c, {input_t, rois_t});
int num_rois = rois.size(0);
//cout<
//cout << num_rois << endl;
int channels = input.size(1);
int height = input.size(2);
int width = input.size(3);
at::Tensor output = at::zeros(
{num_rois, channels, pooled_height, pooled_width}, input.options());
at::Tensor argmax = at::zeros(
{num_rois, channels, pooled_height, pooled_width},
input.options().dtype(at::kInt));
if (output.numel() == 0) {
return std::make_tuple(output, argmax);
}
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "ROIPool_forward", [&] {
RoIPoolForward<scalar_t>(
input.contiguous().data_ptr<scalar_t>(), //返回tensor的连续存储的首地址,并且转换为scalar_t *的指针类型
spatial_scale,
channels,
height,
width,
pooled_height,
pooled_width,
rois.contiguous().data_ptr<scalar_t>(),
num_rois,
output.data_ptr<scalar_t>(),
argmax.data_ptr<int>());
});
return std::make_tuple(output, argmax);
}
注意: ROIPool_forward_cpu()也需要在测试cpp文件中声明。

解码预测信息
vector<at::Tensor> decode(torch::Tensor roi_cls_locs1, torch::Tensor roi_scores, torch::Tensor rois, int height, int width, float iou, float conf, int num_classes, c10::DeviceType device)
{
at::Tensor mean = torch::tensor({ 0, 0, 0, 0 }).repeat(2); //[1,8]
at::Tensor std = torch::tensor({ 0.1, 0.1, 0.2, 0.2 }).repeat(2); //[1,8]
//GPU提速
std = std.to(device);
mean = mean.to(device);
rois = rois.to(device);
auto roi_cls_loc = (roi_cls_locs1 * std + mean); //反归一化
roi_cls_loc = roi_cls_loc.view({ -1, num_classes, 4 }); //[300,2,4]
//利用classifier网络的预测结果对建议框进行调整获得预测框
auto roi = rois.view({ -1, 1, 4 }).expand_as(roi_cls_loc); //[300,2,4]
roi = roi.reshape({ -1, 4 }).to(device);
roi_cls_loc = roi_cls_loc.reshape({ -1, 4 }).to(device);
auto cls_bbox = loc2bbox(roi, roi_cls_loc, device); //利用回归参数信息生成预测框 [600,4]
cls_bbox = cls_bbox.view({ -1, (num_classes), 4 }); //[300,2,4]
//防止预测框超出图片范围
cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 0 }) = torch::clamp(cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 0 }), 0, width); //限制预测框超出边界
cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 1 }) = torch::clamp(cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 1 }), 0, height);
cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 2 }) = torch::clamp(cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 2 }), 0, width);
cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 3 }) = torch::clamp(cls_bbox.index({ at::indexing::Slice(), at::indexing::Slice(), 3 }), 0, height);
auto prob = torch::softmax(roi_scores, -1); //[300,2]
at::Tensor class_conf, class_pred;
auto out = torch::max(prob, -1); //返回最高置信度值,及其对应索引(即类别) 返回为是std::tuple<>类型
class_conf = get<0>(out); //[300]
class_pred = get<1>(out); //[300]
//利用置信度进行第一轮筛选
auto conf_mask = (class_conf >= conf); //[300], 内部数据类型为bool
//根据置信度进行预测结果的筛选 (包含正样本框(1)和负样本框(0),仅筛选出得分低的)
cls_bbox = cls_bbox.index({ conf_mask, at::indexing::Slice(), at::indexing::Slice() }); //[n,2,4]
class_conf = class_conf.index({ conf_mask }); //[n]
class_pred = class_pred.index({ conf_mask }); //[n]
//取出正样本框和对应置信度
auto arg_mask = class_pred > 0; //将1=>true 0=>false
