PyTorch解读:torch.utils.data的数据解析处理
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
知乎 OpenMMLab
小P家的 000607 文仅交流 侵删
https://zhuanlan.zhihu.com/p/345096806
0 前言
1 Dataset
1.1 Map-style dataset
1.2 Iterable-style dataset
1.3 其他 dataset
2 Sampler
3 DataLoader
3.1 三者关系 (Dataset, Sampler, Dataloader)
3.2 批处理
3.2.1 自动批处理(默认)
3.2.2 关闭自动批处理
3.2.3 collate_fn
3.3 多进程处理 (multi-process)
4 单进程
5 多进程
6 锁页内存 (Memory Pinning)
7 预取 (prefetch)
8 代码讲解
0 前言
本文涉及的源码以 PyTorch 1.7 为准。
迭代器
理解 Python 的迭代器是解读 PyTorch 中 torch. utils. data 模块的关键。
在 Dataset, Sampler 和 DataLoader 这三个类中都会用到 python 抽象类的魔法方法,包括__len__(self),__getitem__(self) 和 __iter__(self):
● __len__(self): 定义当被 len() 函数调用时的行为,一般返回迭代器中元素的个数
● __getitem__(self): 定义获取容器中指定元素时的行为,相当于 self[key] ,即允许类对象拥有索引操作
● __iter__(self): 定义当迭代容器中的元素时的行为
迭代的意思类似于循环,每一次重复的过程被称为一次迭代的过程,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。提供迭代方法的容器称为迭代器,通常接触的迭代器有序列(列表、元组和字符串)还有字典,这些数据结构都支持迭代操作。
实现迭代器的魔法方法有两个:
__iter__(self) 和 __next__(self)。
一个容器如果是迭代器,那就必须实现 __iter__(self) 魔法方法,这个方法实际上是返回是一个迭代器(通常是迭代器本身)。接下来重点要实现的是 __next__(self) 魔法方法,因为它决定了迭代的规则。
class Fibs:
def __init__(self, n=20):
self.a = 0
self.b = 1
self.n = n
def __iter__(self):
return self
def __next__(self):
self.a, self.b = self.b, self.a + self.b
if self.a > self.n:
raise StopIteration
return self.a
fibs = Fibs()
for each in fibs:
print(each)
# 输出
# 1 1 2 3 5 8 13
一般来说,迭代器满足以下几种特性:
● 迭代器是⼀个对象
● 迭代器可以被 next() 函数调⽤,并返回⼀个值
● 迭代器可以被 iter() 函数调⽤,并返回一个迭代器(可以是自身)
● 连续被 next() 调⽤时依次返回⼀系列的值
● 如果到了迭代的末尾,则抛出 StopIteration 异常
● 迭代器也可以没有末尾,只要被 next() 调⽤,就⼀定会返回⼀个值
● Python 中,next() 内置函数调⽤的是对象的 next() ⽅法
● Python 中,iter() 内置函数调⽤的是对象的 iter() ⽅法
● ⼀个实现了迭代器协议的的对象可以被 for 语句循环迭代直到终⽌
了解了什么是迭代器后,我们就可以开始解读 torch.utils.data 模块。
对于 torch.utils.data 而言,重点是其 Dataset, Sampler, DataLoader 模块,辅以 collate, fetch, pin_memory 等组件对特定功能予以支持。
1 Dataset
Dataset 负责对 raw data source 封装,将其封装成 Python 可识别的数据结构,其必须提供提取数据个体的接口。
Dataset 共有 Map-style datasets 和 Iterable-style datasets 两种:
1.1 Map-style dataset
torch.utils.data.Dataset
它是一种通过实现__getitem__()和__len()__来获取数据的 Dataset,它表示从(可能是非整数)索引/关键字到数据样本的映射。访问时,这样的数据集用 dataset[idx] 访问 idx对应的数据。
通常我们使用 Map-style 类型的 dataset 居多,其数据接口定义如下:
class Dataset(Generic[T_co]):
