综述:基于点云的自动驾驶3D目标检测和分类方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()

参考论文:Point-Cloud based 3D Object Detection and Classification Methods for Self-Driving Applications: A Survey and Taxonomy
Abstract
在深度学习技术的影响下,自动驾驶已经成为未来发展的中心,自2010年,围绕自动驾驶技术的研究快速发展,出现了众多新颖的目标检测技术.最初开始人们检测图像数据中的对象,近期出现了利用3D点云数据(激光雷达可以更准确地检测车辆周围环境)进行目标检测的技术.本文基于现有的自动驾驶中利用3D点云数据进行目标检测的文献,从数据特征提取和目标检测模型等方面对不同技术进行比较.
Introduction
根据世卫(WHO)统计每年因为交通事故造成的死亡或残疾的人数达5千万人数.而通过自动驾驶技术不仅可以大幅度降低车祸的死亡人数,还可以提高车辆运行效率.自动驾驶车辆要从周围环境中收集关键信息(行人、车辆、自行车等),预测他们未来的状态.
目前自动驾驶车辆主要使用LiDAR(激光雷达),如表1所示,LiDAR可以精确测量传感器与周围障碍物之间的距离,同时提供丰富的几何信息、形状和比例信息.但也有其他传感解决方案已在自动驾驶环境中进行了多种用途的探索.例如,基于相机的解决方案可以提供高密度像素强度信息优势,但缺乏距离信息的缺点,而3D相机又有成本昂贵以及对光照条件要求严格的缺点.
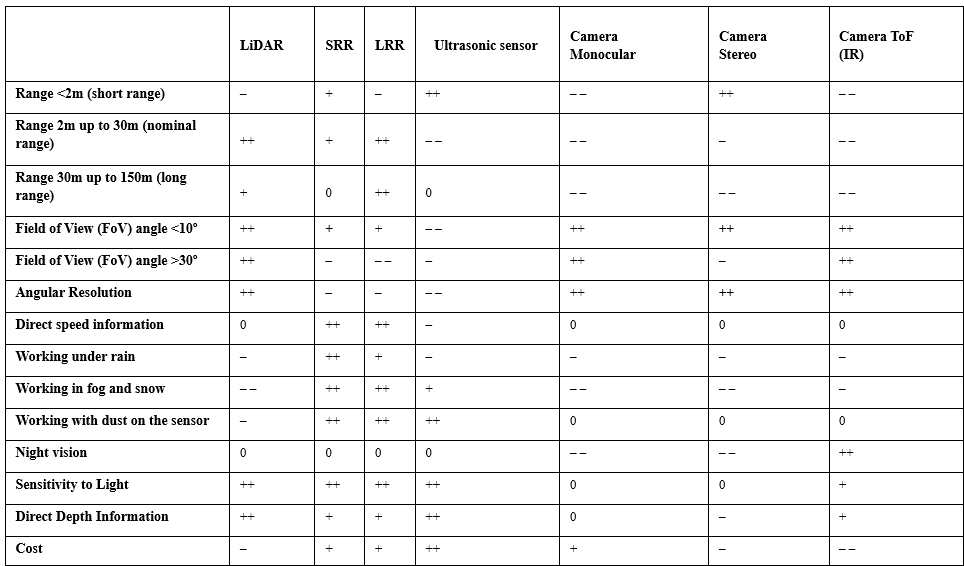
1.传感器的比较
(++)完全适应的传感器;(+)性能良好的传感器;(−) 传感器可能符合标准,但可能存在缺点;(− −) 传感器,可用于适应和额外的重型治疗;(0)传感器不能满足标准或不适用;
接下来,我们将目标检测的各种贡献分为Data Representation、Data Feature Extraction、Detection Module和Prediction Refinement Network四大类,如图1所示.
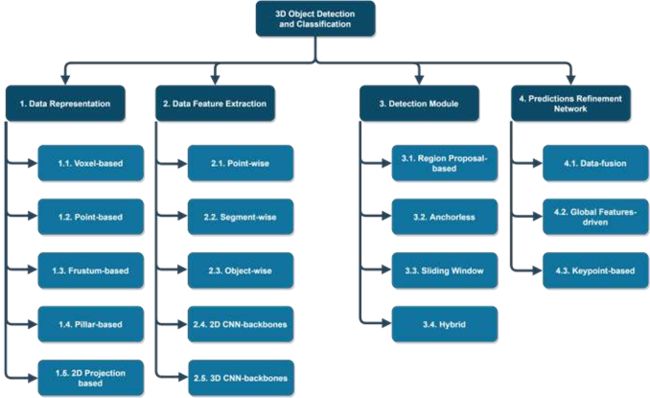 图1.将基于深度学习的目标检测的各种贡献分为四大类,即数据表示法、数据特征提取、检测模块和预测细化网络.
