Towards Robust Deep Hiding Under Non-Differentiable Distortions for Practical Blind Watermarking论文阅读
Towards Robust Deep Hiding Under Non-Differentiable Distortions for Practical Blind Watermarking
发表在 MM '21: Proceedings of the 29th ACM International Conference on MultimediaOctober 2021
翻译:实用盲水印中不可微失真下的鲁棒深度隐藏
Abstract
数据隐藏是一种广泛使用的通过盲水印来证明所有权的方法。
作者紧接着介绍了在水印图像后插入攻击层来提高鲁棒性的方法,该方法缩写(ASL),通常是用增强的角度来解释这种方法获得的鲁棒性增强的效果。本文通过分解这种攻击的前向和后向传播,从一个新的角度来探索这种收益。发现主要影响因素不是前向和后向传播。
Introduction
互联网已经成为最方便、最经济的远程通信媒体之一。
引申到图像的重要性,从而突出数据隐藏的作用。但是数据隐藏在社交媒体上分享介于流量带宽的限制会被压缩,从而导致破坏隐藏的水印。因此,抗压缩数据隐藏是一个热门的研究方向。
深度学习在图像中隐藏数据方面也显示出巨大的成功。为了提高对失真的鲁棒性,广泛认可的简单而有效的方法是在训练期间在水印图像后插入一个攻击模拟层(ASL)。
但是关于 ASL 有效的原因很少被研究。通过该方法提高鲁棒性的收益是通过数据增强的角度的来解释,这里就是作者的研究工作了,从一个新的角度来探索其鲁棒性为何提高了。
通过分解,我们定义了前向 ASL 和后向 ASL,并发现前向 ASL 实现了与标准 ASL 相当(略差)的性能,而后向 ASL 只略微提高了鲁棒性。我们的结果表明,ASL 的主要影响成分是前向传播而不是后向传播。标准 ASL 对前向 ASL 的优势在经验上归因于过度拟合
将标准 ASL 应用于深度信息隐藏的管道以提高对有损压缩的鲁棒性,其挑战在于它们是不可区分的。在观察到正向 ASL 实现了可比性能的启发下,作者提出了正向 ASL 作为一种替代的 ASL 方法来解决这个不可区分的挑战。进一步证明,前向 ASL 可以应用于黑箱失真
Related Work
1.Deep Learning Based Robust Data Hiding
传统的最早工作是探索直接操作覆盖图像的像素,在空间域中嵌入隐藏的信息,LSB 是最经典的例子。为了提高鲁棒性,现在的趋势是转向在变换域中进行隐藏,如离散余弦变换(DCT),离散小波变换,或它们的混合物。除了在广泛的应用中获得成功之外,深度学习也在数据隐藏中找到了自己的应用(A study on digital image and video watermarking schemes using neural networks)这一篇是最早的研究?