# Generic is an Abstract base class for generic types.
def __getitem__(self, index) -> T_co:
raise NotImplementedError
def __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]':
return ConcatDataset([self, other])
PyTorch 中所有定义的 Dataset 都是其子类。
对于一般计算机视觉任务,我们通常会在其中进行一些 resize, crop, flip 等预处理的操作。
值得一提的是,PyTorch 源码中并没有提供默认的 __len__() 方法实现,原因是 return NotImplemented 或者 raise NotImplementedError() 之类的默认实现都会存在各自的问题,这点在其源码中也有注释加以体现。
1.2 Iterable-style dataset
torch.utils.data.IterableDataset
它是一种实现 __iter__() 来获取数据的 Dataset,这种类型的数据集特别适用于以下情况:随机读取代价很大甚至不大可能,且 batch size 取决于获取的数据。其接口定义如下:
class IterableDataset(Dataset[T_co]):
def __iter__(self) -> Iterator[T_co]:
raise NotImplementedError
def __add__(self, other: Dataset[T_co]):
return ChainDataset([self, other])
特别地,当 DataLoader 的 num_workers > 0 时, 每个 worker 都将具有数据对象的不同样本。因此需要独立地对每个副本进行配置,以防止每个 worker 产生的数据不重复。同时,数据加载顺序完全由用户定义的可迭代样式控制。这允许更容易地实现块读取和动态批次大小(例如,通过每次产生一个批次的样本)。
1.3 其他 Dataset
除了 Map-style dataset 和 Iterable-style dataset 以外,PyTorch 也在此基础上提供了其他类型的 Dataset 子类:
● torch.utils.data.ConcatDataset:用于连接多个 ConcatDataset 数据集
● torch.utils.data.ChainDataset:用于连接多个 IterableDataset 数据集,在 IterableDataset 的 __add__() 方法中被调用
● torch.utils.data.Subset:用于获取指定一个索引序列对应的子数据集
class Subset(Dataset[T_co]):
dataset: Dataset[T_co]
indices: Sequence[int]
def __init__(self, dataset: Dataset[T_co], indices: Sequence[int]) -> None:
self.dataset = dataset
self.indices = indices
def __getitem__(self, idx):
return self.dataset[self.indices[idx]]
def __len__(self):
return len(self.indices)
● torch.utils.data.TensorDataset: 用于获取封装成 tensor 的数据集,每一个样本都通过索引张量来获得。
class TensorDataset(Dataset):
def __init__(self, *tensor):
assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)
self.tensors = tensors
def __getitem__(self, index):
return tuple(tensor[index] for tensor in tensors
def __len__(self):
return self.tensors[0].size(0)
2 Sampler
torch.utils.data.Sampler 负责提供一种遍历数据集所有元素索引的方式。可支持用户自定义,也可以用 PyTorch 提供的,基类接口定义如下:
lass Sampler(Generic[T_co]):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an :meth:`__iter__` method, providing a
way to iterate over indices of dataset elements, and a :meth:`__len__` method
that returns the length of the returned iterators.
.. note:: The :meth:`__len__` method isn't strictly required by
:class:`~torch.utils.data.DataLoader`, but is expected in any
calculation involving the length of a :class:`~torch.utils.data.DataLoader`.
