COVID-19疫情数据探索性分析
上一篇讲了COVID-19疫情数据爬取分析
本篇接着讲COVID-19疫情数据探索性分析(EDA)
我们采用pandas库来进行数据分析
import pandas as pd
# 读取数据
today_world = pd.read_csv("today_world_2021_02_18.csv")
today_world.head()
数据预处理
英文列名不便于观察,更改为中文,使用rename()函数重命名
# 创建列名对应的中英文字典
name_dict = {'date':'日期','name':'名称','id':'编号','lastUpdateTime':'更新时间',
'today_confirm':'当日新增确诊','today_suspect':'当日新增疑似',
'today_heal':'当日新增治愈','today_dead':'当日新增死亡',
'today_severe':'当日新增重症','today_storeConfirm':'当日现存确诊',
'total_confirm':'累计确诊','total_suspect':'累计疑似',
'total_heal':'累计治愈','total_dead':'累计死亡','total_severe':'累计重症',
'total_input':'累计输入','today_input':'今日输入'}
# 重命名
today_world.rename(columns=name_dict,inplace=True)
对数据进行简单查看
today_world.info() # 查看基本信息
today_world.describe() # 查看统计信息
today_world.set_index('名称', drop=False, inplace=True) # 将国家设置为索引
使用isnull()查看数据缺失值,计算缺失值比例,并进行缺失值处理
# 计算缺失值比例
today_world_nan = today_world.isnull().sum()/len(today_world)
# 转化为百分比
today_world_nan.apply(lambda x: format(x, '.1%'))
# 对当日现存确诊缺失值进行处理
today_world['当日现存确诊'] = today_world['累计确诊']-today_world['累计治愈']-today_world['累计死亡']
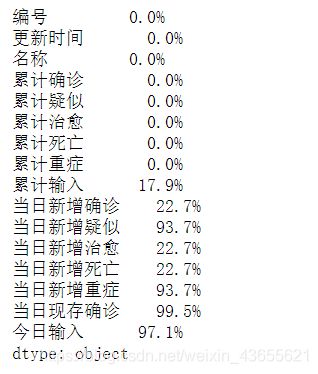
从缺失比例结果发现,当日新增相关数据缺失值较多,这主要由于采集数据的时候部分国家更新时间不一致,没有更新数据,因此我们将不再对其进行分析。
当日现存确诊人数,是由累计确诊人数-累计死亡人数-累计治愈人数所得
实时数据处理
反映疾病严重程度以及一个地区的医疗水平指标——病死率
计算公式:病死率 = 累计死亡 / 累计确诊
# 计算病死率,且保留两位小数
today_world['病死率'] = (today_world['累计死亡']/today_world['累计确诊']).apply(lambda x: format(x, '.2f'))
# 将病死率数据类型转换为float
today_world['病死率'] = today_world['病死率'].astype('float')
# 根据病死率降序排序
today_world.sort_values('病死率',ascending=False,inplace=True)
# 显示病死率前十国家
today_world.head(10)
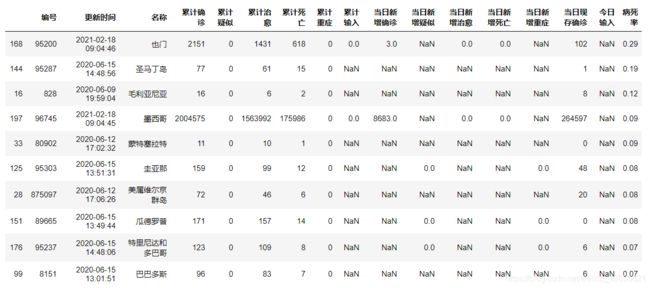
世界各国实时数据
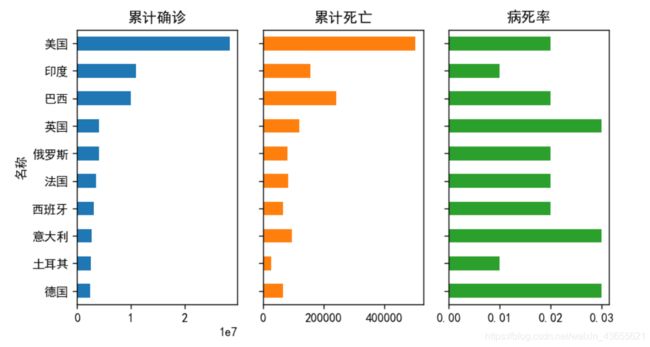
# 查看当前累计确诊人数前十国家
world_top10 = today_world.sort_values(['累计确诊'],ascending=False)[:10]
