5.RefineDNet论文阅读
RefineDNet:一种用于单幅图像去噪的弱监督细化框架
Abstract
介绍了去雾的重要性——是许多 CV 系统和算法的先决条件。然而在经常在输出中引入恼人的工件,因为它们的先验值很难适应所有情况。
作者的工作:试图将基于先验知识的方法和基于学习的方法的优点结合起来,将去雾任务分为两个子任务,即可见性恢复和真实性改善。
具体来说,我们提出了一个两阶段的弱监督 dehazing 框架 RefineDNet:
- 在第一阶段,RefineDNet 在恢复可见性之前采用暗通道。
- 然后,在第二阶段,对第一阶段的初步去雾结果进行细化,通过使用未配对的模糊清晰图像进行对抗性学习来提高真实性。
- 为了得到更合格的结果,我们还提出了一种有效的感知融合策略来混合不同的去雾输出。
这几年的研究现状都是如此,去雾的 DL 也需要相应的需要分开处理不同模块的东西。
举几个例子:
- Single Image Dehazing via MSCNN-HE 该文中:分为两个比例尺度网络进行不同操作,1. 粗尺度基于整体图像的预测整体传输图;2. 细尺度优化局部去雾效果;我们使用基于整体边缘的网络来细化传输图;3. 最后整体边缘引导网络将整体边缘的结构传递给滤波输出。意义:这消除了孤立和虚假的像素传输估计,同时鼓励相邻像素具有相同的标签。我们在由合成图像和真实模糊图像组成的大量数据集上,对照最先进的方法对所提出的算法进行了评估。
- Pyramid Channel-based Feature 该文中:三尺度特征提取模块、基于金字塔通道的特征注意模块和图像重建模块。 1. 三尺度特征提取模块同时提取不同尺度下的底层空间结构特征和高层上下文特征。2. 特征注意模块 PCFA:利用特征金字塔和通道注意机制,有效地提取互相依赖的通道映射。以金字塔的方式选择性地聚集更重要的特征,用于图像去雾。 3. 重建模块:用于重建特征来恢复清晰图像。
- 本文 RefineDNet:提出了一个两阶段的弱监督 dehazing 框架 RefineDNet。1. 在第一阶段,RefineDNet 在恢复可见性之前采用暗通道。2. 然后,在第二阶段,对第一阶段的初步去雾结果进行细化,通过使用未配对的模糊清晰图像进行对抗性学习来提高真实性。3. 为了得到更合格的结果,我们还提出了一种有效的感知融合策略来混合不同的去雾输出。
Introduce
- 基于先验的方法恢复可见性更好.更多的伪影
- 基于深度学习的方法在提高结果的真实性方面更可取,伪影效果更少,但是雾的厚度更多
与基于先验的去模糊方法不同,基于学习的方法学习估计 A 和 t(x),或通过监督学习直接从输入的模糊图像中恢复 J(x)。由于采用卷积神经网络(CNN)来生成伪影很少的图像,这些方法能够产生真实性令人满意的去雾结果。然而,它们的训练过程需要来自同一场景的大量清晰而模糊的图像对,在现实世界中很难大量收集这些图像对。因此,他们通常会做出权衡,在室内场景中应用 Koschmieder 定律合成模糊图像,在室内场景中可以获得基本的深度信息。由于室内合成图像和真实室外图像之间存在一定差距,基于学习的方法可能会过度拟合合成数据,并且它们去除真实雾霾的能力有限

Fig 1.(a) 由基于学习的方法 AODNet生成。(b) 由基于先验的方法 DCP[8]生成。AODNet 的结果在视觉上更好,但包含更多的雾,而 DCP 以引入伪影为代价去除更多雾。
为了进一步改善去雾效果,利用这两个类别的优点是一个自然的想法,但令人惊讶的是,这种简单的想法在文献中很少被探讨。在这项工作中,基于上述发现,我们提出了一个两阶段的弱监督去雾框架。
在第一阶段,RefineDNet 通过使用 DCP 生成初步结果来恢复输入模糊图像的可见性。我们将 DCP dehazing 嵌入到我们的框架中,以实现端到端的培训和评估。在第二阶段,RefineDNet 通过使用两个细化器网络进行细化,提高了初步去模糊图像的真实性和传输图的质量。在训练期间,我们通过对未配对图像使用鉴别器的对抗性学习来更新细化器网络。这种对未配对数据的弱监督有利于去雾,因为可以从现实世界中收集大量未配对的图像来训练我们的模型。通过这种方式,与在模拟图像上训练并可能过度拟合这些数据的监督方法相比,RefineDNet 更适合处理真实世界的雾图像。