"""
def __init__(self, data_source: Optional[Sized]) -> None:
pass
def __iter__(self) -> Iterator[T_co]:
raise NotImplementedError
特别地,__len__() 方法不是必要的,但是当 DataLoader 需要计算 len() 的时候必须定义,这点在其源码中也有注释加以体现。
同样,PyTorch 也在此基础上提供了其他类型的 Sampler 子类。
torch.utils.data.SequentialSampler : 顺序采样样本,始终按照同一个顺序
torch.utils.data.RandomSampler: 可指定有无放回地,进行随机采样样本元素
torch.utils.data.SubsetRandomSampler: 无放回地按照给定的索引列表采样样本元素
torch.utils.data.WeightedRandomSampler: 按照给定的概率来采样样本。样本元素来自 [0,…,len(weights)-1] , 给定概率(权重)
torch.utils.data.BatchSampler: 在一个batch中封装一个其他的采样器, 返回一个 batch 大小的 index 索引
torch.utils.data.DistributedSample: 将数据加载限制为数据集子集的采样器。与 torch.nn.parallel.DistributedDataParallel 结合使用。在这种情况下,每个进程都可以将 DistributedSampler 实例作为 DataLoader 采样器传递
3 DataLoader
torch.utils.data.DataLoader 是 PyTorch 数据加载的核心,负责加载数据,同时支持 Map-style 和 Iterable-style Dataset,支持单进程/多进程,还可以设置 loading order, batch size, pin memory 等加载参数。其接口定义如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
对于每个参数的含义,以下给出一个表格进行对应介绍:

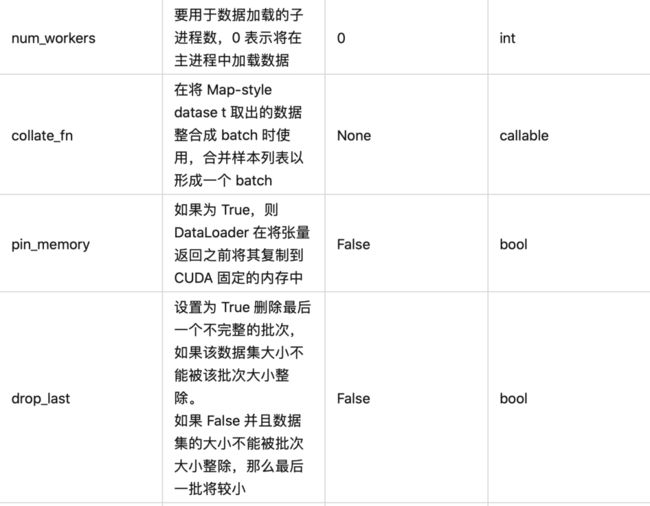

从参数定义中,我们可以看到 DataLoader 主要支持以下几个功能:
● 支持加载 map-style 和 iterable-style 的 dataset,主要涉及到的参数是 dataset
●自定义数据加载顺序,主要涉及到的参数有 shuffle, sampler, batch_sampler, collate_fn
● 自动把数据整理成batch序列,主要涉及到的参数有 batch_size, batch_sampler, collate_fn, drop_last
● 单进程和多进程的数据加载,主要涉及到的参数有 num_workers, worker_init_fn
● 自动进行锁页内存读取 (memory pinning),主要涉及到的参数 pin_memory
● 支持数据预加载,主要涉及的参数 prefetch_factor
3.1 三者关系 (Dataset, Sampler, Dataloader)
通过以上介绍的三者工作内容不难推出其内在关系:
1. 设置 Dataset,将数据 data source 包装成 Dataset 类,暴露提取接口。
2. 设置 Sampler,决定采样方式。我们是能从 Dataset 中提取元素了,还是需要设置 Sampler 告诉程序提取 Dataset 的策略。
3. 将设置好的 Dataset 和 Sampler 传入 DataLoader,同时可以设置 shuffle, batch_size 等参数。使用 DataLoader 对象可以方便快捷地在数据集上遍历。
总结来说,即 Dataloader 负责总的调度,命令 Sampler 定义遍历索引的方式,然后用索引去 Dataset 中提取元素。于是就实现了对给定数据集的遍历。
3.2 批处理
3.2.1 自动批处理(默认)
DataLoader 支持通过参数 batch_size, drop_last, batch_sampler,自动地把取出的数据整理 (collate) 成批次样本 (batch)。
batch_size 和 drop_last 参数用于指定 DataLoader 如何获取 dataset 的 key。特别地,对于 map-style 类型的 dataset,用户可以选择指定 batch_sample参数,一次就生成一个 keys list。
在使用 sampler 产生的 indices 获取采样到的数据时,DataLoader 使用 collate_fn 参数将样本列表整理成 batch。抽象这个过程,其表示方式大致如下:
# For Map-style
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])
# For Iterable-style
dataset_iter = iter(dataset)
for indices in batch_sampler:
yield collate_fn([next(dataset_iter) for _ in indices])
3.2.2 关闭自动批处理
当用户想用 dataset 代码手动处理 batch,或仅加载单个 sample data 时,可将 batch_size 和 batch_sampler 设为 None, 将关闭自动批处理。此时,由 Dataset 产生的 sample 将会直接被 collate_fn 处理。抽象这个过程,其表示方式大致如下:
# For Map-style
for index in sampler:
yield collate_fn(dataset[index])
# For Iterable-style
for data in iter(dataset):
yield collate_fn(data)
3.2.3 collate_fn
当关闭自动批处理 (automatic batching) 时,collate_fn 作用于单个数据样本,只是在 PyTorch 张量中转换 NumPy 数组。
当开启自动批处理 (automatic batching) 时,collate_fn 作用于数据样本列表,将输入样本整理为一个 batch,一般做下面 3 件事情:
