CSPNET详解
CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING
CAPABILITY OF CNN
神经网络已经使最先进的方法在计算机视觉任务上取得了令人难以置信的结果,如物体检测。然而,这种成功很大程度上依赖于昂贵的计算资源,这阻碍了拥有廉价设备的人欣赏先进技术。在本文中,我们提出了跨阶段部分网络(Cross Stage Partial Network,CSPNet),从网络架构的角度来缓解之前的作品需要大量推理计算的问题。我们将该问题归结为网络优化中重复的梯度信息。**所提出的网络通过整合网络阶段开始和结束的特征图来尊重梯度的变化,在我们的实验中,在ImageNet数据集上,在同等甚至更高的精度下,减少了20%的计算量,在MS COCO对象检测数据集上,AP50的表现也明显优于最先进的方法。**CSPNet易于实现,而且通用性强,足以应对基于ResNet、ResNeXt和DenseNet的架构。源代码在https://github.com/WongKinYiu/CrossStagePartialNetworks。
1 Introduction
神经网络已经被证明,当它变得更深[7,39,11]和更宽[40]时,它的功能特别强大。然而,扩展神经网络的架构通常会带来更多的计算量,这使得计算量大的任务如物体检测对大多数人来说是难以承受的。由于现实世界的应用通常需要在小型设备上进行短时间的推理,这对计算机视觉算法提出了严峻的挑战,因此轻量级计算逐渐受到了较强的关注。虽然有些方法是专门为移动CPU设计的[9,31,8,33,43,24],但它们所采用的深度可分离卷积技术并不兼容工业IC设计,如边缘计算系统的专用集成电路(ASIC)。在这项工作中,我们研究了最先进的方法,如ResNet、ResNeXt和DenseNet中的计算负担。我们进一步开发了计算效率高的组件,使所述网络能够在不牺牲性能的情况下同时部署在CPU和移动GPU上。
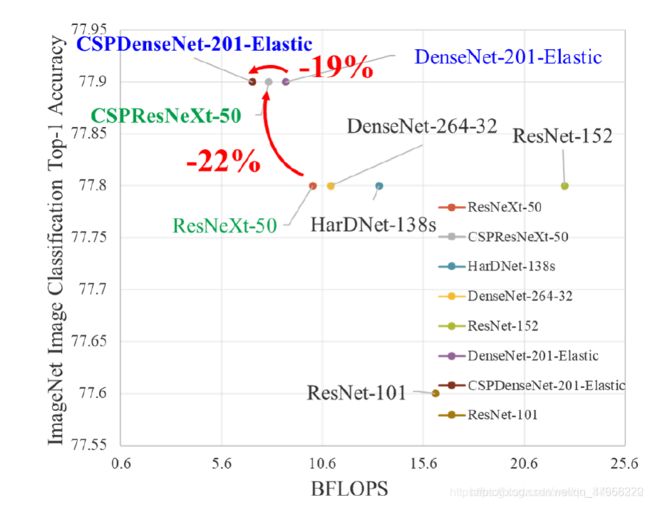
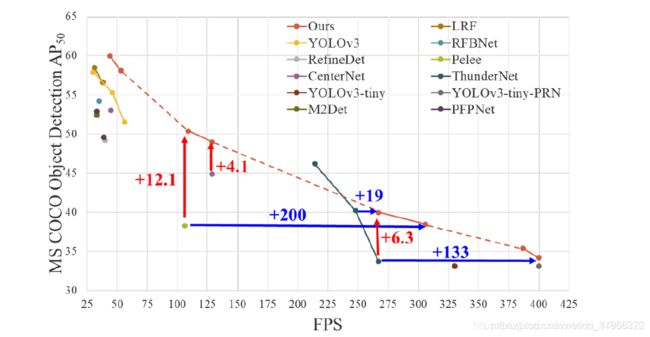
图1:提出的CSPNet可以应用在ResNet[7]、ResNeXt[39]、DenseNet[11]等网络上。它不仅降低了这些网络的计算成本和内存使用量,而且在推理速度和精度上也有好处。
在本研究中,我们介绍了Cross Stage Partial Network (CSPNet)。设计CSPNet的主要目的是使该架构能够实现更丰富的梯度组合,同时减少计算量。这个目的是通过将基础层的特征图分割成两部分,然后通过提出的跨阶段分层(cross-stage hierarchy)结构进行合并来实现的。我们的主要概念是通过分割梯度流,使梯度流在不同的网络路径中传播。通过这种方式,我们证实了通过switching concatenation and transition steps步骤,传播的梯度信息可以有很大的相关性差异。此外,CSPNet可以大大减少计算量,提高推理速度以及精度,如图1所示。所提出的基于CSPNet的对象检测器主要处理以下三个问题。