贡献:
- 我们提出了一个两阶段弱监督框架 RefineDNet,该框架首先采用基于先验的 DCP 恢复可见性,然后采用 GANs 提高真实性。
- 我们提出了一种新的感知融合策略来融合不同的去雾结果。我们的实验结果表明,该策略在各种数据集上都是有效的,性能也有所提高。
- 我们还构建了一个包含 6480 幅室外图像的必要的非配对数据集,以便于弱监督去雾方法的相关研究。
RELATED WORK
这项工作与基于先验和基于学习的去雾方法以及生成性对抗网络(GANs)有关。由于近年来 GANs 得到了广泛的探索,主要对其在去雾方面的应用进行了综述。
该部分分为三个部分进行介绍:
- 基于先验的去雾方法
介绍了之前大气散射模型的发展历程和根据该模型产生的一些先验方法,DCP 以及其相应的一些改进方法。然后还有最近的一些 Liu 等人提出了非局部总变差正则化(NLTV),以细化通过边界约束获得的初步传输图。
- 基于深度学习的去雾
随着 CNN 的普及,基于深度学习的方法逐渐应用到去雾领域。介绍了一些经典的 CNN 来去雾的方法。DehazeNet、AOD-Net、MSCNN 等等。最近,基于大气照明对 YCrCb 颜色空间的照明通道的影响大于色度通道的发现,Want 等人提出了采用多尺度 CNN 恢复模糊图像 Y 通道的 AIPNet。但是这些方法都是以来成对图像的监督,而本文的方法对未配对数据的监督较弱。
- 使用 GANs 的方法
GAN 的来源于一个论文,其中一个生成器和鉴别器以对抗的方式参与训练中的 maximin 游戏。许多研究已经证明,GANs 在图像生成和恢复领域具有优越性。作为利用未配对数据的先驱,利用三个生成器从模糊的输入中生成去模糊的图像、传输图和环境光,然后借助多尺度鉴别器进行对抗性训练。
PROPOSED FRAMEWORK
在本节中,将详细介绍提出的 RefineDNet。我们首先介绍了它的总体结构,然后回顾了如何获得 DCP 的初步去雾结果,这对 RefineDNET 至关重要。然后,对感知融合进行了详细分析。最后,描述了损失函数。
总体框架
-
总体框架图示
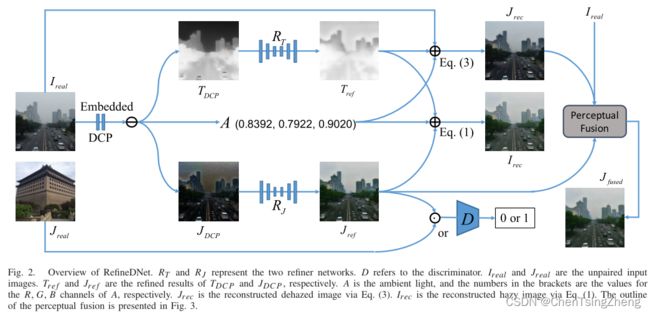
1.1 划分为两个阶段的框架:如该图所示,包括两个阶段。第一个阶段用 DCP 生成环境光 A,初步去雾图像的 J D C P J_{DCP} JDCP和传输图 T D C P T_{DCP} TDCP。然后在第二阶段, T D C P T_{DCP} TDCP由 refiner network (这里翻译成优化网络?不是很懂严格翻译,所以使用原文的refiner network) R T R_T RT优化到 T r e f T_{ref} Tref,并且 J D C P J_{DCP} JDCP由另一个 refiner network R J R_J RJ优化为 J r e f J_{ref} Jref。值得注意的是,DCP 阶段是直接嵌入到 RefineDNet 中的,因此, I r e a l I_{real} Ireal是唯一的输入。同时,图 2 指出天空区域的 T r e f T_{ref} Tref值大于其真实值。但是天空区域的 T r e f T_{ref} Tref值不影响去雾效果。
1.2 弱监督学习:在训练的过程中,为了确保 T r e f T_{ref} Tref被适当优化,我们使用 T r e f T_{ref} Tref, J r e f J_{ref} Jref和根据大气散射模型里面的 A A A将模糊输入重建为 I r e c I_{rec} Irec。然后,通过最小化 I r e a l I_{real} Ireal和 I r e c I_{rec} Irec的距离来更新优化器 R T R_T RT。还有一个用D表示的附加鉴别器,它在获得清晰样本 J r e a l J_{real} Jreal之前接收 J r e a l J_{real} Jreal,用以实现对抗性学习。由于没有要求必须从模糊输入 I r e a l I_{real} Ireal的同一场景中获取 J r e a l J_{real} Jreal,因此整个框架的监督很弱。在RefineDNet中,D在薄弱的监管中起着至关重要的作用。没有D,我们就无法进行对抗性学习,因此, R J R_J RJ也不会得到适当的更新。