● 添加新的批次维度(一般是第一维)
● 它会自动将 NumPy 数组和 Python 数值转换为 PyTorch 张量
● 它保留数据结构,例如,如果每个样本都是 dict,则输出具有相同键集但批处理过的张量作为值的字典(或list,当不能转换的时候)。list, tuples, namedtuples 同样适用。
自定义 collate_fn 可用于自定义排序规则,例如,将顺序数据填充到批处理的最大长度,添加对自定义数据类型的支持等。
3.3 多进程处理 (multi-process)
为了避免在加载数据时阻塞计算代码,PyTorch 提供了一个简单的开关,只需将参数设置 num_workers 为正整数即可执行多进程数据加载,设置为 0 时执行单线程数据加载。
4 单进程
在单进程模式下,DataLoader 初始化的进程和取数据的进程是一样的。因此,数据加载可能会阻止计算。
但是,当用于在进程之间共享数据的资源(例如共享内存,文件描述符)有限时,或者当整个数据集很小并且可以完全加载到内存中时,此模式可能是首选。
此外,单进程加载通常显示更多可读的错误跟踪,因此对于调试很有用。
5 多进程
在多进程模式下,每次 DataLoader 创建 iterator 时(例如,当调用时enumerate(dataloader)),都会创建 num_workers 工作进程。
dataset, collate_fn, worker_init_fn 都会被传到每个worker中,每个worker都用独立的进程。
对于 map-style 数据,主线程会用 Sampler 产生 indice,并将它们送到 worker 里。因此,shuffle是在主线程做的。
对于 iterable-style 数据,因为每个 worker 都有相同的 data 复制样本,并在各个进程里进行不同的操作,以防止每个进程输出的数据是重复的。
所以一般,用torch.utils.data.get_worker_info()来进行辅助处理。
这里torch.utils.data.get_worker_info()返回worker进程的一些信息(id, dataset, num_workers, seed),如果在主线程跑的话返回None。
注意,通常不建议在多进程加载中返回CUDA张量,因为在使用CUDA和在多处理中共享CUDA张量时存在许多微妙之处(文档中提出:只要接收过程保留张量的副本,就需要发送过程来保留原始张量)。建议采用 pin_memory=True ,以将数据快速传输到支持CUDA的GPU。简而言之,不建议在使用多线程的情况下返回CUDA的tensor。
6 锁页内存
这里首先解释一下锁页内存的概念。
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。主机到GPU副本源自固定(页面锁定)内存时,速度要快得多。CPU张量和存储暴露了一种 pin_memory() 方法,该方法返回对象的副本,并将数据放在固定的区域中。
而显卡中的显存全部是锁页内存!当计算机的内存充足的时候,可以设置 pin_memory=True。设置 pin_memory=True,则意味着生成的 Tensor 数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。同时,由于 pin_memory 的作用是将张量返回之前将其复制到 CUDA 固定的内存中,所以只有在 CUDA 环境支持下才有用。
PyTorch 原生的 pin_memory 方法如下,其支持大部分 python 数据类型的处理:
def pin_memory(data):
if isinstance(data, torch.Tensor):
return data.pin_memory()
elif isinstance(data, string_classes):
return data
elif isinstance(data, container_abcs.Mapping):
return {k: pin_memory(sample) for k, sample in data.items()}
elif isinstance(data, tuple) and hasattr(data, '_fields'): # namedtuple
return type(data)(*(pin_memory(sample) for sample in data))
elif isinstance(data, container_abcs.Sequence):
return [pin_memory(sample) for sample in data]
elif hasattr(data, "pin_memory"):
return data.pin_memory()
else:
return data
默认情况下,如果固定逻辑看到一个属于自定义类型 (custom type) 的batch(如果有一个 collate_fn 返回自定义批处理类型的批处理,则会发生),或者如果该批处理的每个元素都是 custom type,则固定逻辑将无法识别它们,它将返回该批处理(或那些元素)而无需固定内存。要为自定义批处理或数据类型启用内存固定,需 pin_memory() 在自定义类型上定义一个方法。如下:
class SimpleCustomBatch:
# 自定义一个类,该类不能被PyTorch原生的pin_memory方法所支持
def __init__(self, data):
transposed_data = list(zip(*data))
self.inp = torch.stack(transposed_data[0], 0)
self.tgt = torch.stack(transposed_data[1], 0)
# custom memory pinning method on custom type
def pin_memory(self):
self.inp = self.inp.pin_memory()
self.tgt = self.tgt.pin_memory()
return self
def collate_wrapper(batch):
return SimpleCustomBatch(batch)
inps = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
tgts = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