1) Strengthening learning ability of a CNN 现有的CNN在轻量化后,其精度大大降低,因此我们希望加强CNN的学习能力,使其在轻量化的同时保持足够的准确性。所提出的CSPNet可以很容易地应用于ResNet、ResNeXt和DenseNet。将CSPNet应用于上述网络后,计算量可从10%减少到20%,但在ImageNet[2]上进行图像分类任务的精度优于ResNet[7]、ResNeXt[39]、DenseNet[11]、HarDNet[1]、Elastic[36]和Res2Net[5]。
2) Removing computational bottlenecks 过高的计算瓶颈会导致更多的计算周期来完成推理过程,或者一些算力单元经常闲置。因此,我们希望能够均匀分配CNN中各层的计算量,这样可以有效提升各计算单元的利用率,从而减少不必要的能耗。据悉,提出的CSPNet使得PeleeNet[37]的计算瓶颈减少了一半。此外,在基于MS COCO[18]数据集的物体检测实验中,我们提出的模型在基于YOLOv3的模型上测试时,可以有效降低80%的计算瓶颈。
3) Reducing memory costs 动态随机存取存储器(DRAM)的晶圆制造成本非常昂贵,而且还占用了大量的空间。如果能有效降低存储器的成本,将大大降低ASIC的成本。此外,小面积的晶圆可以用于各种边缘计算设备。在减少内存使用方面,我们采用cross-channel pooli[6],在特征金字塔生成过程中对特征图进行压缩。这样,提出的CSPNet与提出的对象检测器在生成特征金字塔时,可以减少PeleeNet上75%的内存使用量。
由于CSPNet能够促进CNN的学习能力,因此我们使用更小的模型来实现更好的精度。我们提出的模型可以在GTX 1080ti上以109 fps的速度达到50%的COCO AP50。由于CSPNet可以有效地削减大量的内存流量,我们提出的方法可以在英特尔酷睿i9-9900K上以52帧/秒的速度实现40%的COCO AP50。此外,由于CSPNet可以显著降低计算瓶颈,Exact Fusion Model(EFM)可以有效降低所需的内存带宽,我们提出的方法可以在Nvidia Jetson TX2上实现42%的COCO AP50,每秒49帧。
2 Related work