1.3 去雾感知融合:在该网络中,虽然 J r e f J_{ref} Jref是一个去雾图像,但是它不适合任何物理模型,为了获得更合格的结果,将其重述为:
J r e c ( x ) = I r e a l ( x ) − A T r e f ( x ) + A J_{rec}(x)=\frac{I_{real}(x)-A}{T_{ref}(x)}+A Jrec(x)=Tref(x)Ireal(x)−A+A -
其中参数和相应过程
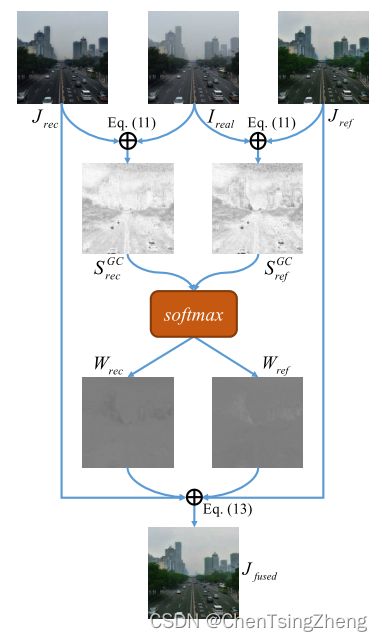
R T R_{T} RT和 R J R_{J} RJ代表两个 refiner network. D D D指鉴别器。 R r e a l R_{real} Rreal和 J r e a l J_{real} Jreal是未配对的输入图像。 T r e f T_{ref} Tref 和 J r e f J_{ref} Jref 分别给出了 T D C P T_{DCP} TDCP和 J D C P J_{DCP} JDCP的精确结果. A A A是大气光,括号中的数字是A的R、G、B三通道的值。 J r e c J_{rec} Jrec是通过等式3重建的去雾图像, I r e c I_{rec} Irec是通过等式1重建有雾图像。感知融合如下图所示。
网络结构:为了验证是RefineDNet的图形有效性而不是骨干网络,我们采用了CycleGAN提供的骨干网络来实现 R T R_T RT, R J R_J RJ,并且D没有采用最新的去雾管道中流行的任何多尺度和其他特殊结构。具体来说, R T R_T RT是一个U-Net包括了8个上采样和下采样的卷积层, R J R_J RJ是一个ResNet,有9个残差块组成。D是包括5个卷积层的CNN。
预处理DCP结果
DCP被嵌入到RefineDNet中来支持端到端的训练和推理。
- 暗通道提取:对于输入的RGB图像I,我们可以计算通道方面的最小值,将其表示为 I m i n I^{min} Imin。然后,我们将大小为 5 × 5 5 \times 5 5×5的核最大池化于 I m i n I^{min} Imin的加逆运算,然后得到加逆后的池化结果作用与 I d a r k I^{dark} Idark,提取出来的暗通道可以被公式表示为:
I d a r k ( x ) = − m a x p o o l ( − m i n c ∈ R , G , B ( I c ( x ) ) ) I^{dark}(x)=-maxpool(-min_{c \in R,G,B}(I^c(x))) Idark(x)=−maxpool(−minc∈R,G,B(Ic(x))) - 传输估计:我们得到了Koschmieder定律两边的暗通道,
I d a r k ( x ) = J d a r k ( x ) t ( x ) + A ( 1 − t ( x ) ) I^{dark}(x)=J^{dark}(x)t(x)+A(1-t(x)) Idark(x)=Jdark(x)t(x)+A(1−t(x))
其中 I d a r k ( x ) I^{dark}(x) Idark(x)和 J d a r k ( x ) J^{dark}(x) Jdark(x)是图像I和J在x像素的暗通道,根据DCP的假设,自然图像的大多数非天空面片中的像素的强度值至少在一个颜色通道Jdark(x)中接近于零。那么
t ( x ) = 1 − I d a r k ( x ) A t(x)=1-\frac{I^{dark}(x)}{A} t(x)=1−AIdark(x).
