windows10安装yolov5_obb时的一些报错记录
yolov5_obb链接
1、使用netron查看yolov5s-best.onnx模型结构。
在终端运行(切换到模型文件所在路径)
pip install netron
python
import netron
netron.start(‘best.onnx’)#绝对地址用双反斜杠:\
如下图所示:

2、想要查看 Pytorch 实际使用的运行时的 cuda 目录,可以直接输出之前介绍的 cpp_extension.py 中的 CUDA_HOME 变量。
>>> import torch
>>> import torch.utils
>>> import torch.utils.cpp_extension
>>> torch.utils.cpp_extension.CUDA_HOME #输出 Pytorch 运行时使用的 cuda
另外查看环境中的cuda版本,打开cmd,打开环境,输入nvidia-smi,或者nvcc --version或者nvcc -V
3、关于切换cuda版本
计算机->右键,属性->高级系统设置->环境变量
如图,我想用11.1版本,把cuda_path改为11.1
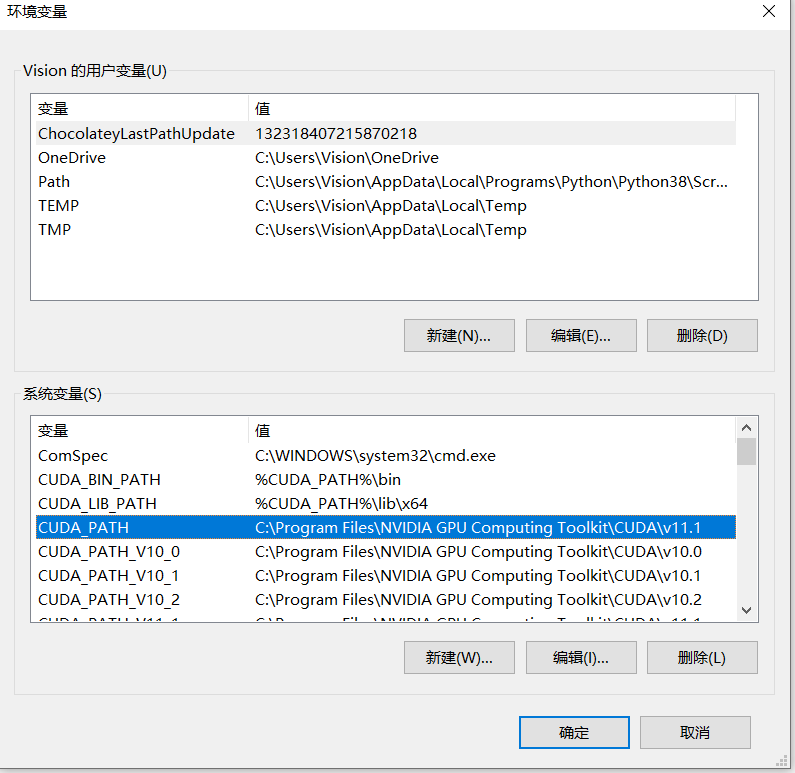
然后点击path,将path中的关于11.1的向上移到所有cuda 版本的最前面,如下图:


一共两个关于11.1的,然后再看运行cuda版本就是11.1了,亲测有效。


4、windows下使用python setup.py install包含pytorch组件时报:
cpp_extension.py:237: UserWarning: Error checking compiler version for cl: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
解决方法(参考的)
打开cpp_extension.py文件,在第260行左右,有一段:
try:
if sys.platform.startswith('linux'):
minimum_required_version = MINIMUM_GCC_VERSION
version = subprocess.check_output([compiler, '-dumpfullversion', '-dumpversion'])
version = version.decode().strip().split('.')
else:
minimum_required_version = MINIMUM_MSVC_VERSION
compiler_info = subprocess.check_output(compiler, stderr=subprocess.STDOUT)
match = re.search(r'(\d+)\.(\d+)\.(\d+)', compiler_info.decode().strip())
version = (0, 0, 0) if match is None else match.groups()
把其中的
compiler_info.decode()
替换成
compiler_info.decode(‘gbk’)
默认的utf-8解码变成gbk后,警告消失,问题解决。
5、拓展C++接口。切换到DOTA_devkit,运行:
swig -c++ -python polyiou.i
python setup.py build_ext --inplace
报错:

解决方法:
把polyiou.cpp用Notepad打开,编码->使用UTF-8-BOM编码->保存即可,如下图:

运行成功:
 6、 运行
6、 运行
cd utils/nms_rotated
python setup.py develop #or "pip install -v -e ."
时报错:
from distutils.spawn import _nt_quote_args # type: ignore
ImportError: cannot import name '_nt_quote_args' from 'distutils.spawn' (D:\Tools\Anaconda\envs\py38_yolov5_rotate\lib\site-packages\setuptools\_distutils\spawn.py)
解决方法:seetuptools官网链接

pip install setuptools==59.6.0
7、新错误:
File "D:\Tools\Anaconda\envs\py38_yolov5_rotate\lib\site-packages\torch\utils\cpp_extension.py", line 1538, in _run_ninja_build
raise RuntimeError(message) from e
RuntimeError: Error compiling objects for extension
检查版本
(py38_yolov5_rotate) PS E:\WeiYingYing\yolov5_obb-master\yolov5_obb-master\utils\nms_rotated> python
Python 3.8.12 (default, Oct 12 2021, 03:01:40) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.__version__)
1.7.0
>>> print(torch.cuda.is_available())
True
>>> print(torch.cuda.device_count()) #(查看可行的cuda数目:)
1
>>> torch.version.cuda #(查看torch对应的cuda版本)
'11.0'
>>> import torch.utils.cpp_extension
>>> torch.utils.cpp_extension.CUDA_HOME
'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.1'
>>> exit()
由以上代码可以看出cuda版本均是11.1,但是torch版本对应的cuda是11.0,重新下载cuda11.1对应的torch,
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
,再次测试环境,如下图:

此时要再次修改第4、步的报错,如下图,大概在300行

修改完后如果继续报错,我找到了一个解决办法:

下载位置:
BD链接:https://pan.baidu.com/s/1yXr1eIVu0h9tNfnjYIhwdw
提取码:yolo
8、修改以后的报错:
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.29.30133\\bin\\HostX86\\x64\\link.exe' failed with exit status 1120
解决方法一:
将C:\Program Files (x86)\Windows Kits\10\bin\10.0.18362.0\x64中的
rc.exe
rcdll.dll
复制到报错提示的位置处,比如我的报错位置是:
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\HostX86\x64\
当然,我还把他们复制到了C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin
可以从下图的visual studio installer 的修改框中看到sdk版本10.0.18362.0


解决方法二:
升级pip
python setup.py develop
解决方法三:
安装talib,一般pip install ta-lib会报错,手动安装方法,先下载对应版本的轮子:链接——注意talib版本名称中的cp39表示对应的python版本号为3.9,cp37对应python3.7,要根据自己安装的python版本选择,amd64表示对应操作系统为64位,win32表示对应操作系统为32位,如果版本不对会报以下错误:
ERROR: TA_Lib-0.4.17-cp37-cp37m-win_amd64.whl is not a supported wheel on this platform.
进入命令行,进入talib安装文件目录,执行命令:
pip install TA_Lib-0.4.18-cp38-cp38-win_amd64.whl
我在vs2019中安装了一次,打开Developer Command Prompt for VS 2019面板,输入安装指令;

然后在那个nms_rotated文件夹中也复制了一份,安装了一下,不知道哪个凑效了。当时没有成功。
最后:
忙活了一天,三种方法都试了,一直报错,一气之下把build文件夹的东西都删了,如下图:(build中应该是空的,然后再编译)

图中显示的lib.xxx和temp.xxx是删除后重新编译又生成的。。。。。。今天也是骂骂咧咧的一天,继续加油!
9、编译完成后将utils/nms_rotated/build/lib.win-amd64-3.x有个nms_rotated_ext.cp3x-win_amd64.pyd的文件(x为你python3.x的版本)拷贝到utils/nms_rotated目录下即可运行整个代码(这一步最新版代码作者已改,可以省略!!!)
10、数据集准备,用rolabelimg标注,得到xml文件,然后。。。。。。步骤见上一篇文章,将xml文件转为.txt,如下图格式:

正是新版本要求的格式:

如下图:(修改roxml_to_dota.py文件的路径dir)

粘贴图片与txt文件到dataset文件夹内相应位置。
11、训练(修改你选用的.yaml文件中的路径信息和name_classes等,单类别如下图:

)
usage: train.py [-h] [--weights WEIGHTS] [--cfg CFG] [--data DATA] [--hyp HYP] [--epochs EPOCHS] [--batch-size BATCH_SIZE] [--imgsz IMGSZ] [--rect] [--resume [RESUME]] [--nosave]
[--noval] [--noautoanchor] [--evolve [EVOLVE]] [--bucket BUCKET] [--cache [CACHE]] [--image-weights] [--device DEVICE] [--multi-scale] [--single-cls] [--adam] [--sync-bn]
[--workers WORKERS] [--project PROJECT] [--name NAME] [--exist-ok] [--quad] [--linear-lr] [--label-smoothing LABEL_SMOOTHING] [--patience PATIENCE]
[--freeze FREEZE [FREEZE ...]] [--save-period SAVE_PERIOD] [--local_rank LOCAL_RANK] [--entity ENTITY] [--upload_dataset [UPLOAD_DATASET]] [--bbox_interval BBOX_INTERVAL]
[--artifact_alias ARTIFACT_ALIAS]
python train.py --data data/yolov5obb_demo.yaml --imgsz 1280 --device 0 --cfg models/yolov5x.yaml --batch-size 1
--weights weights/yolov5x.pt(这个我没有加,没下载到本地权重)
训练时报错,解决方法:把batch_size改为2,当然也可以是1

python train.py --data data/yolov5obb_demo.yaml --imgsz 1280 --device 0 --cfg models/yolov5x.yaml

12、预测:把训练得到的best.pt文件copy到路径:
xxx\xxx\yolov5_obb-master\yolov5_obb-master\weights
运行:
python detect.py --weights weights/best.pt --imgsz 1280 --device 0 --source dataset/dataset_demo/images/
--hide-labels(可选)
结果:

13、val
运行:
python val.py --task val --device 0 --save-json --batch-size 1 --data data/yolov5obb_demo.yaml --name obb_demo --img 1280 --save-txt
如下图:(生成相应的txt文件)

14、转换模型
运行:
python export.py --device 0 --data data/yolov5obb_demo.yaml --weights weights/best.pt --batch-size 1 --imgsz 1280 --simplify --include torchscript onnx
15、查看模型结构的方法
网页链接点进去后点openxxx即可看到