CNN architectures design. 在ResNeXt[39]中,Xie等人首先证明了cardinality可以比宽度和深度的尺寸更有效。DenseNet[11]由于采用了大量重用特征的策略,可以大大减少参数和计算次数。而且它将所有前几层的输出特征连接起来作为下一个输入,可以认为是maximize cardinality。SparseNet[46]将密集连接调整为指数间隔连接可以有效提高参数利用率,从而获得更好的结果。Wang等人通过梯度组合的概念进一步解释了为什么 high cardinality和稀疏连接可以提高网络的学习能力,并发展了partial ResNet(PRN)[35]。为了提高CNN的推理速度,Ma等人[24]介绍了四个需要遵循的准则,并设计了ShuffleNet-v2。Chao等[1]提出了一种低内存流量的CNN,称为Harmonic DenseNet(HarDNet),并提出了一种度量Convolutional Input/Output(CIO),该度量是DRAM流量的近似值,与实际DRAM流量测量成正比。
Real-time object detector. 最著名的两种实时对象检测器是YOLOv3[29]和SSD[21]。基于SSD,LRF[38]和RFBNet[19]可以在GPU上实现最先进的实时对象检测性能。最近,基于anchor-free的物体检测器[3,45,13,14,42]已经成为主流的物体检测系统。这类对象检测器有CenterNet[45]和CornerNet-Lite[14]两种,它们在效率和功效上都有很好的表现。对于CPU或移动GPU上的实时对象检测,基于SSD的Pelee[37]、基于YOLOv3的PRN[35]、基于 Light-Head RCNN[17]的ThunderNet[25]在对象检测上都得到了很好的表现。
3 Method
3.1 Cross Stage Partial Network
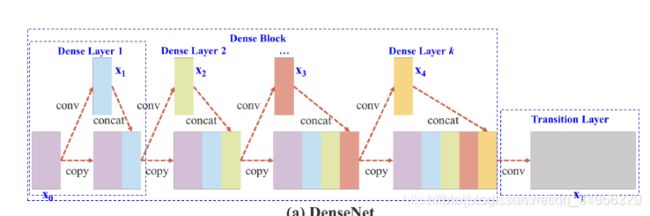
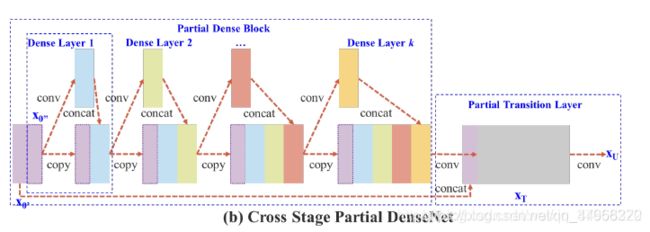
图2:(a)DenseNet和(b)我们提出的Cross Stage Partial DenseNet(CSPDenseNet)的说明。CSPNet将底层的特征图分成两部分,一部分经过dense block和transition 层,另一部分再与transmitted feature map结合到下一阶段。
DenseNet. 图2(a)显示了Huang等人[11]提出的DenseNet的一个阶段的详细结构。DenseNet的每个阶段都包含一个dense block和一个transition 层,每个dense block由k个dense layers组成。第i个dense layers的输出将与第i个dense layers的输入进行串联,串联后的结果将成为(i+1)th
(i+1)thdense layers的输入。显示上述机制的方程可以表示为:

其中*代表卷积操作,[x0,x1,...][x0,x1,...]代表concatenate x0,x1,...,x0,x1,..., wiwi和xi
xi代表第i层dense layer的权重和输出。
利用反向传播算法更新权值,权值更新方程为:
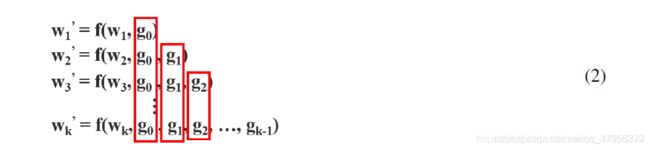
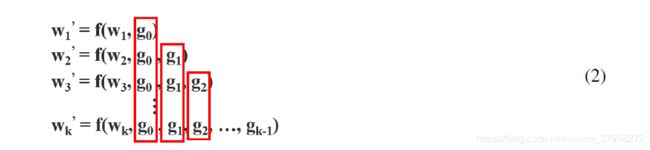


我们可以看到,来自dense layers的梯度是单独集成的(separately integrated)。另一方面,没有经过dense layers的特征图x′0
x0′也是单独集成的(separately integrated)。至于更新权重的梯度信息,两边不包含属于其他边的重复梯度信息。总的来说,提出的CSPDenseNet保留了DenseNet的特征复用特性的优点,但同时通过截断梯度流,防止了过多的重复梯度信息。这一思想通过设计分层特征融合策略并用于partial transition层来实现。
Partial Dense Block. 设计partial dense blocks的目的是:1.)增加梯度路径。通过分割和合并策略,可以使梯度路径的数量增加一倍。由于采用了cross-stage strategy,可以缓解使用显式特征图复制进行拼接所带来的弊端;2.)平衡各层的计算量:通常情况下,DenseNet的base layer的通道数远远大于增长率(growth rate)。由于在partial dense block中,dense layer操作所涉及的layer channels通道只占原数的一半,因此可以有效解决近一半的计算瓶颈。和3.)减少内存。假设DenseNet中一个dense block的base feature map大小为w x h x c,增长率为d,总共有m个dense layers。那么,该dense block的CIO为 (c×m)+((m2+m)×d)/2
(c×m)+((m2+m)×d)/2,partial dense block的CIO为 ((c×m)+(m2+m)×d)/2((c×m)+(m2+m)×d)/2 。虽然m和d通常远小于c,但partial dense block最多能够节省网络一半的memory traffic。
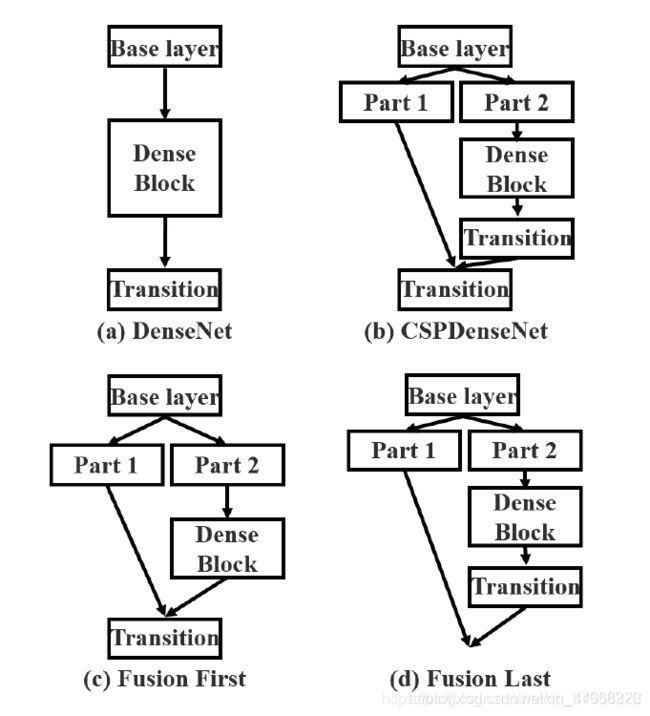
图3:不同类型的特征融合策略。(a) 单路径DenseNet,(b)提出的cspdenset:transition—>concatenation—>transition,(c)concatenation—>transition,以及(d)transition—>concatenation。
Partial Transition Layer. 设计partial transition l的目的是为了最大限度地提高梯度组合的差异。partial transition layer是一种分层特征融合机制,它采用截断梯度流的策略来防止不同层学习重复的梯度信息。在这里,我们设计了两个CSPDenseNet的变体,来展示这种梯度流截断是如何影响网络的学习能力的。3(c)和3(d)展示了两种不同的融合策略。CSP(fusion first)是指将两支路生成的特征图进行concatenate ,然后再进行transition操作。如果采用这种策略,将会reused大量的梯度信息。