dataset = TensorDataset(inps, tgts)
loader = DataLoader(dataset, batch_size=2, collate_fn=collate_wrapper,
pin_memory=True)
for batch_ndx, sample in enumerate(loader):
print(sample.inp.is_pinned()) # True
print(sample.tgt.is_pinned()) # True
7 预取 (prefetch)
DataLoader 通过指定 prefetch_factor (默认为 2)来进行数据的预取。
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
...
self._reset(loader, first_iter=True)
def _reset(self, loader, first_iter=False):
...
# prime the prefetch loop
for _ in range(self._prefetch_factor * self._num_workers):
self._try_put_index()
通过源码可以看到,prefetch 功能仅适用于 多进程 加载中(下面会由多进程 dataloader 的代码分析)。
8 代码详解
让我们来看看具体的代码调用流程:
for data, label in train_loader:
......
for 循环会调用 dataloader 的 __iter__(self) 方法,以此获得迭代器来遍历 dataset:
class DataLoader(Generic[T_co]):
...
def __iter__(self) -> '_BaseDataLoaderIter':
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
在__iter__(self)方法中,dataloader调用了self._get_iterator()方法,根据num_worker获得迭代器,并指示进行单进程还是多进程:
class DataLoader(Generic[T_co]):
...
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
为了描述清晰,我们只考虑单进程的代码。如下:
class _BaseDataLoaderIter(object):
def __init__(self, loader: DataLoader) -> None:
# 初始化赋值一些 DataLoader 参数,
# 以及用户输入合法性进行校验
self._dataset = loader.dataset
self._dataset_kind = loader._dataset_kind
self._index_sampler = loader._index_sampler
...
def __iter__(self) -> '_BaseDataLoaderIter':
return self
def _reset(self, loader, first_iter=False):
self._sampler_iter = iter(self._index_sampler)
self._num_yielded = 0
self._IterableDataset_len_called = loader._IterableDataset_len_called
def _next_index(self):
return next(self._sampler_iter) # may raise StopIteration
def _next_data(self):
raise NotImplementedError
def __next__(self) -> Any:
with torch.autograd.profiler.record_function(self._profile_name):
if self._sampler_iter is None:
self._reset()
data = self._next_data() # 重点代码行,通过此获取数据
self._num_yielded += 1
...
return data
next = __next__ # Python 2 compatibility
def __len__(self) -> int:
return len(self._index_sampler) # len(_BaseDataLoaderIter) == len(self._index_sampler)
def __getstate__(self):
raise NotImplementedError("{} cannot be pickled", self.__class__.__name__)
_BaseDataLoaderIter 是所有 DataLoaderIter 的父类。dataloader获得了迭代器之后,for 循环需要调用 __next__() 来获得下一个对象,从而实现遍历。通过 __next__ 方法调用 _next_data() 获取数据:
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
super(_SingleProcessDataLoaderIter, self).__init__(loader)
assert self._timeout == 0
assert self._num_workers == 0
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
return data
从 _SingleProcessDataLoaderIter 的初始化参数可以看到,其在父类 _BaseDataLoaderIter 的基础上定义了 _dataset_fetcher, 并传入 _dataset, _auto_collation, _collate_fn 等参数,用于定义获取数据的方式。其具体实现会在稍后解释。
在_next_data()被调用后,其需要 next_index() 获取 index,并通过获得的 index 传入 _dataset_fetcher 中获取对应样本:
class DataLoader(Generic[T_co]):
...
