SA-NET: shuffle attention for deep convolutional neural networks
摘要
注意力机制使得神经网络能够准确地关注输入的所有相关元素,已经成为提高深层神经网络性能的重要组成部分。在计算机视觉的研究中心,主要有两种广泛使用的注意力机制:空间注意和通道注意力,他们分别旨在捕捉像素级的成对关系和通道依赖性。虽然将它们融合在一起可能会比他们各自的实现获得更好的性能,但是这不可避免地会增加计算开销。针对这一问题,本文提出了一种有效的Shuffle Attention模块,该模块采用Shuffle单元来有效的结合两种类型的注意力机制。具体来说,SA首先将通道尺寸分组为多个子特征,然后并行处理他们。然后,对于每个子特征,SA利用一个shuffle单元来描述空间和通道温度上的特征相关性。之后,所有的子特征被聚集,并且采用“channel shuffle”算子来实现不同子特征之间的信息通信。所提出的SA模块是有效的。事实证明所提出的SA通过获得更高的精度的同时具有更低的模型复杂度而显著优于当前的SOTA方法。
introduction
计算机视觉中最常用的注意机制主要有两种:通道注意和空间注意,这两种机制都通过用不同的聚集策略、转换和增强功能聚集来自所有位置的相同特征来增强原始特征[5,6,7,8,9]。基于这些观察,一些研究,包括GCNet [1]和CBAM [10],将空间注意力和通道注意力整合到一个模块中,并取得了显著的改进[10,4]。然而,它们通常要么面临收敛困难,要么面临沉重的计算负担。其他研究设法简化了通道或空间注意的结构[1,11]。例如,ECA-Net [11]通过使用一维卷积简化了在SE块中计算信道权重的过程。SGE [12]将通道的维度分组为多个子特征,以表示不同的语义,并通过用注意力掩模缩放所有位置上的特征向量,将空间机制应用于每个特征组。然而,他们没有充分利用空间和通道注意力之间的相关性,使他们效率较低。“一个人能以更轻但更有效的方式融合不同的注意力模块吗?”
为了回答这个问题,我们首先重温ShuffleNet v2 [13]的单元,它可以高效地构造一个多分支结构,并行处理不同的分支。具体来说,在每个单元的开始,c特性通道的输入被分成两个分支,分别是c-c’和c’通道。然后,采用几个卷积层来捕获输入的更高级表示。在这些卷积之后,两个分支被连接,以使通道的数量与输入的数量相同。最后,采用“信道混洗”算子(在[14]中定义)来实现两个分支之间的信息通信。此外,为了提高计算速度,SGE [12]引入了一种分组策略,该策略将输入的特征地图沿通道维度分成多个组。然后可以并行增强所有子特征。
基于以上观察,本文提出了一种更轻但更有效的深度卷积神经网络的混洗注意模块,该模块将信道的维数分组为子特征。对于每一项子功能,模拟退火算法采用随机单元同时构造通道注意和空间注意。对于每个注意模块,本文设计了一个覆盖所有位置的注意掩模,以抑制可能的噪声,并突出正确的语义特征区域。在ImageNet-1k上的实验结果(如图1所示)表明,所提出的包含较少参数的简单而有效的模块比当前最先进的方法获得了更高的精度。
本文的主要贡献总结如下:1)我们为深层神经网络引入了一个轻量级但有效的注意模块——空间注意模块,它将通道维度分组为多个子特征,然后利用一个shuffle单元为每个子特征集成互补的通道和空间注意模块。2)在ImageNet-1k和MS COCO上的大量实验结果表明,与最先进的注意力方法相比,该方法具有更低的模型复杂度,同时获得了优异的性能。
2.相关工作
多分支架构。CNN的多分支架构已经发展了多年,并且变得更加精确和快速。多分支架构背后的原理是“分裂-转换-合并”,这减轻了训练数百层网络的难度。Inception系列是成功的多分支架构,其中每个分支都经过精心配制,带有定制的内核过滤器,以便聚合更多信息和各种功能。ResNet也可以看做是两个分支网络,其中一个分支是身份映射。SKNets 和 shuffleNet家族都遵循了InceptionNets的思想,为多个分支提供了各种过滤器,但至少在两个重要方面有所不同,SKNets利用自适应选择机制来实现神经元的自适应感受野大小。ShuffleNet进一步将“channel split”和“channel shuffle”操作合并成一个单一的元素操作,以在速度和准确性之间进行权衡。
分组特征。分组学习功能可以追溯到AlexNet,其动机是将模型分布在更多的GPU资源上。Deep Roots 检查了AlexNet,指出卷积组可以学习更好的特征表示。MobileNet和ShuffleNet将每个通道视为一个组,并对这些组内的空间关系进行建模。CapsuleNet将每一个神经元建模为胶囊,其中活动胶囊中的神经元活动表示图像中特定实体的各种属性。SGE开发了封装网络,并且将通道的维度划分为多个子特征,以学习不同的语义。