图1.将基于深度学习的目标检测的各种贡献分为四大类,即数据表示法、数据特征提取、检测模块和预测细化网络.
Point-based保留了点云的全部信息,如PointNet使用Point-based数据提取局部和全局特征.Voxel-based损失了部分点云位置信息,基于Voxel-based的特征提取有助于提高特征提取网络的计算效率和减少内存需求.基于Frustum-based的网络有Frustum PointNet[46],Frustum ConvNet[47] andSIFRNet[48].PointPillars使用Pillar-based将将点云组织成垂直的柱状,从而排除z坐标,例如PointPillars[49].除了使用三维体素表示外,一些方法(正视图FV、 range view 、鸟瞰图BEV)将信息压缩到二维投影中,以减少三维激光雷达数据的高计算量.目标检测模型中最关键的任务是提取特征,保证最佳的特征学习能力是至关重要的,
Data Feature Extraction有如下几种: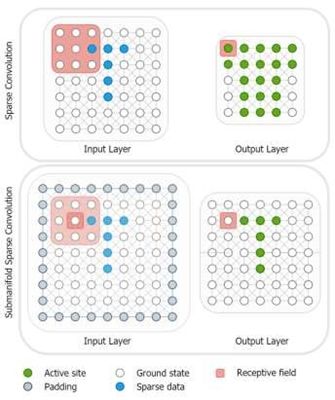 图4.稀疏卷积(SC)和子流形稀疏卷积(VSC).
图4.稀疏卷积(SC)和子流形稀疏卷积(VSC).
PointNet[37]和PointNet++[38]是最著名的point-wise特征提取器.如下图所示,PointNet用于几何特征提取和对象分类,但由于每个点都单独学习特征,忽略点间的关系,因此在捕获相邻点之间的局部结构信息方面存在严重的局限性.
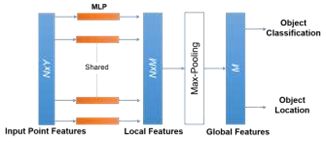 图2.PointNet结构
图2.PointNet结构
基于point-wise的方案对象检测时间较长,因此引入了segment-wise.例如 VoxelNet [25], Second [29], Voxel-FPN [32], and HVNet [62].首先用体素构造点云,然后使用图3所示的特征提取器,允许网络提取低维特征(对象边缘、每个体素).与point-wise相比,segment-wise 可以应用 voxels pillars frustums
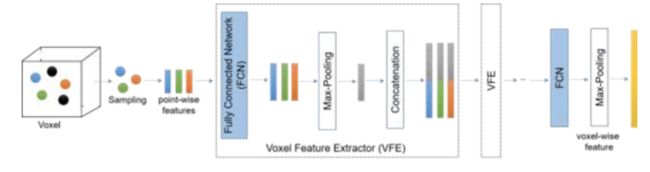
图3.体素特征提取网络的结构
Object-Wise利用成熟的二维目标检测,用于过滤点云和检测图像中的对象,然后得到的二维边界用于三维对象的边界框.Convolutional Neural Networks中包含2D Backbone、3D Backbone,在三维空间中直接应用卷积将在计算上效率低下,并将严重增加计算量和模型的推理时间,因为三维表示处理自然比二维表示要长,更重要的是点云是稀疏的.因此,直接使用三维表示看起来是一项非常耗时的任务.而使用稀疏卷积(SC)和子流形稀疏卷积(VSC)来处理稀疏数据,可以有效地提取特征和更快的运行时间.
三维目标检测模型中的特征提取方法
三维目标检测模型中的特征提取方法,其中,检测过程可能使用单级或双级架构来学习全局特征,单级架构和双级的架构通用表示如图5所示.表2总结了目标检测模型采用的特征提取方法.
