Python数据分析【第10天】| DataFrame的排序、排名和索引重置(sort,rank,index)
系列文章目录
第1天:读入数据
第2天:read()、readline()与readlines()
第3天:进度条(tqdm模块)
第4天:命令行传参(argparse模块)
第5天:读、写json文件(load()、loads()、dump()、dumps())
第6天:os模块、glob模块
第7天:pandas.DataFrame
第8天:DataFrame的三种数据处理基本操作(df.drop(), df.fillna(), df.drop_duplicates())
第9天:DataFrame的属性编码、数据合并和连接(get_dummies,merge,join,concat)
python数据分析学习第10天记录
- 系列文章目录
- 前言
- 一、今天所学的内容
- 二、知识点详解
-
- 2.1 排序,排名
-
- 2.1.1 排序
-
- 1. sort()函数不适用于DataFrame
- 2. sort_values()将数据按列值大小排列
- 2. sort_index()将数据按索引大小排列
- 4. rank()排名
- 2.2 索引重置
- 总结
前言
上一篇写了DataFrame的属性编码、数据合并和连接,是不是还是挺复杂的呢。今天继续学习pandas模块下对数据处理的另外两种操作:
- 排序,排名
- 索引重置
一、今天所学的内容
主要内容为pandas模块如何对DataFrame这一数据类型进行将数据输入模型前的预处理工作。
二、知识点详解
2.1 排序,排名
2.1.1 排序
#会用到的包
import pandas
import numpy
import datetime
数据的排序主要用于对特征值为数字的属性进行大小的排序。比如考试成绩,程序员关心的工资收入等等。
pandas中对数据的排序大致分为两种方式:根据索引index或者根据值value。主要用到的函数有:sort()、sort_index()、sort_values()。下面呢我们分别介绍一下这三种函数的用法。
1. sort()函数不适用于DataFrame
在这部分我们举一些简单的例子。
#sort().
import pandas as pd
df = pd.DataFrame({"姓名":["张三","李四","王大麻子","王二麻子","顾六"],
"工资":["99","88","77","66","55"]})
df_sort = df.sort() ##将data中的值按生序排列可用于Series,不可用于DataFrame:'DataFrame' object has no attribute 'sort'。
print(df_sort)
执行结果就会报错:
![]()
因此不能对pandas的dataframe套用sort()函数。
那么我们可以使用sort_values()或者sort_index()。
2. sort_values()将数据按列值大小排列
sort_values()是将data上的每一列按照data列上值的大小由小到大排列。下面举一个例子,以列名为“工资”的列进行排序。
#sort_values()
a=df.sort_values(by='工资',axis=0,ascending=True) #将data上的每一行按date列上值的大小由小到大排列。
# a=df.sort_values('工资',axis=0,ascending=True),by=也可以省略。
print(a)
运行结果如下:
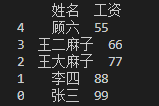
2. sort_index()将数据按索引大小排列
要用到sort_index()函数,首先在构建dataframe时给dataframe定义索引。
因此,我们重新构建了一个dataframe,代码如下:
import pandas as pd
list1 = ['河南','安徽','山西','江西','甘肃','青海']
list2 = ['125','54.25','31.57','49.3','24.59','4.4']
data = {'省份':list1,
'高考人口':list2
}
data_out = pd.DataFrame(data,index=['1','2','3','0','5','4'])
print(data_out)
构建好的dataframe如下图所示:
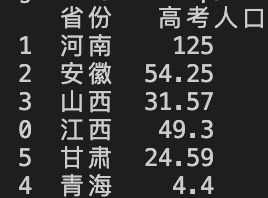
此时,我们观察最左边这一列,就是我们为每一行数据构建的索引。而现在索引是int类型并且没有经过排序的。这时候我们用上sort_index()函数:
#方法3:sort_index()
a=data.sort_index(axis=0,ascending=True) #作用同前。
排序结果如下:
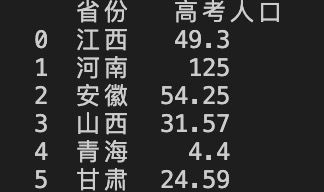
完美~
4. rank()排名
rank()函数可以对dataframe的某列或者某行数据进行排序。
通常,rank()函数的基本类型为:
DataFrame.rank(axis=0,method='average',
numeric_only=None,na_option='keep',
ascending=True,pct=False)
同样让我们举个例子吧:
## 排名会使用到rank()函数
print(data_out)
data_out['排名'] = data_out.高考人口.rank(axis=0,numeric_only=False)
print(data_out)
结果如下:

2.2 索引重置
首先我们要了解重置索引的目的是什么。当我们在清洗数据时往往会将带有空值的行删除,因此删除空行后的DataFrame的index都不再是连续的索引。因此这时要重置索引,以便后续的数据操作。
我们可以使用reset_index()方法来重置它们的索引。
我们举一个reset_index()函数使用的例子吧:
# 索引重置例子
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(42).reshape(6,7), index=[1,3,4,6,8,11])
print(df)

此时用reset_index()来处理该数据,重置索引:
# 索引重置例子
print(df.reset_index())
重置结果如下:

有没有get新技能~
总结
昨天对DataFrame的三种基本操作进行了学习,今天介绍DataFrame的一些数据处理操作: 对数据进行排序、排名以及对索引进行重置。
那么今天就到这里了,明天继续为大家带来DataFrame的数据处理操作。list如下:
- 追加写入Excel
- 转化格式(比如dict)进行保存
祝大家变得更强,明天见!
今天的小tips:
- 高考是一次检验梦想的标准之一。这两天恰逢高考,外甥女也参加了高考。于是今年高考也是我高考之后关注最多的一次。
- 虽然我远在几百公里外,但我就突然理解了当年爸妈在考场外等我考试结束的心。