sklearn机器学习:决策树tree.DecisionTreeClassifier()
sklearn中的决策树分类器
sklearn中的决策树分类器函数,格式如下: sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None,max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None,
class_weight=None, presort=False)
其重要参数介绍如下:
重要参数
criterion
这个参数是用来决定不纯度的计算方法。sklearn提供了两种选择:
- 输入 “entropy”,使用信息熵(Entropy)
- 输入 “gini”,使用基尼系数(Gini Impurity)
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏感,所以信息熵作为指标时,决策树的生长会更加 ”精细”,因此对于高纬数据或者噪声很多的数据,信息熵很容易易过拟合,基尼系数在这种情况下效果往往比较好。当模型拟合程度不足的时候,即当模型在训练集和测试集上都表现不太好的时候,使用信息熵。当然,这些不是绝对的。
综上,对criterion的选择方法总结如下:
- criterion如何影响模型:确定不纯度的计算方法,帮忙找出最佳结点和最佳分支,不纯度越低,决策树对训练集的拟合越好;
- criterion选项:不填默认为基尼系数,填写gini使用基尼系数,填写entropy使用信息增益;
- criterion如何选取参数:通常就使用基尼系数。
数据维度很大,噪音很大时使用基尼系数;
维度低,数据比较清晰的时候,信息熵和基尼系数没区别;
当决策树的拟合程度不够的时候,使用信息熵;
两个都试试,当一个不好用时就换另外一个。
建立一颗树
#Sklearn中实现决策树
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
'''魔法函数%matplotlib inline:
模仿命令行来访问IPython的内置magic函数,
其中:%matplotlib可以使用指定的界面库显示图表,
inline表示将图表嵌入到Notebook中'''
%matplotlib inline
#导入tree算法库
from sklearn import tree
#导入load_wine数据集
from sklearn.datasets import load_wine
#导入train_test_split数据集切分模块
from sklearn.model_selection import train_test_split
#探索数据
wine = load_wine()
#wine.data属性数据体量
wine.data.shape
运行结果
(178, 13)
#wine.target标签数据体量
wine.target.shape
运行结果
(178,)
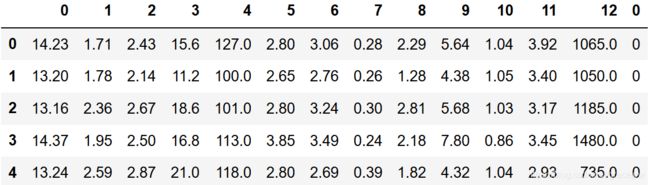
#如果wine是一张表,应该长这样:
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1).head()
运行结果
#查看数据集特征
wine.feature_names
运行结果
['alcohol',
'malic_acid',
'ash',
'alcalinity_of_ash',
'magnesium',
'total_phenols',
'flavanoids',
'nonflavanoid_phenols',
'proanthocyanins',
'color_intensity',
'hue',
'od280/od315_of_diluted_wines',
'proline']
#查看数据集标签
wine.target_names
运行结果
array(['class_0', 'class_1', 'class_2'], dtype=')
#划分训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3,
random_state=420)
Xtrain.shape
运行结果
(124, 13)
Xtest.shape
运行结果
(54, 13)
#建立模型
'''由于sklearn本身的数据集维度低,数据比较清晰,
有拟合程度不够的可能性,所以首先用信息熵尝试'''
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
运行结果
0.9629629629629629
用 Graphviz 画出一棵树
同时,我们可以利用 Graphviz 模块导出决策树模型,第一次使用 Graphviz 之前需要对其进行安装,若是使用从conda进行的Python包管理,则可直接在命令行界面中利用下述指令进行安装:
conda install python-graphviz
#用 Graphviz 画出一棵树
# 设置特征的中文名称
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
#python matplotlib中文显示参数设置
plt.rcParams['font.sans-serif']=['Simhei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#在CMD中执行命令:conda install python-graphviz
import graphviz
'''export_graphviz生成一个DOT格式的决策树:
out_file:输出的dot文件的名字,默认为None表示不输出文件,可以是自定义名字如"tree.dot"
feature_names:每个属性的名字
class_names:每个因变量类别的名字
label:是否显示不纯度信息的标签,默认为"all"表都显示,可以是"root"或"none"
filled:是否给每个结点的主分类绘制不同的颜色,默认为False
rounded:默认为Ture,表示对每个结点的边框加圆角,并使用Helvetica字体
更多参数说明查看(https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html#sklearn.tree.export_graphviz)
'''
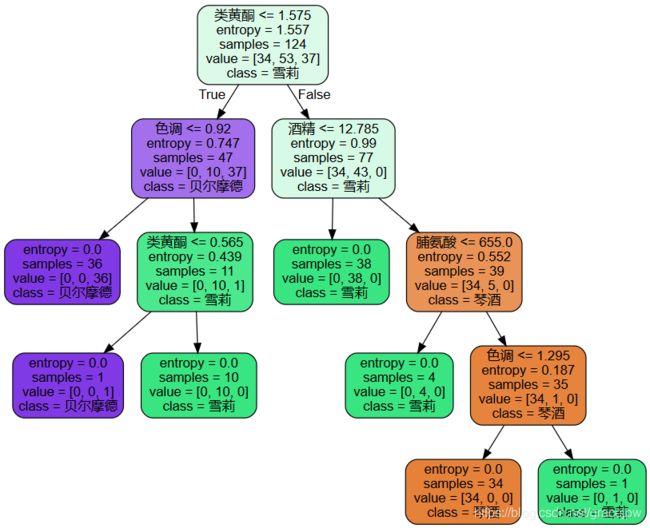
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
运行结果
#保存⽣生成的图形
graph.render("wine") #生成PDF文件,文件中无法显示中文
#探索决策树
#特征重要性
clf.feature_importances_
运行结果
array([0.2833539 , 0. , 0. , 0.03394088, 0. ,
0. , 0.44822699, 0. , 0. , 0. ,
0.15678488, 0. , 0.07769335])
feature_importances_计算过程:
sklearn.tree.DicisionTreeClassifier类中的feature_importances_属性返回的是特征的重要性,feature_importances_越高代表特征越重要。
feature importance的计算公式
Friedman在GBM[1]的论文中提出的方法:
特征xj在整个模型中的重要程度为:
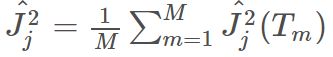
其中,M是模型中树的数量。特征xjxj在单独一个树上的特征重要度为:

其中,L−1是树中非叶子节点数量,vt表示在内部节点t进行分裂时选择的特征, I ^ t 2 \hat{I}_t^2 I^t2是内部节点t分裂后平方损失的减少量。
J. H. Friedman. 2001. Greedy Function Approximation: A
Gradient Boosting Machine. Annals of Statistics 29(5):1189-
1232.
详见原文链接:https://blog.csdn.net/ictcxq/article/details/78754905
#特征重要性列表
[*zip(feature_name,clf.feature_importances_)]
运行结果
[('酒精', 0.2833539000570303),
('苹果酸', 0.0),
('灰', 0.0),
('灰的碱性', 0.03394088285661319),
('镁', 0.0),
('总酚', 0.0),
('类黄酮', 0.4482269945412355),
('非黄烷类酚类', 0.0),
('花青素', 0.0),
('颜色强度', 0.0),
('色调', 0.15678487534816657),
('od280/od315稀释葡萄酒', 0.0),
('脯氨酸', 0.07769334719695445)]