Yolov7训练自己的数据-水果检测
2022年七月Yolov4的原班人马发布了Yolov7,本文记录了博主用Yolov7训练自己的数据的过程
一、下载Yolov7代码
Yolov7源码保存在github:https://github.com/WongKinYiu/yolov7
下载后源码的目录结构如图所示:

1、cfg文件夹

./cfg/training 文件夹中保存了训练时需要的参数,yolov7共提供了7个版本的参数值
2、data文件夹
./data文件夹中保存了训练时需要的文件索引信息
3、train.py 和 train_aux.py
yolov7提供了两种训练文件,如果需要使用较大的预训练权重则需要选择使用train_aux.py训练,否则采用train.py即可
二、使用官方权重检测
我们可以在官网上下载到六个版本的预训练权重
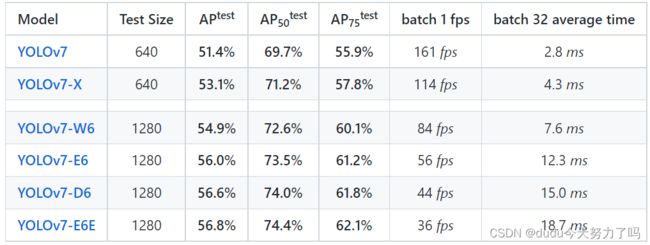
如图所示,不同model有不同的精准度,其中YOLOv7-E6E 的精度最高
Testing中提供了预训练数据的下载路径

将.pt文件下载到根目录E:\yolov7-main后执行代码
python detect.py --weights yolov7-e6e.pt --source --name 'output'
三、使用自己的数据集进行训练
1、准备自己的数据集
我们的数据集格式需要Yolo格式的数据集,分为两部分:images 和 labels
其中images和labels的名称需要一一对应,labels为.txt文件
label格式为五个归一化的数据:label、x_center、y_center、width、height
label_index :为标签名称在标签数组中的索引,下标从 0 开始。
x_center:标记框中心点的 x 坐标,数值是原始中心点 x 坐标除以 图宽 后的结果。
y_center:标记框中心点的 y 坐标,数值是原始中心点 y 坐标除以 图高 后的结果。
width:标记框的 宽,数值为 原始标记框的 宽 除以 图宽 后的结果。
height:标记框的 高,数值为 原始标记框的 高 除以 图高 后的结果。
例如:

2、改写自己的数据集路径和参数路径
① 数据集路径:在./data文件中新建.yaml文件,需要标注train/val/test的路径和nc(总共有几类)
例如:
# this is an apple detection program
train:.\datasets\sets\train.txt
val: .\datasets\sets\val.txt
test: .\datasets\sets\test.txt
depth_multiple: 1.0
width_multiple: 1.0
nc: 1
names: [0]② 参数路径:./cfg/training文件夹中新建.yaml文件,复制其原有的参数,更改nc的个数
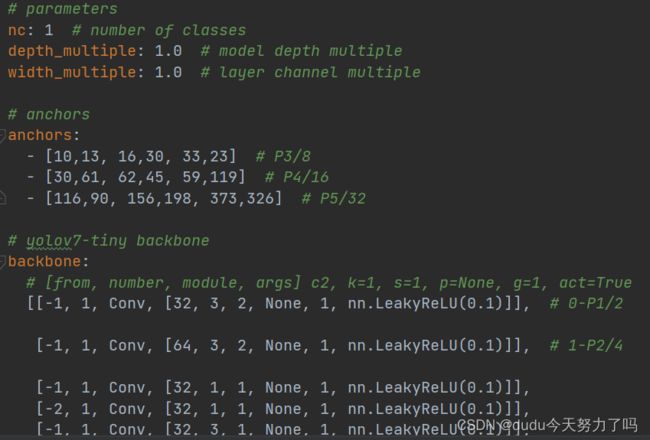
3、开始训练
执行命令即可开始训练
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml训练结束后得到的权重文件将被保存到 .\runs\train 文件夹中
train常用参数有:
--weights: 预训练路径,填写'' 表示不使用预训练权重 --cfg : 参数路径(./cfg/training中新建的.yaml文件,见上文②) --data : 数据集路径(./data中新建的.yaml文件,见上文①) --epochs : 训练轮数 --batch-size : batch大小 --device : 训练设备,cpu-->用cpu训练,0-->用GPU训练,0,1,2,3-->用多核GPU训练 --workers: maximum number of dataloader workers --name : save to project/name
train可用参数:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolo7.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone of yolov7=50, first3=0 1 2')
parser.add_argument('--v5-metric', action='store_true', help='assume maximum recall as 1.0 in AP calculation')
opt = parser.parse_args()4、test
执行命令
python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7.pt --name yolov7_640_val5、detect
执行命令
on video:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
on image:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg输出的结果将被保存到:.\runs\detect文件夹中
常用参数有:
--conf-thres 0.5 :置信阈值object confidence threshold
可用参数有:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov7.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
opt = parser.parse_args()