@property
def _auto_collation(self):
return self.batch_sampler is not None
@property
def _index_sampler(self):
if self._auto_collation:
return self.batch_sampler
else:
return self.sampler
class _BaseDataLoaderIter(object):
...
def _reset(self, loader, first_iter=False):
self._sampler_iter = iter(self._index_sampler)
...
def _next_index(self):
# sampler_iter 来自于 index_sampler
return next(self._sampler_iter) # may raise StopIteration
从这里看出,dataloader 提供了 sampler (可以是batch_sampler 或者是其他 sampler 子类),然后 _SingleProcessDataLoaderIter 迭代sampler获得索引。
下面我们来看看 fetcher,fetcher 需要 index 来获取元素,并同时支持 Map-style dataset(对应 _MapDatasetFetcher)和 Iterable-style dataset(对应 _IterableDatasetFetcher),使其在Dataloader内能使用相同的接口 fetch,代码更加简洁。
● 对于 Map-style:直接输入索引 index,作为 map 的 key,获得对应的样本(即 value)。
class _MapDatasetFetcher(_BaseDatasetFetcher):
def __init__(self, dataset, auto_collation, collate_fn, drop_last):
super(_MapDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last)
def fetch(self, possibly_batched_index):
if self.auto_collation:
# 有batch_sampler,_auto_collation就为True,
# 就优先使用batch_sampler,对应在fetcher中传入的就是一个batch的索引
data = [self.dataset[idx] for idx in possibly_batched_index]
else:
data = self.dataset[possibly_batched_index]
return self.collate_fn(data)
● 对于 Iterable-style: __init__ 方法内设置了 dataset 初始的迭代器,fetch 方法内获取元素,index 其实已经没有多大作用了。
class _IterableDatasetFetcher(_BaseDatasetFetcher):
def __init__(self, dataset, auto_collation, collate_fn, drop_last):
super(_IterableDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last)
self.dataset_iter = iter(dataset)
def fetch(self, possibly_batched_index):
if self.auto_collation:
# 对于batch_sampler(即auto_collation==True)
# 直接使用往后遍历并提取len(possibly_batched_index)个样本(即1个batch的样本)
data = []
for _ in possibly_batched_index:
try:
data.append(next(self.dataset_iter))
except StopIteration:
break
if len(data) == 0 or (self.drop_last and len(data) < len(possibly_batched_index)):
raise StopIteration
else:
# 对于sampler,直接往后遍历并提取1个样本
data = next(self.dataset_iter)
return self.collate_fn(data)
最后,我们通过索引传入 fetcher,fetch 得到想要的样本。
因此,整个过程调用关系总结 如下:
loader.__iter__ --> self._get_iterator() --> class _SingleProcessDataLoaderIter--> class _BaseDataLoaderIter --> __next__() --> self._next_data() --> self._next_index() -->next(self._sampler_iter) 即 next(iter(self._index_sampler)) --> 获得 index --> self._dataset_fetcher.fetch(index) --> 获得 data
对于多进程而言,借用 PyTorch 内源码的注释,其运行流程解释如下:
# Our data model looks like this (queues are indicated with curly brackets):
#
# main process ||
# | ||
# {index_queue} ||
# | ||
# worker processes || DATA
# | ||
# {worker_result_queue} || FLOW
# | ||
# pin_memory_thread of main process || DIRECTION
# | ||
# {data_queue} ||
# | ||
# data output \/
#
# P.S. `worker_result_queue` and `pin_memory_thread` part may be omitted if
# `pin_memory=False`.
首先 dataloader 基于 multiprocessing 产生多进程,每个子进程的输入输出通过两个主要的队列 (multiprocessing.Queue() 类) 产生,分别为:
● index_queue: 每个子进程的队列中需要处理的任务的下标
● _worker_result_queue: 返回时处理完任务的下标
● data_queue: 表明经过 pin_memory 处理后的数据队列
并且有以下这些比较重要的 flag 参数来协调各个 worker 之间的工作:
● _send_idx: 发送索引,用来记录这次要放 index_queue 中 batch 的 idx
● _rcvd_idx: 接受索引,记录要从 data_queue 中取出的 batch 的 idx
● _task_info: 存储将要产生的 data 信息的 dict,key为 task idx(由 0 开始的整形索引),value 为 (worker_id,) 或 (worker_id, data),分别对应数据 未取 和 已取 的情况
● _tasks_outstanding: 整形,代表已经准备好的 task/batch 的数量(可能有些正在准备中)
每个 worker 一次产生一个 batch 的数据,返回 batch 数据前放入下一个批次要处理的数据下标,对应构造函数子进程初始化如下:
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
super(_MultiProcessingDataLoaderIter, self).__init__(loader)
...
self._worker_result_queue = multiprocessing_context.Queue() # 把该worker取出的数放入该队列,用于进程间通信
...
self._workers_done_event = multiprocessing_context.Event()
self._index_queues = []
self._workers = []
for i in range(self._num_workers):
index_queue = multiprocessing_context.Queue() # 索引队列,每个子进程一个队列放要处理的下标
index_queue.cancel_join_thread()
# _worker_loop 的作用是:从index_queue中取索引,然后通过collate_fn处理数据,
# 然后再将处理好的 batch 数据放到 data_queue 中。(发送到队列中的idx是self.send_idx)
w = multiprocessing_context.Process(
target=_utils.worker._worker_loop, # 每个worker子进程循环执行的函数,主要将数据以(idx, data)的方式传入_worker_result_queue中
args=(self._dataset_kind, self._dataset, index_queue,
self._worker_result_queue, self._workers_done_event,
self._auto_collation, self._collate_fn, self._drop_last,
self._base_seed + i, self._worker_init_fn, i, self._num_workers,
self._persistent_workers))
w.daemon = True
w.start()
self._index_queues.append(index_queue)
self._workers.append(w)
if self._pin_memory:
self._pin_memory_thread_done_event = threading.Event()
self._data_queue = queue.Queue() # 用于存取出的数据进行 pin_memory 操作后的结果
pin_memory_thread = threading.Thread(
target=_utils.pin_memory._pin_memory_loop,
args=(self._worker_result_queue, self._data_queue,
torch.cuda.current_device(),
self._pin_memory_thread_done_event))
pin_memory_thread.daemon = True
pin_memory_thread.start()
# Similar to workers (see comment above), we only register
# pin_memory_thread once it is started.
self._pin_memory_thread = pin_memory_thread
else:
self._data_queue = self._worker_result_queue
...
self._reset(loader, first_iter=True)
def _reset(self, loader, first_iter=False):
super()._reset(loader, first_iter)
self._send_idx = 0 # idx of the next task to be sent to workers,发送索引,用来记录这次要放 index_queue 中 batch 的 idx
self._rcvd_idx = 0 # idx of the next task to be returned in __next__,接受索引,记录要从 data_queue 中取出的 batch 的 idx
# information about data not yet yielded, i.e., tasks w/ indices in range [rcvd_idx, send_idx).
# map: task idx => - (worker_id,) if data isn't fetched (outstanding)
# \ (worker_id, data) if data is already fetched (out-of-order)
self._task_info = {}
# _tasks_outstanding 指示当前已经准备好的 task/batch 的数量(可能有些正在准备中)
# 初始值为 0, 在 self._try_put_index() 中 +1,在 self._next_data 中-1
self._tasks_outstanding = 0 # always equal to count(v for v in task_info.values() if len(v) == 1)
# this indicates status that a worker still has work to do *for this epoch*.
self._workers_status = [True for i in range(self._num_workers)]
# We resume the prefetching in case it was enabled
if not first_iter:
for idx in range(self._num_workers):
self._index_queues[idx].put(_utils.worker._ResumeIteration())
resume_iteration_cnt = self._num_workers
while resume_iteration_cnt > 0:
data = self._get_data()
if isinstance(data, _utils.worker._ResumeIteration):
resume_iteration_cnt -= 1
...
