- 卷积过程示意图:
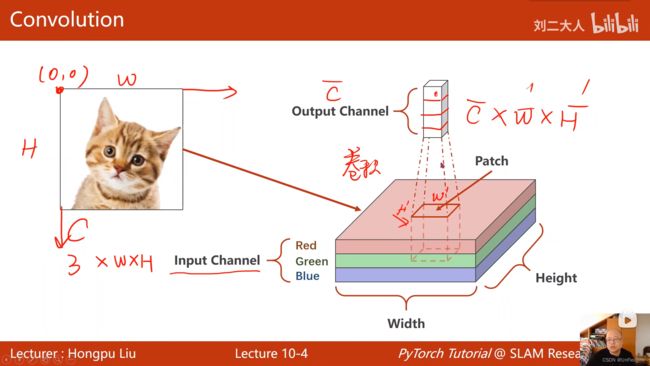
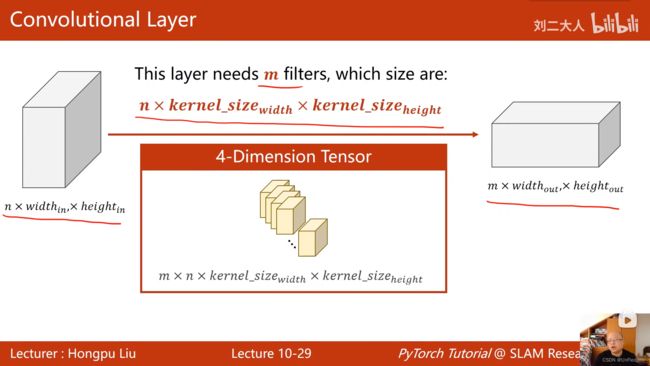
- 卷积核的数量要和输入的通道数(Channel数)相等
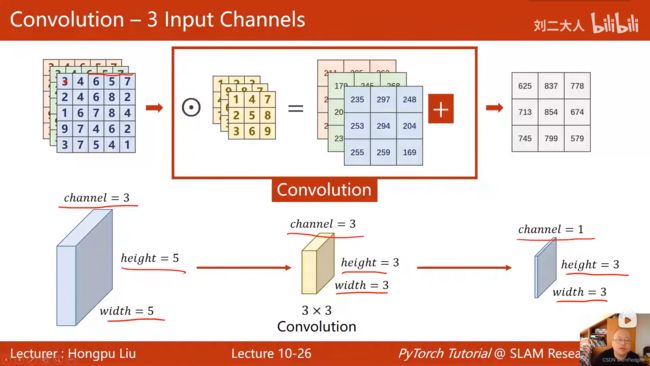
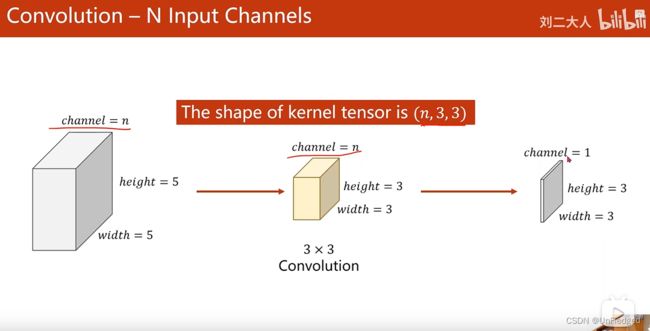
- N个输入channel,1个输出channel:
- N个输入channel,M个输出channel:
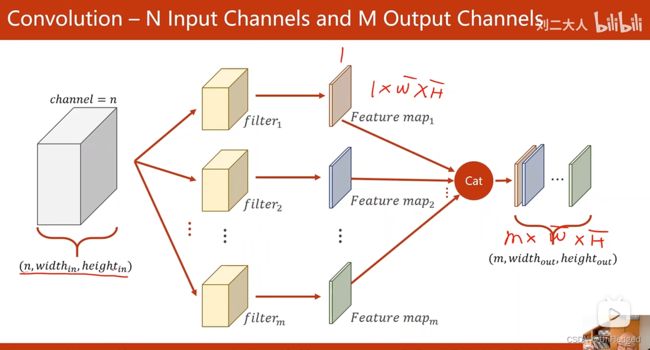
- 构造一层卷积层(4维张量)需要四个维度:输入大小,输出大小,卷积核W,卷积核H
构造卷积层实例代码:
import torch
in_channels, out_channels = 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
inputs = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
outputs = conv_layer(inputs)
print(inputs.shape)
print(outputs.shape)
print(conv_layer.weight.shape)
- 卷积层的其他参数:填充Padding;padding的目的:保持输出的尺寸不会变小
- 一点理解:输入尺寸是100x100,卷积核尺寸3x3,则输出会是98x98;若卷积核大小是5x5,则输出会是96x96,即width,height都会减小3/2=1和5/2=2。结合卷积时的对应相乘关系即可理解。
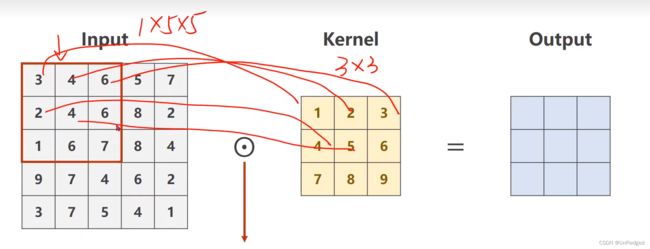
- 如上图,卷积核尺寸是3x3,input中的红框中心4和卷积核中心5对应,则output的尺寸会减少两行和两列
- 卷积层的其他参数:步长Stride;目的:有效减少featuremap的尺寸