在容量、鲁棒性和安全性方面展示了与传统方法相当或更高的性能。现在的趋势已经从在整个数据隐藏管道的某个阶段采用 DNNs。
- (Hiding images in plain sight: Deep steganography)这篇文章展示了在图像中隐藏完整图像的可能性。
- (Generating steganographic images via
adversarial training)这篇文章讲到了用对抗性学习隐藏二进制数据。上述的深度学习方法没有考虑到鲁棒性,隐藏的数据很容易被常见的有损压缩(如 JPEG)所破坏。在训练过程中,在水印图像后插入 ASL 模块被广泛认为是提高对预期失真的鲁棒性的最有效方法。
这种方法对大多数常见的失真有效,但对无差异的 JPEG 却无效。为了克服 "真正的 "JPEG 是不可区分的这一挑战, - (Hidden: Hiding data with deep networks.)提出用两种近似方法来 "区分 "JPEG 压缩,即 JPEGMask 和 JPEG-Drop。在它们和 "真正的 "JPEG 之间存在着巨大的差距,导致在 "真正的 "JPEG 下测试时性能很差。为了最小化近似和 "真实 "JPEG 之间的差距
- (ReDMark: Framework for residual diffusion watermarking based on deep
networks.)提出了一种新的方法来仔细模拟 "真实 "JPEG 的重要步骤 - (A novel two-stage separable deep learning framework for practical blind watermarking)中引入了两阶段的可分离训练,将其扩展到 JPEG 以外的一般不可微分的和/或黑箱的失真
2.Lossy Data Compression Beyond JPEG
这里就是简单介绍了 JPEG 压缩和 JPEG2000 压缩。
- Jpeg:DCT->量化,如果是彩图,先进行颜色变换的预处理,颜色变化->DCT->量化
- Jpeg2000:DWT->量化。
- 2010 年,谷歌开发了一种名为 WebP 的新图像格式,它与基于 DCT 变换的 JPEG 类似,但在压缩率方面优于 JPEG。对于视频有损压缩,MPEG 是最广泛采用的方法
Preliminary Knowledge
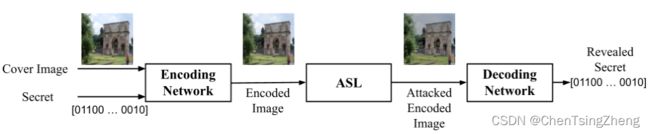
这个章节主要介绍了 4 个部分,这 4 个部分还是目前比较主流的 DNN 关于 watermarking 的结构:
-
编码网络 E:记作参数 θ E \theta_E θE,接受载体图像 I C ∈ R H × W × C I_C\in R^{H \times W\times C} IC∈RH×W×C,其中 H H H和 W W W代表高宽,而 C C C是一个彩色图像,同时 S ∈ [ 0 , 1 ] K S\in [0,1]^K S∈[0,1]K是指长度为 K 的秘密消息,网络最终输出一个编码图像 I E ∈ R H × W × C I_E \in R^{H\times W\times C} IE∈RH×W×C。
- 完成了将秘密信息嵌入到载体图像的任务,将载体图像通过堆叠卷积转化为一个中间表示。然后秘密信息严重中间表示的高度和宽度尺寸复制,使得通道维度等于秘密信息长度 K。这个秘密信息块与载体图像的中间表示相连接,并被送入一个后续的卷积块。编码器的输出被表示为 I E I_E IE
-
攻击模拟层 ASL:接受载体图像 I C I_C IC和编码图像 I E I_E IE并施加诸如 JPEG 压缩这样的攻击,生成攻击后的编码图像 I E ′ I^{'}_E IE′