如果A已知,则可以相应地获得 T D C P T_{DCP} TDCP。此外,我们还采用了引导滤波器来实现 T D C P T_{DCP} TDCP的平滑。引导滤波器也嵌入到我们的框架中,并使用一个平均池实现,内核大小为19×19,步长为1 - 环境光估计和去模糊图像:对于A,由于图像中的大像素值(例如,天空区域的像素值)非常接近环境光,因此将拾取 I d a r k ( x ) I^{dark}(x) Idark(x)中最亮的0.1%像素,并将其在I(x)的颜色通道中的值平均为A。
感知融合
由于 J r e f J_{ref} Jref和 J r e c J_{rec} Jrec是用其自己的方式产生的,因此很有可能在某些区域比另外一个效果更好。从这个意义上讲,如果 J r e f J_{ref} Jref和 J r e c J_{rec} Jrec中更好的区域被赋予更大的权重,那么可以通过融合 J r e f J_{ref} Jref和 J r e c J_{rec} Jrec来获得更好的结果。
由于 J r e f J_{ref} Jref和 J r e c J_{rec} Jrec都是有良好可见性的去雾图像,它们与任意归一化权重的融合不应该影响其可见性。因此,我们基于图像真实性进行融合。因为 I r e a l I_{real} Ireal是真实性很高的自然图像,所以 I r e a l I_{real} Ireal…
- 特征提取
- 相似度计算
- 融合权重
- 适应融合多个结果
损失函数
RefineDNet的损失函数包括3项,即对抗性损失 L G L_G LG、重构损失 L r e c L_{rec} Lrec和identity loss L i d t L_{idt} Lidt。
- 对抗性损失,最初用于以敌对方式更新生成器和鉴别器,在实验中, L G L_G LG用于监督 R J R_J RJ和 D D D。定义如下:
L G ( R J , D ) = E J r e a l ∼ J r e a l [ l o g D ( J r e a l ) ] + E J D C P ∼ J D C P [ l o g ( 1 − D ( R J ( J D C P ) ) ) ] L_G(R_J,D)=\mathbb{E}_{J_{real}\sim\mathcal{J_{real}}}[logD(J_{real})]\\~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~+\mathbb{E}_{J_{DCP}\sim\mathcal{J_{DCP}}}[log(1-D(R_J(J_{DCP})))] LG(RJ,D)=EJreal∼Jreal[logD(Jreal)] +EJDCP∼JDCP[log(1−D(RJ(JDCP)))] - 重建损失,对重建的模糊图像进行正则化,我们将 L r e c L_{rec} Lrec定义为 I r e a l I r e c I_{real}I_{rec} IrealIrec之间的距离,公式如下:
L r e c = ∥ I r e a l − I r e c ∥ L_{rec}=\parallel I_{real}-I_{rec}\parallel Lrec=∥Ireal−Irec∥
其中 ∥ ⋅ ∥ \parallel \cdot \parallel ∥⋅∥表示距离度量。 I r e a l I_{real} Ireal是有雾图像输入, I r e c I_{rec} Irec是通过公式一获得的。 - Identity loss如下:
L i d t = ∥ J r e a l − R J ( J r e a l ) ∥ L_{idt}=\parallel J_{real}- R_J(J_{real})\parallel Lidt=∥Jreal−RJ(Jreal)∥ - 所有损失函数,综合所有损失条款,整体为:
R T ∗ , R J ∗ = a r g m i n R T , R J m a x D λ L G + L r e c + L i d t R_T^*,R_J^*=\mathop{argmin}\limits_{ R_T,R_J}\mathop{max}\limits_{D}\lambda L_G+L_{rec}+L_{idt} RT∗,RJ∗=RT,RJargminDmaxλLG+Lrec+Lidt