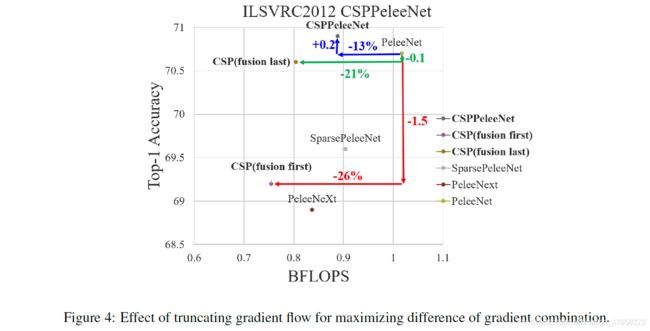
至于CSP(fusion last)策略,dense block的输出会经过transition层,然后与来自第1部分的特征图做concatenation。如果采用CSP(fusion last)策略,由于梯度流被截断,梯度信息将不会被重用。如果我们使用3中所示的四种架构来进行图像分类,相应的结果如图4所示。可以看出,如果采用CSP(fusion last)策略进行图像分类,计算成本明显下降,但top-1的准确率仅下降0.1%。 另一方面,CSP(fusion first)策略确实有助于计算成本的大幅下降,但top-1的准确率明显下降了1.5%。通过across stages的拆分和合并策略,我们能够有效降低信息整合过程中重复的可能性。从图4所示的结果可以看出,如果能够有效地减少重复的梯度信息,网络的学习能力将得到很大的提升。
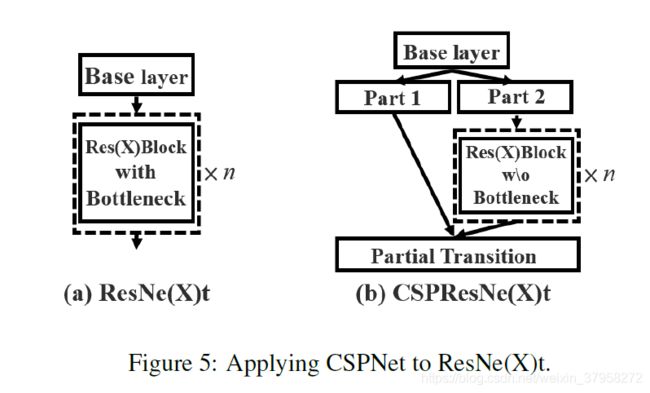
Apply CSPNet to Other Architectures. CSPNet也可以很容易地应用于ResNet和ResNeXt,其架构如图5所示。由于只有一半的特征通道要经过Res(X)Blocks,所以不需要再引入bottleneck layer。这使得FLoating-point OPerations(FLOPs)时内存访问成本(MAC)的理论下限是固定的。
3.2 Exact Fusion Model
Looking Exactly to predict perfectly. 我们提出EFM,为每个anchor捕捉appropriate Field of View(FoV),从而提高one-stage 对象检测器的准确性。对于分割任务,由于像素级标签通常不包含全局信息,因此通常更倾向于考虑更大的patches ,以获得更好的information retrieval[22]。然而,对于图像分类和对象检测等任务,从图像级和边界框级标签观察时,一些关键信息可能会被遮挡。Li等人[15]发现CNN从图像级标签学习时经常会分心,并认为这是 two-stage对象检测器优于one-stage 对象检测器的主要原因之一。
Aggregate Feature Pyramid. 所提出的EFM能够更好地聚合初始特征金字塔。EFM基于YOLOv3[29],它在每个ground truth对象之前精确地分配了一个边界框。每个ground truth边界框对应一个超过阈值IoU的anchor框。如果anchor框的大小相当于网格单元的FoV,那么对于sth
sth尺度的网格单元,相应的边界框将以(s−1)th(s−1)th尺度为下界,以(s+1)th
(s+1)th尺度为上界。因此,EFM集合了三个尺度的特征。