- 实现了提高深藏管道对失真/攻击的鲁棒性的目的,例如模拟随即噪音或者 JPEG 压缩攻击。ASL 接收 I E I_E IE并且应用攻击,产生一个被攻击的编码图像 I E ′ I^{'}_E IE′。在这项工作中,作者分析了 ASL 向前和向后传播的影响。
-
解码器网络 D:记作参数 θ D \theta_D θD,接收 I E ′ I^{'}_E IE′同时从该参数检索出秘密信息 S ′ S^{'} S′
- 解码器的目的是从被攻击的编码图像 I E ′ I^{'}_E IE′中检索出秘密的 S ′ S^{'} S′。它由几个卷积层组成,将 I E ′ I^{'}_E IE′转化为 K 通道的表示,通过全局空间平均池化,从中得到一个长度为 K 的矢量。最后,应用线性层来获得恢复的秘密 S ′ S^{'} S′。
-
鉴别器 T:记作参数 θ T \theta_T θT,接收载体图像 I C I_C IC或者编码图像 I E I_E IE,目标是通过输出概率 T ( I ) ∈ [ 0 , 1 ] T(I)\in [0,1] T(I)∈[0,1]来区分这两者。
- 为了进一步提高容器图像的视觉质量,使用了一个鉴别器,以区分载体图像和编码图像。鉴别器的结构与解码器的结构类似。
-
损失函数:损失函数由几个部分组成。
- 第一个目标是保持 I C ′ I^{'}_C IC′和 I E ′ I^{'}_E IE′之间的视觉相似度。因此,损失的一部分是负责最小化这两幅图像之间的距离,这是通过基于 ℓ2 的损失实现的:
L E 1 = ∥ I C − I E ∥ 2 2 H W C L_{E1}=\frac{{\parallel I_C-I_E \parallel}^2_2}{HWC} LE1=HWC∥IC−IE∥22 - 第二个是鉴别器损失,表明鉴别器又识别编码图像的能力:
L E 2 ( I E ) = l o g ( 1 − T ( I E ) ) L_{E2}(I_E)=log(1-T(I_E)) LE2(IE)=log(1−T(IE)) - 最后,为了尽可能检索出秘密信息。部署一个简单的 l 2 l_2 l2损失:
L S = ∥ S − S ′ ∥ 2 2 L_{S}=\parallel S-S^{'}\parallel ^2_2 LS=∥S−S′∥22 - 给定两个加权系数 λ E 1 \lambda_{E1} λE1和 λ E 2 \lambda_{E2} λE2,总损失为:
L t o t a l = L S + λ E 1 L E 1 + λ E 2 L E 2 L_{total}=L_{S}+\lambda_{E1}L_{E1}+\lambda_{E2}L_{E2} Ltotal=LS+λE1LE1+λE2LE2 - 鉴别器损失为经典的 GAN 网络的损失函数:
L T = l o g ( 1 − T ( I C ) ) + l o g ( T ( I E ) ) L_T=log(1-T(I_C))+log(T(I_E)) LT=log(1−T(IC))+log(T(IE))
- 第一个目标是保持 I C ′ I^{'}_C IC′和 I E ′ I^{'}_E IE′之间的视觉相似度。因此,损失的一部分是负责最小化这两幅图像之间的距离,这是通过基于 ℓ2 的损失实现的:
-
衡量标准。为了评估深度隐藏架构的有效性,我们主要使用两个指标:误码率(BER)和峰值信噪比(PSNR)。误码率是衡量深层水印管道鲁棒性的一个指标,它表示为秘密信息 S 和显露的秘密信息 S′之间不相等的比特数与秘密长度的比率。由于秘密是由二进制信息组成的,50%的误码率相当于一个随机猜测。PSNR 测量封面图像和编码图像之间的图像失真,可以被解释为编码图像的保密性。对于误码率,数值越低越好,而对于 PSNR,数值越高越好。自然地,这两个指标之间会产生一个权衡。为了降低误码率,往往要牺牲隐蔽性,反之亦然。