auto cls_bbox_l = cls_bbox.index({ arg_mask, 1, at::indexing::Slice() });
auto class_conf_l = class_conf.index({ arg_mask });
vector<at::Tensor> output;
output.reserve(1);
auto size = class_conf_l.sizes()[0]; //若无目标框,则返回空vector
if (size == 0)
{
return output;
}
auto detections_class = torch::cat({ cls_bbox_l, torch::unsqueeze(class_pred.index({ arg_mask }) - 1 , -1).toType(torch::kFloat), torch::unsqueeze(class_conf_l, -1) }, -1); //[n,6]
//非极大抑制
detections_class = detections_class.to(kCPU);
auto keep2 = nms_cpu(detections_class.index({ at::indexing::Slice(), at::indexing::Slice(0,4) }), detections_class.index({ at::indexing::Slice(), -1 }), iou, 0);
at::Tensor outttt = detections_class.index({ keep2 });
output.push_back(outttt);
return output;
}
画框
//若有目标
vector<cv::Rect>boxes; //显示框集合
boxes.clear();
auto num_box = outputs[0].sizes()[0]; //获取预测框个数 n
torch::Tensor bbox = outputs[0]; //[n,6]
for (int i = 0; i < num_box; i++) //对每个待显示框单独处理
{
auto bbbox = bbox.index({ i, at::indexing::Slice(0,4) });
auto label = bbox.index({ i, 4 }).item().toInt();
auto conff = bbox.index({ i, 5 }).item().toFloat();
bool flag = 0;
if (conff > conf)
{
if (!flag) {
flag = 1;
}
}
if (flag)
{
//将位置信息映射到原图
bbbox.index({ 0 }) = (bbbox.index({ 0 })) / inputs_tensor.sizes()[3] * old_width;
bbbox.index({ 2 }) = (bbbox.index({ 2 })) / inputs_tensor.sizes()[3] * old_width;
bbbox.index({ 1 }) = (bbbox.index({ 1 })) / inputs_tensor.sizes()[2] * old_height;
bbbox.index({ 3 }) = (bbbox.index({ 3 })) / inputs_tensor.sizes()[2] * old_height;
//获取左上角和右下角坐标信息
int left = int(bbbox.index({ 0 }).item().toFloat());
int right = int(bbbox.index({ 2 }).item().toFloat());
int top = int(bbbox.index({ 1 }).item().toFloat());
int bot = int(bbbox.index({ 3 }).item().toFloat());
if (left < 0)
{
left = 0;
}
if (right > old_width - 1)
{
right = old_width - 1;
}
if (top < 0)
{
top = 0;
}
if (bot > old_height - 1)
{
bot = old_height - 1;
}
cv::Rect rec_box(left, top, fabs(left - right), fabs(top - bot));
boxes.push_back(rec_box);
}
}
cv::Mat res_img;
image.copyTo(res_img); //拷贝原图
string lable = "object";
int baseLine = 0;
for (int i = 0; i < boxes.size(); i++) //绘制所有预测框
{
cv::rectangle(res_img, boxes[i], cv::Scalar(0, 0, 255), 2); //画框 红色,线宽设置为5
cv::Size labelSize = cv::getTextSize(lable, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
//贴标签
putText(res_img, lable, cv::Point(boxes[i].x + 3, boxes[i].y + 6 + labelSize.height), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 0, 255), 2); //红色,线宽设置为2
}
以上给出了关键函数的实现过程,具体完整的操作仅需组合代码即可。图中序号即为调用顺序。
TIP: 当模型返回值包含多个Tensor时,可以这样获取数据。
//如rpn.pt返回数据
auto feats1 = model2.forward(inputs1).toTuple();
torch::Tensor rpn_locs = feats1->elements()[0].toTensor(); //[1,n,4]
torch::Tensor rpn_fg_scores = feats1->elements()[1].toTensor(); //[1,n]
torch::Tensor anchor = feats1->elements()[2].toTensor(); //[n,4]
---------tbc------------
有用可以点个大拇指哦
【作者有话说】
以上内容仅为博主自主整理分享,很多内容也是来源于网络,若有侵权,请私聊告知
大家有任何问题可在评论区讨论交流~
��������������������
你可能感兴趣的:(c++调用python网络,c++,pytorch,cnn,目标检测)