Balance Computation. 由于特征金字塔中的concatenated特征图是巨大的,它引入了大量的内存和计算成本。为了缓解这个问题,我们加入了Maxout技术来压缩特征图。
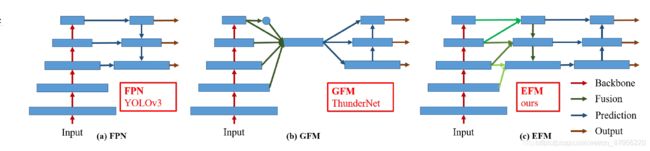
图6:不同的特征金字塔融合策略。(a)特征金字塔网络(FPN):融合当前尺度和之前尺度的特征。(b) Global Fusion Mode(GFM):融合所有尺度的特征。©Exact Fusion Model(EFM):融合特征与anchor的大小有关。
4 Experiments
我们将使用ILSVRC 2012中使用的ImageNet的图像分类数据集[2]来验证我们提出的CSPNet。此外,我们还使用MS COCO对象检测数据集[18]来验证我们提出的EFM。架构的细节将在附录中阐述。
4.2 Ablation Experiments
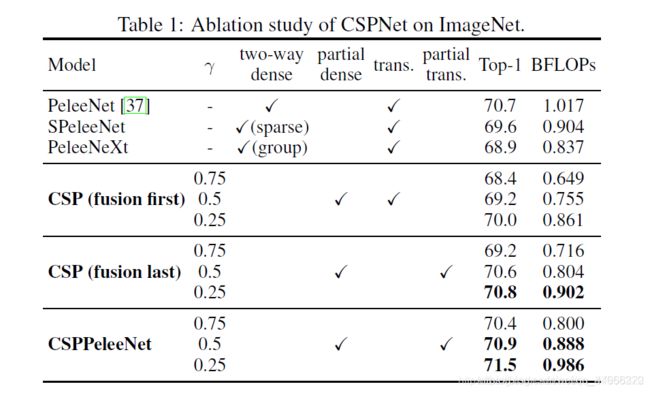
Ablation study of CSPNet on ImageNet. 在CSPNet上进行的消融实验中,我们采用PeleeNet[37]作为基线,用ImageNet来验证CSPNet的性能。我们采用不同的partial rati γ
γ和不同的特征融合策略进行消融研究。表1为CSPNet的消融研究结果。表1中,SPeleeNet和PeleeNeXt分别是将稀疏连接和分组卷积引入PeleeNet的架构。至于CSP(先融合)和CSP(最后融合),则是为了验证partial transition的好处而提出的两种策略。
从实验结果来看,如果只在cross-stage partial dense blo上使用CSP(先融合)策略,性能可以略优于SPeleeNet和PeleeNeXt。但是,为了减少冗余信息的学习而设计的partial transition layer可以获得非常好的性能。例如,当计算量减少21%时,精度只降低了0.1%。需要注意的是,当gamma=0.25时,计算量被削减了11%,但准确率却提高了0.1%。与基线PeleeNet相比,提出的CSPPeleeNet的性能最好,它可以减少13%的计算量,但同时提升了0.2%的精度。如果我们将partial ratio调整为gamma=0.25,我们能够提升0.8%的精度,同时减少3%的计算量。
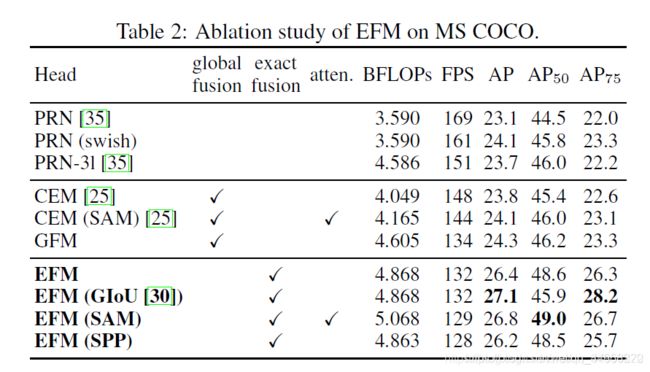
Ablation study of EFM on MS COCO. 接下来,我们将基于MS COCO数据集进行EFM的消融研究。在这一系列的实验中,我们比较了图6所示的三种不同的特征融合策略。我们选择了两个最先进的轻量级模型,PRN[35]和ThunderNet[25]来进行比较。PRN是用于比较的特征金字塔架构,带有上下文增强模块(Context Enhancement Module CEM)和空间注意力模块(SAM)的ThunderNet是用于比较的global fusion architecture。我们设计了一个Global Fusion Model(GFM)与提出的EFM进行比较。此外,GIoU[30]、SPP和SAM也被应用到EFM中进行消融研究。表2中列出的所有实验结果均采用CSPPeleeNet作为骨架。