Disentangling ASL(分解 ASL)
作者这里提到了尽管 ASL 被广泛使用了,但是背后为何增强鲁棒性的原因还是很少人调查。插入这样一个 ASL 模块的基本动机在某种程度上可以通过增强的角度进行解释。例如,通过用相关的增强物(如高斯噪声)对样本进行增强,来提高模型的泛化能力是一种常见的做法。
这一章的关键在于将 ASL 分解为两块,一个前向 ASL 和一个后向 ASL
-
正向 ASL 的定义:编码后的图像在送入解码器之前要经过 ASL,但来自解码器的梯度是直接反向传播到编码器的,而不经过 ASL 模块。
通常,通过简单地插入一个 ASL 模块,ASL 将被自动纳入前向和后向传播。前向 ASL 的目标是只影响前向传播中的信息传播。图 2(左)描述了这个过程的技术实现。给出编码图像,通过从被攻击的编码图像中减去编码图像,可以得到初始编码图像和被攻击的编码图像之间的差异()。我们把这个差值表示为伪噪声。将这个伪噪声加入到编码图像中,就得到了被攻击的编码图像,然后将其送入解码器网络。在向后传播过程中,梯度流在下半部分被阻断,用两道杠表示。这样,在前向传播中就可以得到被攻击的编码图像,而不需要通过 ASL 模块反向传播梯度。
-
后向 ASL 的定义:编码后的图像直接被送入解码器,但来自解码器的梯度信息在回传到编码器之前流经 ASL。
与前向 ASL 相反,后向 ASL 被设计为只影响后向传播的信息。我们在图 2(中间)中直观地展示了这种情况的技术实现。
在前向传播过程中,编码的图像被送入 ASL,产生被攻击的编码图像。伪噪声的计算方法如前。通过从被攻击的编码图像中减去伪噪声,可以再次得到最初的编码图像,然后将其送入解码器网络。对于纯正向传播,梯度被阻止流经图的下部,在那里计算伪噪声。然而,梯度会流经 ASL,并从那里进一步反向传播到编码器。
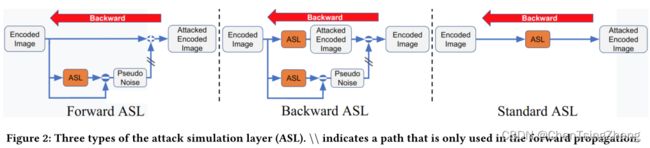
综上所述,通过上述描述,可以区分出 ASL 的三种变化:前向 ASL、后向 ASL 和标准 ASL。通过反切,我们可以研究前向或后向 ASL 对稳健性增益的影响。
-
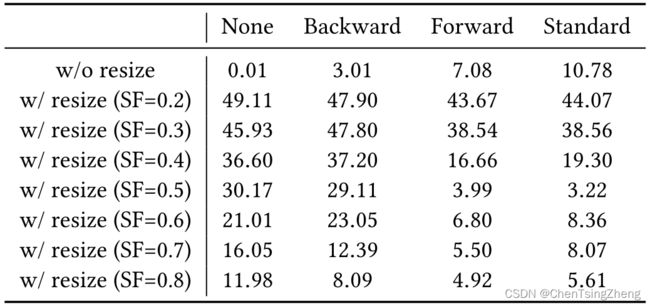
操作要求:为了进行这一分析,所使用的 ASL 模块需要是可分的;否则,后向 ASL 就不能实现。为简单起见,在不失去一般性的情况下,我们选择随机调整大小作为 ASL 模块。图像可以被调整到更大的分辨率或缩小到更小的分辨率。我们让 ASL 包括两个连续的调整大小的操作,首先用一个比例因子(SF)将图像调整到一个较小的分辨率,然后再将其调整到原来的分辨率。具体来说,我们将 SF 设置为 0.5 以训练深度隐藏管道,并评估不同 SF 下管道的鲁棒性。结果显示在表 1 中。我们发现,在调整大小的攻击下,正如预期的那样,标准的 ASL 在不同的 SF 下产生的性能明显好于没有 ASL 的对应物。所采用的 SF 为 0.5 的调整大小攻击是一种强烈的失真,在训练期间不应用 ASL 时,导致误码率为 30.17%。在这样强烈的调整大小攻击下,使用标准 ASL 的误码率低至 3.32%,证明了广泛使用的标准 ASL 方法的有效性。
-
结果:
-
- 进一步的观察表明,Backward-ASL 导致边际鲁棒性的提升,误码率为 29.11%(非常接近 30.17%),而 Forward-ASL 产生的误码率为 3.99%,接近 3.22%。结果表明,有助于提高鲁棒性的主要因素在于前向传播,而不是后向传播。
-
- 当标准 ASL 与前向 ASL 对比时,单独分开应用时,后向 ASL 似乎不影响管道的性能,然而当与前向 ASL 结合的时候,可以将前向 ASL 得到明显提升,BRE 从 3.99%提升到 3.22%.