注意力机制注意力的意义在以前的文献中已经得到了广泛的研究。它偏向于分配信息量最大的特征表达式,同时抑制那些不太有用的表达式。self-attention 方法将一个位置的上下文计算为图像中所有位置的加权和。SE使用通道层模拟了通道关系式。ECA-Net采用一维卷积滤波器生成信道权重,显著降低了SE的模型复杂度。王等人提出了non-local非局部模块,通过计算特征图中每个空间点至极爱你的相关矩阵来生成相当大的注意力图。CBAM、GCNet和SGE将空间注意力和通道注意力串联起来,而DANet通过对来自不同分支的两个注意力模块求和,自适应地将局部特征与它们的全局依赖性结合起来。
3. shuffle attention
在这一部分中,我们首先介绍了构建SA模块的过程,该模块将输入特征图分成组,并使用shuffle Unit将通道注意力和空间注意力整合到每个组的一个块中。之后,所有的子特征被聚集,并且‘channel attention’算子被用来实现不同子特征之间的信息通信。然后,我们对该效果进行了可视化,并验证了所提出的SA的可靠性。整个SA模块的整体架构如图2所示。
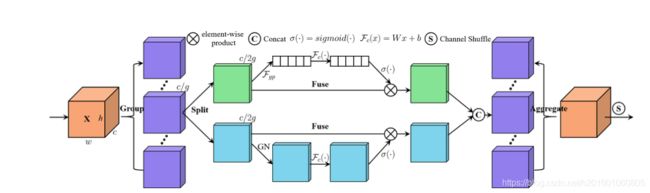
图2 . 一个SA模块的总览。它采用"channel split"并行处理每组子特征。对于通道注意分支,使用GAP生成通道的统计,然后使用一对参数来缩放和移动通道向量。对于空间注意分支,采用分组范数生成空间统计量,然后创建一个类似于通道分支的紧凑特征。然后,这两个分支连接在一起。之后所有的子特征被聚集,最后我们利用一个"channel shuffle"算子来实现不同子特征之间的信息通信。
特征分组。对于给定的特征图X ∈ R(CHW),其中C,H,W分别表示通道编号,空间高度和宽度,SA首先沿着通道维度将X分成G组。X = [X1,· · · , XG],Xk∈ R (C/G×H×W)其中每个子功能Xk在训练过程中逐渐捕获特定的语义响应。然后,我们通过关注模块为每个子特征生成相应的重要系数。具体来说,在每个注意单元的开始,Xk 是输入沿着通道维度分成两个分支,也就是Xk1,Xk2 ∈ R(C/2g×H×W) 如图2所示,一个分支用于通过利用通道的相互关系来产生通道注意图,而另一个分支则利用特征的相互空间关系来产生空间注意图,使得模型可以关注"什么"和"哪里"是有意义的。
通道注意力。一种完全捕获通道相关性的方法是利用23中提出的SE块。但是它会带来太多的参数,从速度和精度之间的权衡来看,这对设计更轻量级的注意力模块是不利的。此外,不适合像ECA那样通过执行更快的大小为k的一维卷积来生成信道权重,因为k往往更大。为了改进,我们提供了一种代替方案,它首先通过简单地使用全局平均池化GAP来嵌入全局信息,以S ∈ R(C/2g×H×W) 生成信道统计,这可以通过空间维度H×W收缩Xk1来计算。
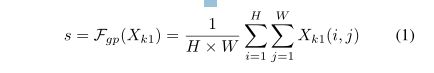
此外,还创建了一个紧凑的特征,以便为精确和自适应的选择提供指导。这是通过sigmod激活的简单门控机制实现的。然后,可以通过以下方式获得频道关注的最终输出
![]()
空间注意力。与通道注意力不同,空间注意力侧重’where’这一信息性部分,是对通道注意力的补充。首先,我们使用X块
上的群范数来获得空间统计。然后采用 Fc()来增强Xk2的表示。空间注意力的最终输出由以下方式获得。
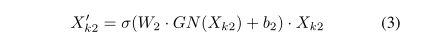
其中 W2 和 b2 是形状同样为R(C/2Gx1x1)的参数。
然后将两个支路串接,使用通道数如输入数相同,即
![]()
聚合之后,所有的子特征被聚集。最后与shuffleNet v2 类似,我们采用了一个’channel shuffle’操作符,使跨组信息流能够沿着通道维度流动。SA模块的最终输出是相同大小的X,使得SA相当容易与现代架构集成。
请注意,W1、B1、W2、B2和组范数超参数只是在SA中引入的参数。单个SA模块中,每个支路的通道数为C/2G。因此总参数是3C/G (通常是32或64),与整个网络的参数相比非常的微不足道。
SA-Net for Deep CNNs为了在深层神经元网络中采用SA,我们利用了SENet完全相同的模块,只是用SA块替换了SE块。
生成的网络叫做SANet
3.1 可视化和解释
以下的内容就比较简单了