从实验结果中可以反映出,提出的EFM比GFM慢了2fps,但其AP和AP50分别显著提升了2.1%和2.4%。虽然引入GIoU可以将AP提升0.7%,但AP50却明显降低了2.7%。然而,对于边缘计算来说,真正重要的是对象的数量和位置,而不是其坐标。因此,我们在后续的模型中不会使用GIoU训练。SAM使用的注意力机制与SPP增加FoV机制相比,可以获得更好的帧率和AP,所以我们使用EFM(SAM)作为最终架构。另外,CSPPeleeNet采用swish
activation虽然可以提高1%的AP,但其操作需要在硬件设计上进行查表加速,我们最后也放弃了swish
activation功能。
4.3 ImageNet Image Classification
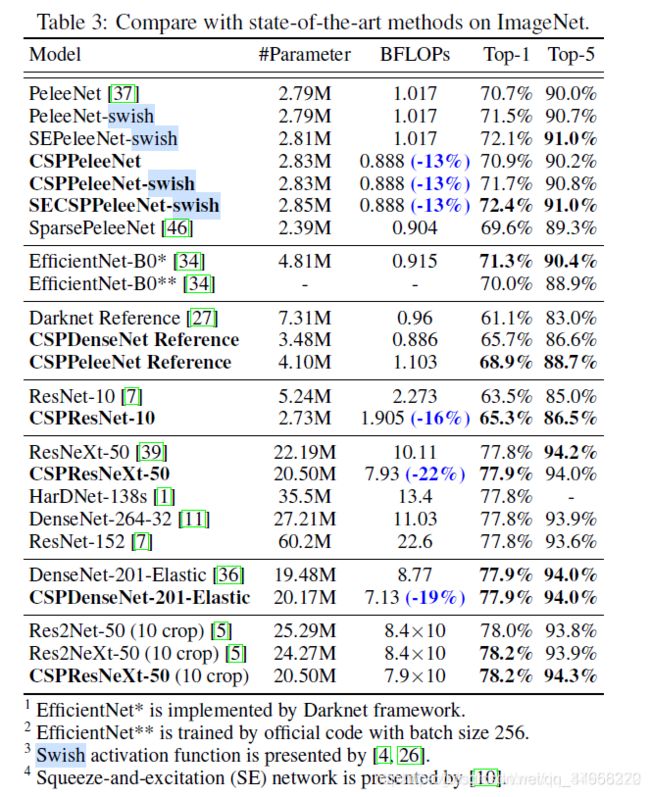
我们将提出的CSPNet应用于ResNet-10[7]、ResNeXt-50[39]、PeleeNet[37]和DenseNet-201-Elastic[36],并与最先进的方法进行比较。实验结果如表3所示。
实验结果证实,无论是基于ResNet的模型、基于ResNeXt的模型,还是基于DenseNet的模型,当引入CSPNet的概念后,计算负荷至少降低10%,精度要么保持不变,要么提升。引入CSPNet的概念,对于轻量级模型的改进尤其有用。例如,与ResNet-10相比,CSPResNet-10可以提高1.8%的精度。至于PeleeNet和DenseNet-201-Elastic,CSPPeleeNet和CSPDenseNet-201-Elastic分别可以减少13%和19%的计算量,要么提升一点,要么保持精度。至于ResNeXt-50,CSPResNeXt-50可以减少22%的计算量,并将top-1的精度提升到77.9%。
如果与最先进的轻量级模型–EfficientNet-B0相比,虽然在批量大小为2048时可以达到76.8%的精度,但当实验环境与我们相同,即只使用一个GPU时,EfficientNet-B0只能达到70.0%的精度。事实上,EfficientNet-B0所使用的Swish激活函数和SE块在移动GPU上的效率并不高。在开发EfficientNet-EdgeTPU的过程中也进行了类似的分析。
在这里,为了证明CSPNet的学习能力,我们在CSPPeleeNet中引入了swish和SE,然后与EfficientNet-B0*进行了比较。实验v中,SECSPPeleeNet-swish减少了3%的计算量,提升了1.1%的top-1精度。
