mysql 索引失效情况总结
参考《高性能MYSQL》
mysql索引失效的情况有哪些
索引优化
索引优化应该是对查询性能优化最有效的手段。本文记录一下一些索引失效的情况。方便问题的排查。
1. like的列有索引时,前导模糊查询索引失效
当想模糊查询某字段时,如果是前导模糊查询,如like ‘%XXX’,此时不会走索引,使用**like ‘XXX%’**才会走索引。
业务需要左模糊或者全模糊,可以使用搜索引擎来解决。


2. 索引顺序的重要
组合索引中,不是最左列开始查找,无法使用索引
给user表加上name,age,email三个字段的组合索引。
若查找时,使用最左列,则索引生效,否则索引失效。

组合索引建立:
- 常用字段放在最左边
- 等值条件尽量在最左边
- 离散值较高的字段往左边放
SELECT
COUNT(DISTINCT name)/COUNT(*) name,
COUNT(DISTINCT age)/COUNT(*) age ,
COUNT(DISTINCT email)/COUNT(*) email
from user
按照计算的值由大到小的顺序建立组合索引,值越大证明该字段不为空命中索引几率大。
3. 如果条件中有 or,必须所有列单独使用时能使用索引,否则索引失效
当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效。
一开始usre表里只有name增加了索引,age未有索引,使用or查询name和age时,全表扫描。
把age加上索引,再进行or的查询,使用了索引。

4. 字符串类型,在条件中使用引号引用,否则索引失效
数据类型出现隐式转化。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描。
比如user表里name加上索引,想查找name等于123的人,需要入’123’索引才会生效。

5. Mysql认为全表扫描要比使用索引快时,不使用索引
如表里只有一条数据时
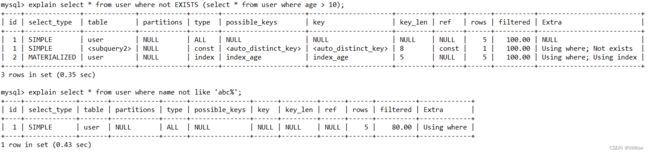
6. 使用负向条件查询,索引失效
负向条件有:!=、<>、not in、not exists、not like 等。可以改为in查询等。
但是经过自己的测试,发现还是会走索引。
user表里name和age均加了索引。
使用!= <> 走了range级别的索引。
使用not in not exists not like 未使用索引。

7. 两个表编码不一致,导致索引失效
创建两个表,分别是文章表和作者表,文章表author_id是作者表中主键,其中结构如下:
CREATE TABLE `article` (
`id` varchar(64) NOT NULL,
`content` longtext NOT NULL,
`title` varchar(50) NOT NULL,
`author_id` varchar(64) NOT NULL,
PRIMARY KEY (`id`),
KEY `article_author_id` (`author_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `author` (
`id` varchar(64) NOT NULL,
`name` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
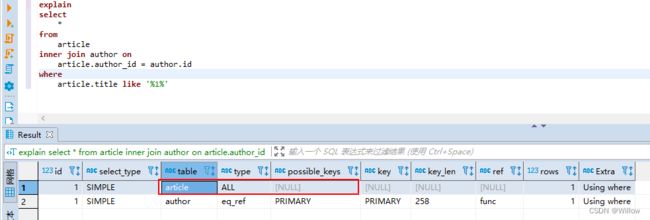
注意两个表的编码一个是utf8,一个是utf8mb4
此时联表查询某个文章和作者信息,sql如下,可以看到执行计划中article表并未走索引
将两个表编码改成一致后(utf8mb4:支持表情包)再测试:
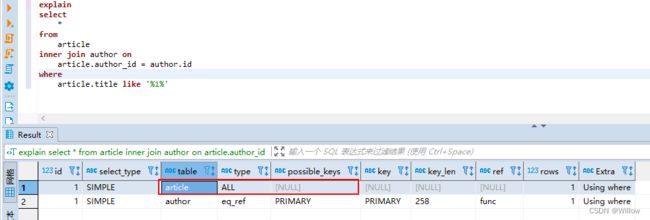
可以看到已经能检测到有索引,但因为测试的是两个空表,所以mysql最终没有使用该索引。
索引创建和删除
创建普通索引
CREATE INDEX index_name ON table_name(column_name);
ALTER TABLE table_name ADD INDEX index_name (column_name) ;
创建唯一索引
唯一索引意味着该字段中的任意两行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name ON table_name(column_name);
ALTER TABLE table_name ADD UNIQUE index_name (column_name) ;
创建组合索引
CREATE INDEX index_name ON table_name(column_name1, column_name2, column_name3);
ALTER TABLE table_name ADD INDEX index_name (column_name1, column_name2, column_name3);
删除索引
DROP INDEX index_name ON table_name;
ALTER TABLE table_name DROP INDEX index_name;