其中λ是表示 L G L_G LG权重的超参数。λ的默认值设置为0.02。
EXPERIMENTS AND DISCUSSIONS
即实验目的和实验过程以及实验的环境,还有一些消融实验证明所提出的框架是否有效
实验协议
介绍了实验的数据集和评价指标以及实验的细节
实验数据还是来源于RESIDE-standard。(具体细节可以看有关该数据集的论文,这个数据集也是这几年去雾论文用的比较多的数据集)
- 室内训练数据集。ITS,训练了RefineDNet和其他基于学习的模型。ITS包含了13990张清晰和合成模糊图像对,这些图像由NYU-Depth第二版本的深度数据集合成生成。但是该论文中没有使用ITS的成对信息,而是在RefineDNet训练期间随机打乱图像。
- 室内评估:我们在RESIDE-standard的测试集SOTS(合成目标测试集)和D-HAZY的跨域Middlebury部分上评估了不同的去雾方法。SOTS以与ITS相同的方式生成了500个室内对。D-HAZY的Middlebury部分包含23个室内对,这些室内对是由Middlebury数据集的图像和高质量深度图生成的。根据之前的研究,我们采用PSNR和SSIM作为SOTS和D-HAZY的评估指标。
- 室外训练集:有些图像不适合在该范围内,例如在非常低的分辨率或者室外强阳光下。所以,手动选择了高质量的多云图像。对于雾霾模糊图像,过滤了明显伪影或者模糊的低质量图像。最终选择了3577副清晰图像和2903幅图像作为训练集,存放在RESIDE-unpaired数据集李沐。
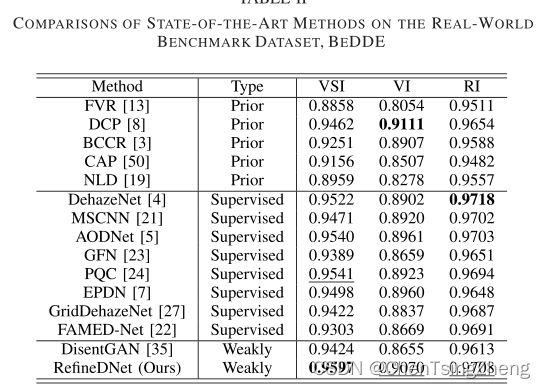
- 室外评估:采用了真实户外基准数据集BeDDE和推荐指标VSI、VI、RI,这个数据集包含了208对清晰和雾图。是在中国23个省会城市不同天气条件下采集的。
- 实现细节:
对应参数 值 平台 Pytorch 显卡 Nvidia Titan X 优化器 Adam 学习率 0.0002 λ \lambda λ 0.02 α \alpha α 0.4
与最新方法的比较
对比数据表格

下划线为第二好的,加粗字体为最好效果的方法。FAMED-Net是关于SOTS数据集第二好的方法
视觉效果

室外效果
这边是我自己使用了3个Net的效果:
-
原始雾图如下:

-
AOD-Net去雾:

-
FFA-Net去雾:
-
RefineDNet去雾:
效果贼好的一个图片

去雾后效果:
后续更新:上面的视觉效果最好的图片其实用DCP也是一样的效果,怎么说呢。。。懂得都懂了。
后面的细节有兴趣的可以自己去原文看一下。
代码在Github上作者也公开了
同时这几个网络的代码我都一一写下来
- AOD-Net
- FFA-Net
- RefineDNet
代码如果跑不通的问题我有空可以帮忙看一下的,作者给的一般都挺好跑通的,真有问题可以私聊或者下面留言。
消融实验
分析两阶段去噪:我们旨在证明RefineDNet的主要思想的有效性,即首先用先验恢复可见性,然后通过基于学习的细化提高结果的真实性。因此,我们将RefineDNet与三条基线DCP、CycleGAN和BasicNet进行比较。DCP是基于先验的方法选择用于RefineDNet的第一阶段。cycleGAN是一种通用的非成对图像到图像的转换框架。BasicNet的结构与RefineDNet的第二阶段完全相同,但采用 I r e a l I_{real} Ireal作为输入,而不是 T D C P T_{DCP} TDCP和 J D C P J_{DCP} JDCP。我们对cycleGAN、BasicNet和RefineDNet进行了ITS培训,并对其进行了SOTS评估。表三提供了评价结果。

如表三所示,RefineDNet的表现优于其他方法,由于BasicNet和RefineDNet之间的唯一区别在于是否分为两个阶段,因此可以清楚地证明,通过先恢复先验的可见性,然后通过基于学习的精细化来提高真实性,这样做是非常合理和有效的。