图5.i)双级检测器结构和 ii)单级检测器结构的通用表示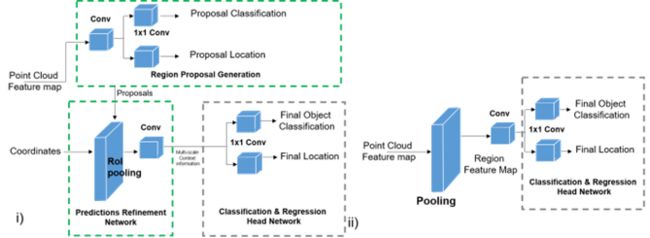
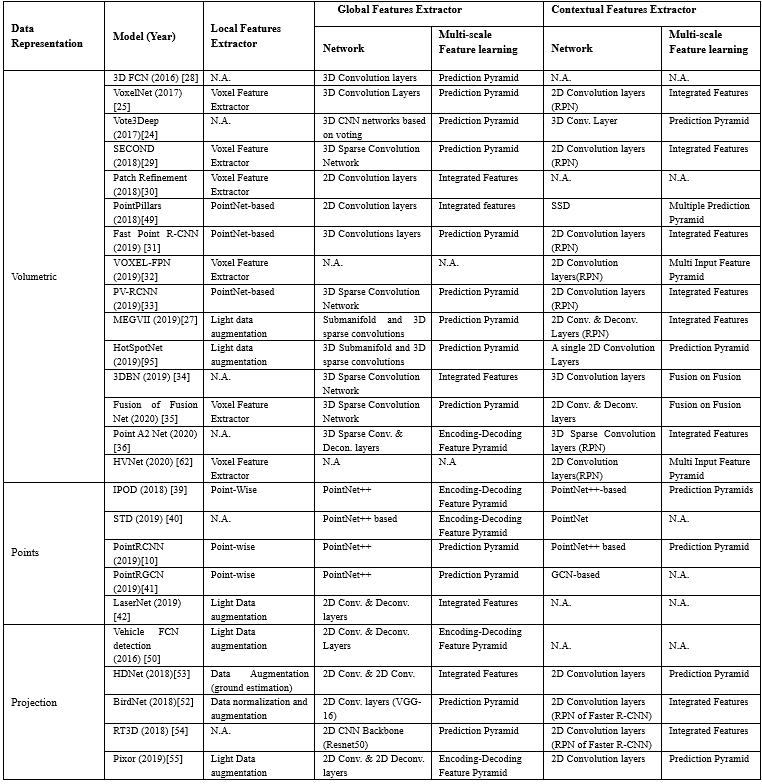 表2.目标检测模型常用的特征提取方法
表2.目标检测模型常用的特征提取方法
此外,特征的多尺度和以及不同特征的聚集有利于提高预测3D的性能.例如,研究项目Point RCNN证明,通过连接局部和全局特征来生成上下文特征,可以略微提高3D目标检测性能(metric AP)高达2%[10].不聚合上下文信息会显著影响模型性能,特别是在可用点数太少的情况下,例如,当对象被遮挡或远离传感器时.在这种情况下,多尺度特征学习方案起着重要的作用.它们的横向连接和路径提供了更丰富的语义信息,即使对于小尺寸的物体也是如此.表3展示了目标检测模型常用的预测细化网络.
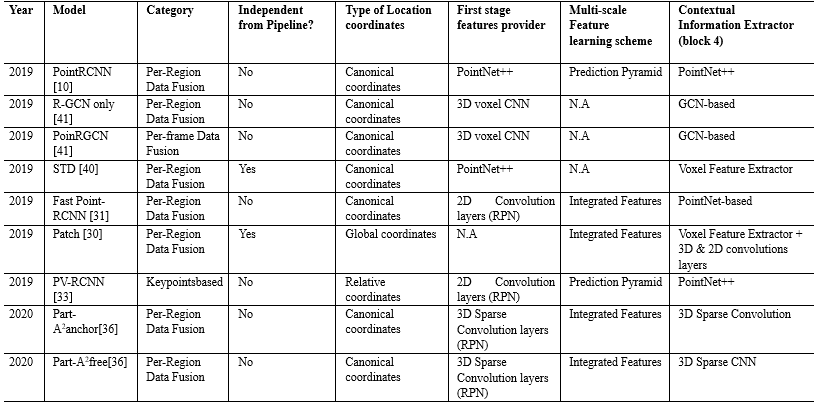 表3.目标检测模型采用的预测细化网络.
表3.目标检测模型采用的预测细化网络.
下面,我们将在多种设置的环境下收集的数据进行比较,并分析了它们构成.例如,在
Waymo数据集上,大约有6.1M标记的车辆,只有2.98M标记的行人和骑自行车的人.KITTI基准由7.481k训练图像和7.518k测试图像以及相应的点云组成,这些点云总共包括80.256k标记对象.这些基准还包括不同的类别,例如,KITTI包括3个类别:汽车、行人和自行车,而nuScenes包括23个类别的对象.
