基于改进型生成对抗网络生成异构故障样本的方法

文章地址:A Modified Generative Adversarial Network for Fault Diagnosis in High-Speed Train Components with Imbalanced and Heterogeneous Monitoring Data| Journal of Dynamics, Monitoring and Diagnostics
https://www.researchgate.net/publication/359708692_A_modified_generative_adversarial_network_for_fault_diagnosis_in_high-speed_train_components_with_imbalanced_and_heterogeneous_monitoring_data
文章简介:
数据驱动方法被广泛用于复杂系统的故障诊断研究。然而,在实践中,由于故障样本有限而导致的类别不平衡问题极有可能令数据驱动模型表现欠佳。为了解决这一问题,各种合成少数类样本的数据增强方法被相继提出,并成功应用于调整数据分布、提高分类性能。其中,生成对抗网络(Generative Adversarial Network, GAN)能够自动提取有效信息、学习真实样本内在分布,灵活、高效地扩充少数类样本。然而,目前的GAN方法在处理异构数据方面仍存在一些挑战。复杂系统故障诊断中,监测数据往往包括不同数据类型的变量,是典型的异构数据。因此,本文设计了一个混合双鉴别器生成对抗网络(Mixed Dual Discriminator Generative Adversarial Network, M-D2GAN),用于增强复杂系统的异构故障数据,如图1所示。

图1 M-D2GAN的结构示意图
M-D2GAN的架构简介:
为了使生成的故障样本更符合实际情况,M-D2GAN中生成器G的输出层以不同的方式生成不同类型的变量。此外,对于在高可靠性系统中的故障诊断,生成的故障样本不仅要与真实的故障数据相似,而且要与真实的正常数据不同。因而,除了经典GAN中辨别生成样本是否真实的辨别器D之外,M-D2GAN中还添加了正常类的鉴别器F,用以判断生成样本是否是正常的。所提出的M-D2GAN分两个步骤进行开发:
1. 识别不同类型的变量,并为不同类型的变量设计编码和生成规则。设计生成器G,G的输入为白噪声z,输出为不同类型变量按照编码后的顺序组合而成的生成样本G(z)。通常,复杂系统异构监测数据可能包括以下四种类型的变量:浮点型、整数型、无差异类别型和等级型。本文对这四种变量设计的编码和生成规则具体如下:
1)浮点型变量直接输入D、F和故障诊断模型。在G中生成样本时,不需要处理相应的列;
2)整数型变量也直接输入D、F和故障诊断模型,但在生成样本时,G中相应的列进行四舍五入;
3)无差异类别型变量经过独热编码后输入到模型中。在G中生成样本时,使用可微的Gumbel-softmax获得编码后变量对应的列;
4)等级型变量按照从小到大的等级进行标签编码后输入到模型中,在G中生成样本时,设置相应列的输出范围并四舍五入。
2. 建立双鉴别器D和F来区分生成样本,鉴别器D区分生成样本是否真实,F区分生成样本是否是正常类。由于正常样本的规模很大,我们只要用正常样本训练一个多层感知器(Multi-Layer Perceptron, MLP),就可以得到一个好的F。考虑到如果将生成的样本或故障样本添加到训练模型F中,生成的样本可能与实际故障样本的位置非常接近,导致故障诊断无法识别随机故障和未发生的故障。因此,模型F在训练M-D2GAN的过程中不再被优化。辨别器D为二分类神经网络,用于分辨输入D的样本是生成样本还是真实样本,与生成器G迭代优化。生成器G的训练目标是使D无法区分生成样本与真实故障样本,而使F能够区分生成样本与真实正常样本。本文采用了对超参数不敏感的Adam算法进行模型优化,M-D2GAN优化过程的损失函数V(D,G)为:
![]()
式中:D(x)是故障样本x为真实样本的概率;![]() 为取遍所有故障样本x求期望值;D(G(z))为生成样本G(z)为真实样本的概率;F(G(z))为生成样本G(z)是正常样本的概率;
为取遍所有故障样本x求期望值;D(G(z))为生成样本G(z)为真实样本的概率;F(G(z))为生成样本G(z)是正常样本的概率;![]() 为取遍设定的所有白噪声z求期望值。
为取遍设定的所有白噪声z求期望值。
假设原始的故障诊断模型的训练数据为[X, Y],将一组白噪声输入训练好的M-D2GAN中生成器G得到包含M个样本的合成故障数据U,添加一列故障状态I(全1向量),得到新的训练数据 ,用于训练故障诊断模型。
,用于训练故障诊断模型。
应用结果:
为了检验所提出方法的有效性,本文基于某高速列车制动控制系统运行一年的真实监测数据,设计了一个对比实验,验证M-D2GAN比经典GAN更加有效,实验流程如图2所示。为了避免随机因素对比较结果的影响,本实验考虑了不同的分类算法作为故障诊断模型,包括Logistic回归(Logistic Regression, LR)、K-近邻(K-Nearest Neighbor, KNN)、多层感知器(Multi-Layer Perceptron, MLP)和卷积神经网络(Convolutional Neural Network, CNN)。采用5倍交叉验证方法比较各故障诊断模型的平均泛化精度。在5折交叉验证中,每个故障诊断模型的实际训练数据都为原始训练数据和生成数据组成的数据集。所有的模型都通过逐步增加结构的复杂性和迭代次数来进行优化,直到泛化精度保持稳定或降低。
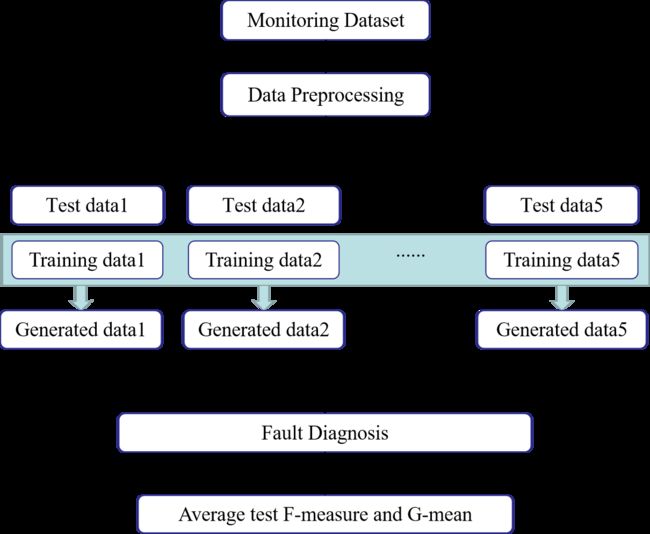
图2 对比实验的流程图
表1 不同生成方法的效果对比
| Model |
Method |
F-measure |
G-mean |
| LR |
Untreated |
0.21884 |
0.42733 |
| GAN |
0.42424 |
0.79723 |
|
| M-D2GAN |
0.56111 |
0.82432 |
|
| KNN |
Untreated |
0.21429 |
0.47034 |
| GAN |
0.66316 |
0.78208 |
|
| M-D2GAN |
0.72414 |
0.82305 |
|
| MLP |
Untreated |
0.53020 |
0.68825 |
| GAN |
0.66949 |
0.78591 |
|
| M-D2GAN |
0.75238 |
0.84135 |
|
| CNN |
Untreated |
0.38095 |
0.81494 |
| GAN |
0.77396 |
0.8559 |
|
| M-D2GAN |
0.82245 |
0.88741 |
可以看出,类别不平衡数据会严重影响故障诊断模型的效果,所提出的M-D2GAN和经典的GAN都可以通过添加故障样本来提高故障诊断模型的预测精度。其中,所提出的M-D2GAN可以进一步提高故障诊断模型的表现。
此外,也可以从图3-5不同数据集的t-SNE投影中看出,M-D2GAN和GAN均可以提高不同类数据的可分性。然而,经典GAN可能会对稀缺的故障数据进行过拟合,在每个原始故障数据附近生成合成样本,显示出大量的集群;相反,本文提出的M-D2GAN生成的合成样本具有较好的泛化能力,这一点从表1的比较结果也可以看出。