# 初始化的时候,就将 2*num_workers 个 (batch_idx, sampler_indices) 放到 index_queue 中
for _ in range(self._prefetch_factor * self._num_workers):
self._try_put_index() # 进行预取
dataloader 初始化的时候,每个 worker 的 index_queue 默认会放入两个 batch 的 index,从 index_queue 中取出要处理的下标:
def _try_put_index(self):
# self._prefetch_factor 默认为 2
assert self._tasks_outstanding < self._prefetch_factor * self._num_workers
try:
index = self._next_index()
except StopIteration:
return
for _ in range(self._num_workers): # find the next active worker, if any
worker_queue_idx = next(self._worker_queue_idx_cycle)
if self._workers_status[worker_queue_idx]:
break
else:
# not found (i.e., didn't break)
return
self._index_queues[worker_queue_idx].put((self._send_idx, index)) # 放入 任务下标 和 数据下标
self._task_info[self._send_idx] = (worker_queue_idx,)
# _tasks_outstanding + 1,表明预备好的batch个数+1
self._tasks_outstanding += 1
# send_idx 发送索引, 记录从sample_iter中发送索引到index_queue的次数
self._send_idx += 1
调用 _next_data 方法进行数据读取,其中 _process_data 用于返回数据:
def _next_data(self):
while True:
while self._rcvd_idx < self._send_idx: # 确保待处理的任务(待取的batch)下标 > 处理完毕要返回的任务(已经取完的batch)下标
info = self._task_info[self._rcvd_idx]
worker_id = info[0]
if len(info) == 2 or self._workers_status[worker_id]: # has data or is still active
break
del self._task_info[self._rcvd_idx]
self._rcvd_idx += 1
else:
# no valid `self._rcvd_idx` is found (i.e., didn't break)
if not self._persistent_workers:
self._shutdown_workers()
raise StopIteration
# Now `self._rcvd_idx` is the batch index we want to fetch
# Check if the next sample has already been generated
if len(self._task_info[self._rcvd_idx]) == 2:
data = self._task_info.pop(self._rcvd_idx)[1]
return self._process_data(data)
assert not self._shutdown and self._tasks_outstanding > 0
idx, data = self._get_data() # 调用 self._try_get_data() 从 self._data_queue 中取数
self._tasks_outstanding -= 1 # 表明预备好的batch个数需要减1
if self._dataset_kind == _DatasetKind.Iterable:
# Check for _IterableDatasetStopIteration
if isinstance(data, _utils.worker._IterableDatasetStopIteration):
if self._persistent_workers:
self._workers_status[data.worker_id] = False
else:
self._mark_worker_as_unavailable(data.worker_id)
self._try_put_index()
continue
if idx != self._rcvd_idx:
# store out-of-order samples
self._task_info[idx] += (data,)
else:
del self._task_info[idx]
return self._process_data(data) # 返回数据
def _process_data(self, data):
self._rcvd_idx += 1
self._try_put_index() # 同上,主要放入队列索引 以及 更新flag
if isinstance(data, ExceptionWrapper):
data.reraise()
return data
这样,多线程的 dataloader 就能通过多个 worker 的协作来共同完成数据的加载。
9 参考
https://pytorch.org/docs/stable/data.html
https://www.zhihu.com/search?type=content&q=dataloader
https://www.dazhuanlan.com/2019/12/05/5de8104ce9491/
https://blog.csdn.net/g11d111/article/details/81504637
猜您喜欢:
等你着陆!【GAN生成对抗网络】知识星球!
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
CVPR 2021 | 图像转换 今如何?几篇GAN论文
【CVPR 2021】通过GAN提升人脸识别的遗留难题
CVPR 2021生成对抗网络GAN部分论文汇总
经典GAN不得不读:StyleGAN
最新最全20篇!基于 StyleGAN 改进或应用相关论文
超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 | 《Python进阶》中文版
附下载 | 经典《Think Python》中文版
附下载 | 《Pytorch模型训练实用教程》
附下载 | 最新2020李沐《动手学深度学习》
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 |《计算机视觉中的数学方法》分享