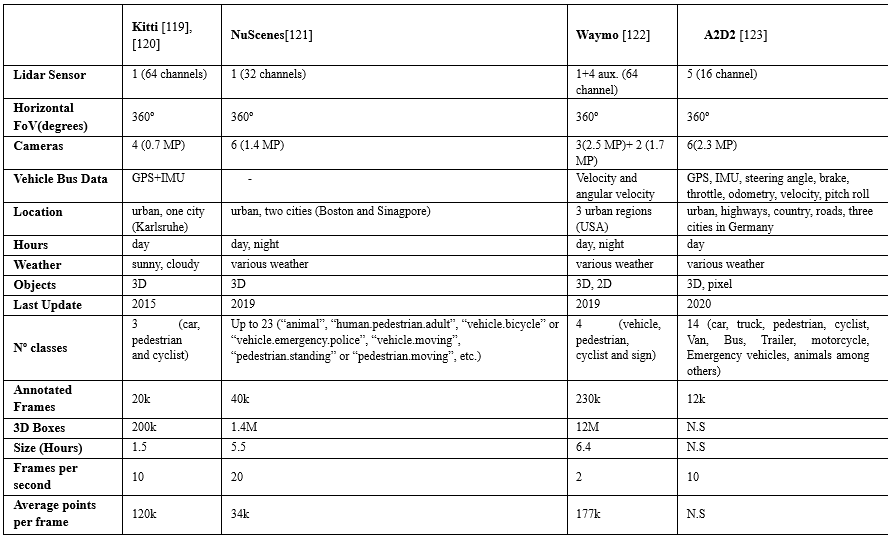 表4.多种条件下传感器收集数据比较.
表4.多种条件下传感器收集数据比较.
接下来无人驾驶车辆的目标模型的选择,其中大多数项目使用
RPN结构,以及使用PointNet或PointNet++执行实例或对象分割任务,如表5所示.
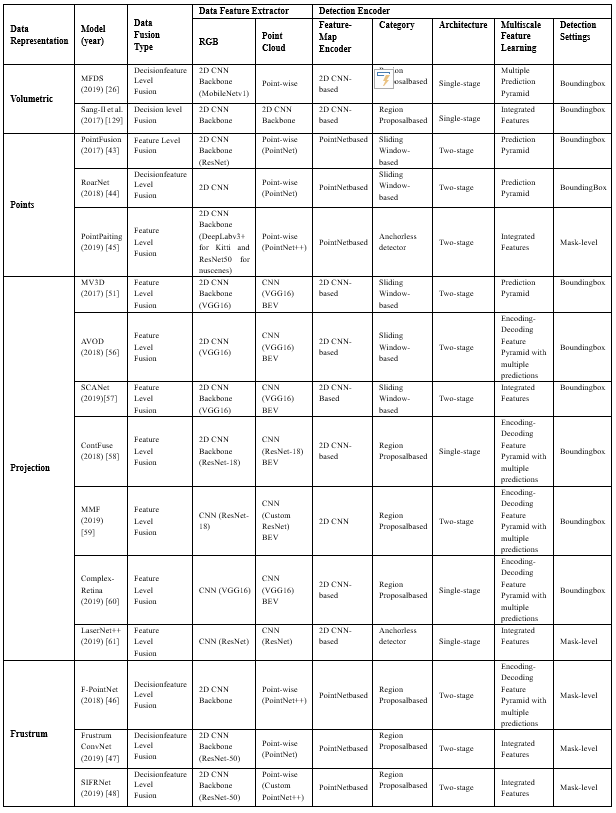 表5.文献中提出的基于融合的无人驾驶汽车应用模型的设计选择.
表5.文献中提出的基于融合的无人驾驶汽车应用模型的设计选择.
由于基于融合的方法依赖于两种不同类型的数据集,因此它们之间的同步和校准非常重要.如表6所示,这些方法总体上取得了较好的性能效果;然而,模型[45]、[46]、[51]、[113]计算效率低下,推理时间超过170ms,与仅使用激光雷达的方法相比,这些解决方案的运行速度很慢.尽管这些方法取得了良好的性能结果,但是他们严重依赖现成的2D物体检测,不能接受利用3D信息生成更精确的边界框.