图3 原始数据的t-SNE投影

图4 采用经典GAN平衡化后的数据集的2维t-SNE投影

图5 采用M-D2GAN平衡化后的数据集的2维t-SNE投影
总结:
在高可靠性系统的预测与健康管理(Prognostics and Health Management, PHM)中,监测数据存在类别不平衡问题可能会严重恶化数据驱动方法的故障诊断性能。此外,复杂系统监测数据通常具有异构性,即包括不同类型的变量,也具有一定的处理难度。为处理类别不平衡的异构数据,本文提出了一个改进型生成对抗网络——混合双鉴别器生成对抗网络(M-D2GAN)。在该方法中,为了使生成的故障样本更符合实际情况,我们以不同的方式生成不同类型的变量。此外,设计了双鉴别器,以避免生成的样本加剧类重叠。M-D2GAN生成的故障数据补充到原始数据中,能够丰富故障样本,提高故障诊断模型的预测性能。对于其他高可靠性复杂系统的PHM分析,M-D2GAN在故障预测和回归方面也具有潜在的价值。
How to Cite:Wang, C., Liu, J., & Zio, E. “A Modified Generative Adversarial Network for Fault Diagnosis in High-Speed Train Components with Imbalanced and Heterogeneous Monitoring Data”. Journal of Dynamics, Monitoring and Diagnostics, vol. 1, no. 2, 2022, pp. 84-92.