world_top10 = world_top10[['累计确诊','累计死亡','病死率']]
# 导入matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['figure.dpi'] = 120#设置所有图片的清晰度
# 绘制条形图
world_top10.sort_values('累计确诊').plot.barh(subplots=True,layout=(1,3),sharex=False,
figsize=(7,4),legend=False,sharey=True)
plt.tight_layout() #调整子图间距
plt.show()
中国各省实时数据
# 读取数据
today_province = pd.read_csv("today_province_2021_02_18.csv")
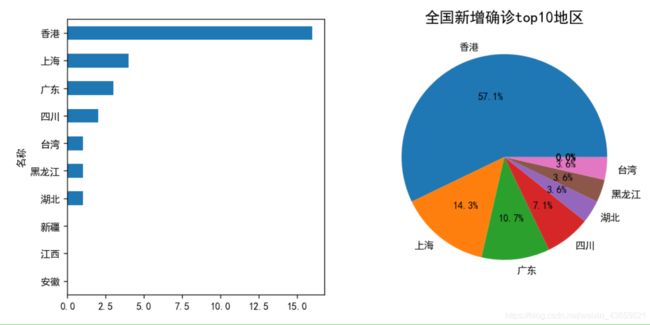
# 全国新增确诊top10地区
new_top6 = today_province['当日新增确诊'].sort_values(ascending=False)[:10]
# 可视化展示全国新增确诊top10地区情况
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
new_top6.sort_values(ascending=True).plot.barh(fontsize=10, ax=ax[0])
new_top6.plot.pie(autopct='%.1f%%', fontsize=10, ax=ax[1])
plt.ylabel('')
plt.title('全国新增确诊top10地区', size=15)
plt.show()
历史数据处理
中国历史数据
# 取读数据
alltime_china = pd.read_csv('alltime_China_2021_02_13.csv')
# 将日期改为datetime格式
alltime_china['日期'] = pd.to_datetime(alltime_china['日期'])
# 将日期作为索引
alltime_china.set_index('日期', inplace=True)
对时间序列数据绘制折线图
import matplotlib.pyplot as plt
import matplotlib.dates as dates
import matplotlib.ticker as ticker
import datetime
fig, ax = plt.subplots(figsize=(8, 4))
alltime_china.loc['2020-12-25':'2021-02', ].plot(marker='o', ms=2, lw=1, ax=ax)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('%b'))
fig.autofmt_xdate()
plt.legend(bbox_to_anchor = [1, 1])
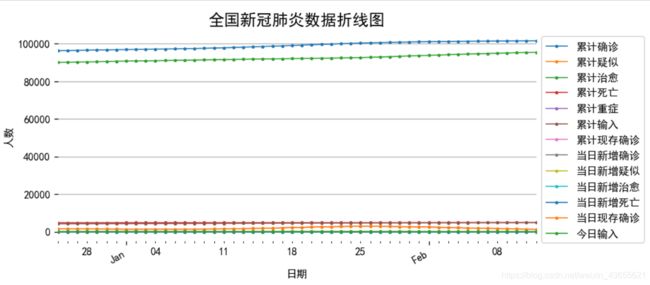
plt.title('全国新冠肺炎数据折线图', size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.show()
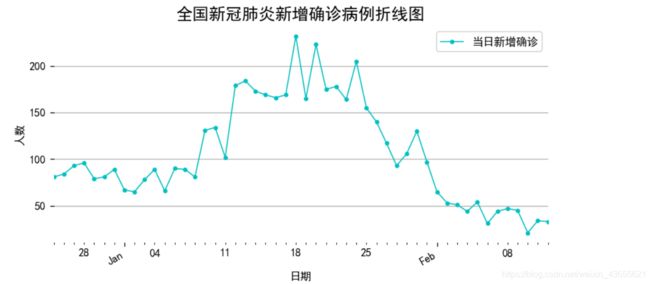
fig, ax = plt.subplots(figsize=(8, 4))
alltime_china['当日新增确诊'].loc['2020-12-25':'2021-02', ].plot(style='-', color='c', marker='o', ms=3, lw=1, ax=ax)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('%b'))