- 一个下采样方法:MaxPooling(最大池化);2x2的最大池化层,即stride=2
一个简单的卷积神经网络(注意观察size的变化)
课上代码:
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
# Training complete in 3m 50s
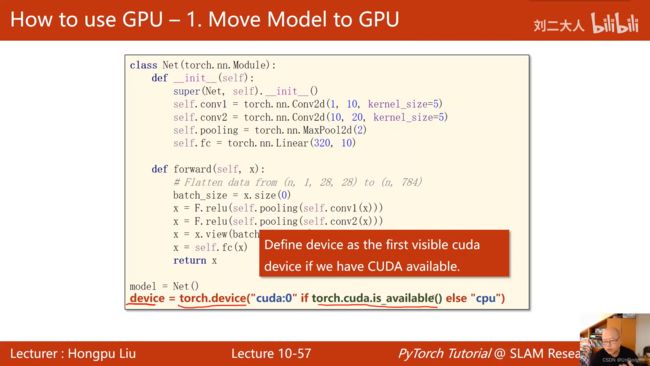
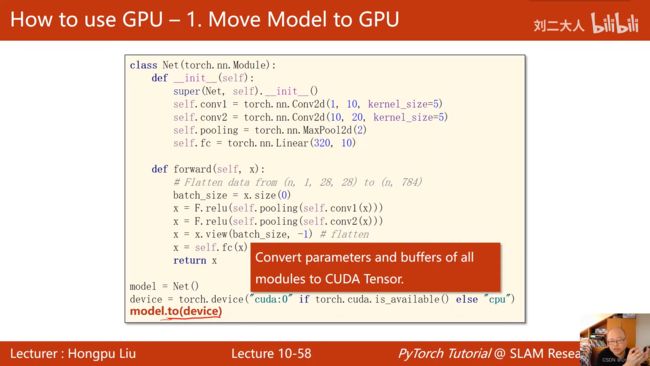
如何把运算迁移到GPU上:
- Move Model to GPU(定义device,把模型参数和显存转换成CUDA Tensor)
- Move Tensors to GPU(在train和test函数中把输入扔进GPU即可)
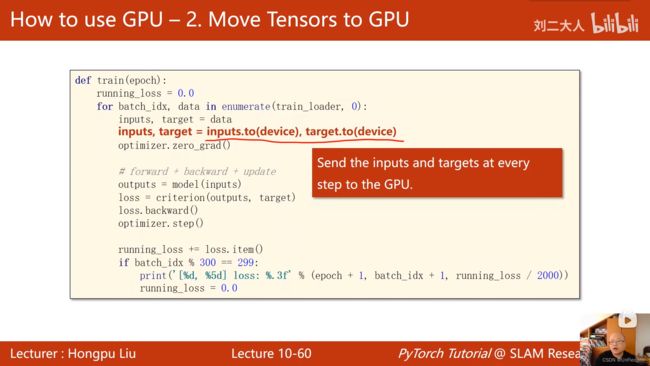
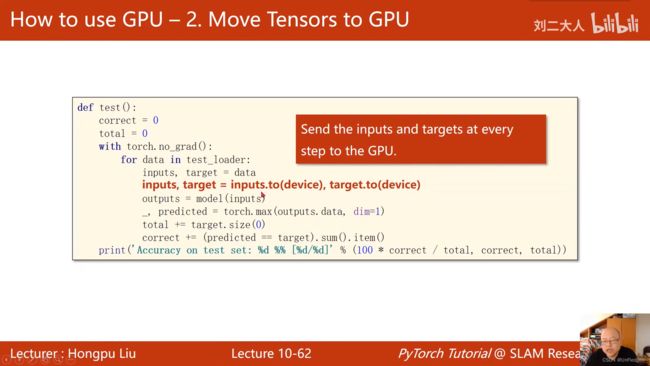
GPU版本代码:
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
# Training complete in 2m 44s
课后作业:自己定义新的卷积神经网络:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv3 = nn.Conv2d(20, 30, kernel_size=3)
self.pooling = nn.MaxPool2d(2)
self.fc1 = nn.Linear(30, 16)
self.fc2 = nn.Linear(16, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = F.relu(self.pooling(self.conv3(x)))
x = x.view(batch_size, -1)
x = self.fc1(x)
x = self.fc2(x)
return x