提出的CSPResNeXt-50与ResNeXt-50[39]、ResNet-152[7]、DenseNet-264[11]、HarDNet-138s[1]相比,无论参数量、计算量、top-1精度,CSPResNeXt-50都取得了最好的效果。在10-crop test,CSPResNeXt-50也优于Res2Net-50[5]和Res2NeXt-50[5]。
4.4 MS COCO Object Detection
在目标检测的任务中,我们针对三个目标场景。(1)GPU上的实时性:我们采用CSPResNeXt50与PANet(SPP)[20];(2)移动GPU上的实时性:我们采用CSPPeleeNet、CSPPeleeNet Reference和CSPDenseNet Reference与提出的EFM(SAM);(3)CPU上的实时性:我们采用CSPPeleeNet Reference和CSPDenseNet Reference与PRN[35]。以上模型与最先进方法的比较见表4。至于CPU和移动GPU的推理速度分析将在下一小节详细介绍。
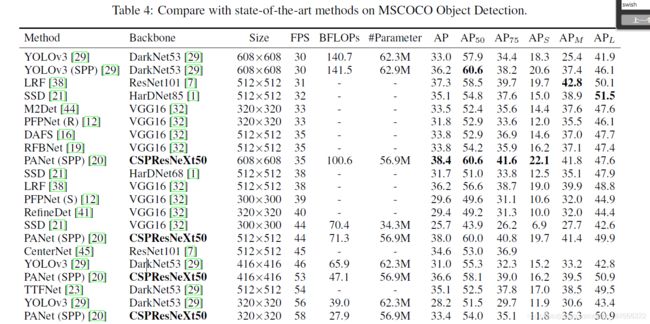
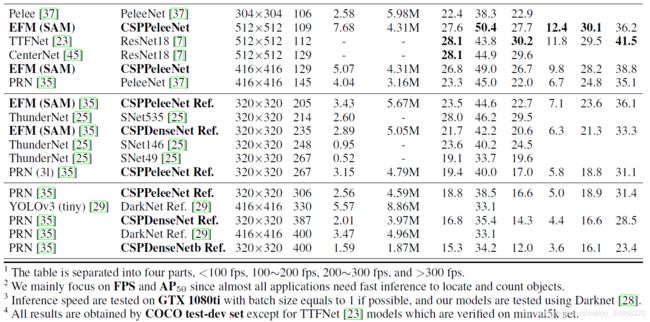
如果与运行在30~100帧/秒的物体检测器相比,CSPResNeXt50与PANet(SPP)在AP、AP50和AP75中取得了最佳性能。它们的检测率分别为38.4%、60.6%和41.6%。如果在输入图像尺寸为512x512的情况下,与最先进的LRF[38]相比,CSPResNeXt50与PANet(SPP)比ResNet101与LRF的性能高出0.7%AP、1.5%AP50和1.1%AP75。如果与运行在100~200 fps的物体探测器相比,CSPPeleeNet与EFM(SAM)在与Pelee[37]相同的速度下提升了12.1%的AP50,在与CenterNet[45]相同的速度下提升了4.1%[37]。
t101与LRF的性能高出0.7%AP、1.5%AP50和1.1%AP75。如果与运行在100~200 fps的物体探测器相比,CSPPeleeNet与EFM(SAM)在与Pelee[37]相同的速度下提升了12.1%的AP50,在与CenterNet[45]相同的速度下提升了4.1%[37]。**
如果与ThunderNet[25]、YOLOv3-tiny[29]和YOLOv3-tiny-PRN[35]等速度非常快的物体检测器相比,提出的CSPDenseNetb Reference with PRN是最快的。它可以达到400帧/秒的帧速率,即133帧/秒的速度比ThunderNet与SNet49。此外,它在AP50上得到0.5%的提升。如果与ThunderNet146相比,CSPPeleeNet Reference with PRN(3l)在保持AP50水平不变的情况下,帧率提高了19帧/秒。