fig.autofmt_xdate()
plt.legend(bbox_to_anchor = [1, 1])
plt.title('全国新冠肺炎新增确诊病例折线图', size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.show()
世界历史数据
alltime_world = pd.read_csv("alltime_world_2021_02_18.csv")
alltime_world['日期'] = pd.to_datetime(alltime_world['日期'])
alltime_world.set_index('日期', inplace=True)
# 取2020-03-31之前的数据,可视化展示好看
alltime_world = alltime_world.loc[:'2020-03-31']
# groupby创建层次化索引
data = alltime_world.groupby(['日期','名称']).mean()
# 提取部分国家数据
data_part = data.loc(axis=0)[:,['中国','日本','韩国','美国','意大利','英国','西班牙','德国']]
# 将层次索引还原
data_part.reset_index('名称',inplace=True)
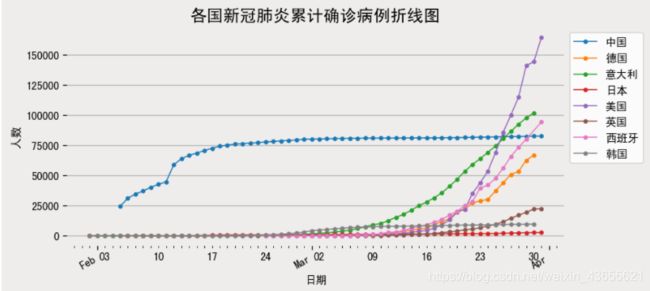
绘制多个国家的累计确诊人数折线图
fig, ax = plt.subplots(figsize=(8,4))
data_part['2020-02':].groupby('名称')['累计确诊'].plot(legend=True,marker='o',ms=3,lw=1)
ax.xaxis.set_major_locator(dates.MonthLocator()) #设置间距
ax.xaxis.set_major_formatter(dates.DateFormatter('%b')) #设置日期格式
fig.autofmt_xdate() #自动调整日期倾斜
plt.title('各国新冠肺炎累计确诊病例折线图',size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.legend(bbox_to_anchor = [1,1])
plt.show()
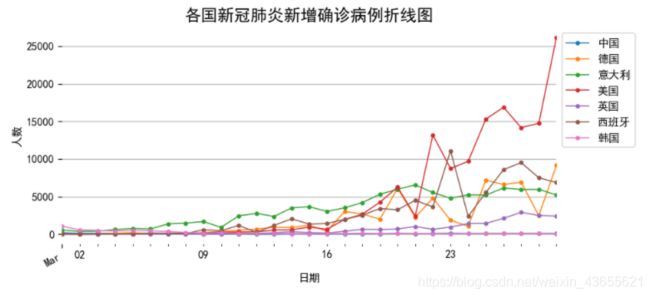
fig, ax = plt.subplots(figsize=(8,4))
data_part['2020-03':'2020-03-29'].groupby('名称')['当日新增确诊'].plot(legend=True,marker='o',ms=3,lw=1)
ax.xaxis.set_major_locator(dates.MonthLocator()) #设置间距
ax.xaxis.set_major_formatter(dates.DateFormatter('%b')) #设置日期格式
fig.autofmt_xdate() #自动调整日期倾斜
plt.title('各国新冠肺炎新增确诊病例折线图',size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.legend(bbox_to_anchor = [1,1])
plt.show()
总结
本篇博客对新冠肺炎疫情数据的探索性分析。其中数据预处理主要包括特征列重命名、缺失值处理、查看重复值、数据类型转换等操作。此外,使用了Pandas进行数据可视化,通过图表的绘制探索数据的内涵。对时间序列数据采用折线展示处理、使用Groupby进行数据分组,学习了层次化索引的操作方法。
参考资料:
https://mp.weixin.qq.com/s/HwRiHDh9QdnTBDyzexQbwA