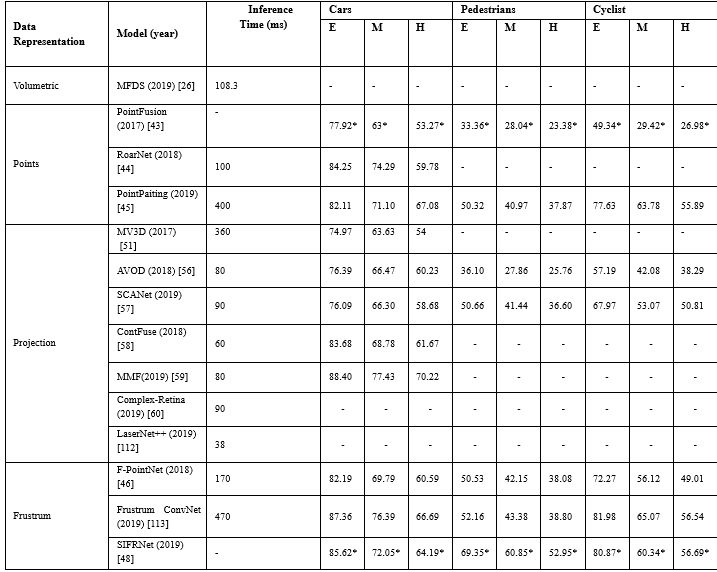 表6.KITTI-test3D检测基准与融合模型的3D目标检测模型结果比较
表6.KITTI-test3D检测基准与融合模型的3D目标检测模型结果比较
如表7所示,大多数模型使用单阶段架构,与双阶段模型相比单阶段模型速度更快,但实现的3D目标检测性能较低,然而,最近
Point-RCNN[10],Fast Point R-CNN[31]等通过实现第二阶段,显著提高了3D检测性能.这是因为模型的各个阶段可以单独训练和评估,并且可以执行额外的增强技术,而且特征的多尺度、不同特征的聚合有利于提高3维目标检测的性能.
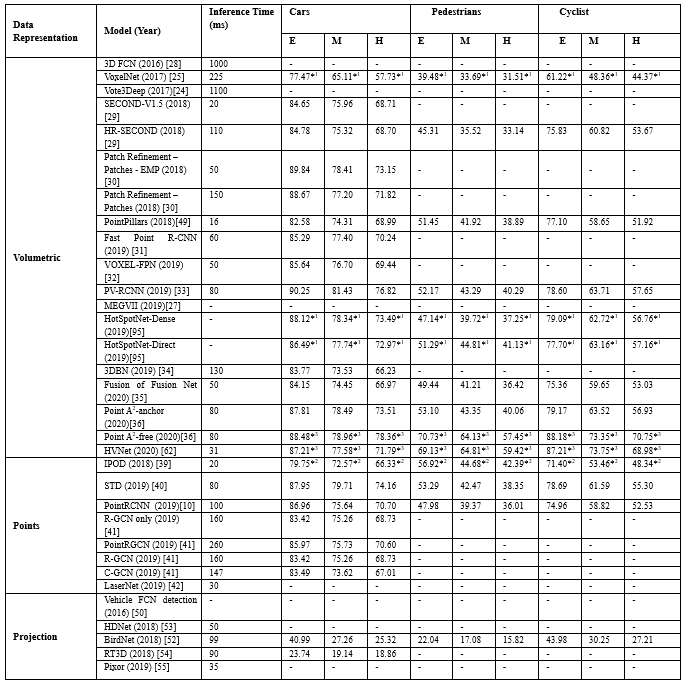 表7. KITTI测试集3D检测基准上3D目标检测模型结果的比较,激光雷达
表7. KITTI测试集3D检测基准上3D目标检测模型结果的比较,激光雷达
总结
近年来,随着3D传感技术和计算技术的发展,用于目标检测的深度学习模型的数据集得以扩展.本文对比分析了目前最先进的目标检测方法,以满足LiDAR或基于融合LiDAR的解决方案.除了对现有的不同方法进行系统研究外,还发现了一些存在的问题,如模型的可解释性、复杂的感知场景、小物体或遮挡物体、正负不平衡采样等,仍然是自动驾驶3维目标检测的主要挑战.这些问题表明,尽管在自动驾驶目标检测方面取得了最新进展,如无锚点检测器、一级和两级检测器的组合以提高检测精度和改进后处理NMS,代表了对现有模型的一些改进.对模型在不同阶段的理解是解决问题的根本.最后总结了基于深度学习的LiDAR点云方法的一些挑战和未来工作的可能方向.
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