-
在这里,我们试图找到标准 ASL 和正向 ASL 之间性能差距的可能原因。从本质上讲,在训练过程中,在编码图像后插入标准 ASL 相当于在管道中增加了一个模块,因此预计会对这个特定模块进行过度拟合。另一方面,forwardASL 相当于在训练期间增加了一个伪噪声。
-
猜想:与标准 ASL 相比,它对这个特定模块的过度拟合程度可能较低。
-
结论:为了验证这一点,我们比较了标准 ASL 和 forward ASL 在不同 SF 下的表现。我们发现,当评估期间的 SF 不同于 0.5 时,前向 ASL 取得了比标准 ASL 更好的性能。这些结果支持我们的猜想。总的来说,我们的结论是:(a)当攻击失真度已知且固定时,前向 ASL 可能略逊于标准 ASL,但前向 ASL 仍然是一种有竞争力的方法;(b)当推理期间的攻击失真度发生变化时,前向 ASL 更合适。
相比起单独的前向 ASL,标准 ASL 的一个主要缺点是,它只与可分化的失真兼容。在实践中,有许多类型的非微分(甚至是黑箱)失真,而前向 ASL 无需在后向传播中应用 ASL 就能与它们兼容。受前向 ASL 与标准 ASL 相比具有竞争力的性能的启发,我们建议采用前向 ASL 作为替代解决方案,以提高深层水印管道的鲁棒性,特别是针对不可区分的和/或黑箱失真。前向 ASL 的类似 PyTorch 的伪代码显示在算法 1 中。请注意,这个伪代码构成一个即插即用的模块,可以很容易地插入到现有的深度水印管道中。

Main Results
这章作者主要研究了前向 ASL 与黑盒 Photoshop 效果的兼容性(这个黑盒 Photoshop 我也没搞懂)。同时组合了不同的失真方式,使组合模型同时对各种失真具有鲁棒性。
使用 COCO 数据集中的 10000 张随机图像来训练隐藏管道,并使用 COCO 或 ImageNet 中的单独图像进行测试。
根据 HiDDeN 这篇文章,在 128 × 128 128\times 128 128×128的彩色图像中隐藏 30bit 的随即二进制数据,权重系数 λ E 1 \lambda_{E1} λE1和 λ E 2 \lambda_{E2} λE2分别设置为 0.7 和 0.001。我们采用了 Adam 优化器,学习率设置为 1 e − 4 1e^{-4} 1e−4。我们对模型进行了 200 个 epochs 的训练,批次大小为 32。从经验上看,我们发现对于 photoshop 效应的失真,采用 TSR 的两阶段训练可以稳定训练。与 TSR 相比,在第二阶段保持编码器不变,我们进一步训练编码器,但学习率较小,为 1e-6。请注意,在第二阶段我们仍然保持解码器的学习率 1e-4 不变。对于其他类型的失真,我们通过直接应用前向 ASL,以单阶段的方式直接训练它们。
有损压缩
这项工作的主要重点之一是使深层水印管道对常见的损坏具有鲁棒性。在常见的损坏中,像 JPEG 这样的有损压缩可能是使用最广泛的一种。请注意,由于许多因素,如涉及四舍五入操作的量化,默认的有损压缩总是不可区分的。攻击者可以采用各种技术,如噪音、过滤或压缩,来消除隐藏的数据。一般来说线上社交媒体导致的 JPEG 压缩大部分情况下是无意识的攻击同时人眼很难辨别,但是图像会有很强的失真。因此,解决针对有损压缩的鲁棒性具有很高的实际意义。
例如,当管道在没有相应的前向 ASL 的情况下进行训练时,所调查的有损压缩使鲁棒性从 BER 为 0%恶化到高于 40%,接近 50%(随机猜测)。我们的前向 ASL 方法可以有效地提高管道的稳健性。在指定有损压缩的前向 ASL 下,JPEG、JPEG2000 和 WebP 的误码率分别为 9.27%、1.58%和 2.52%。为了使管道同时对 JPEG、JPEG2000 和 WebP 具有鲁棒性,我们在训练中结合了所有的压缩算法,所得到的组合模型对所有这些算法都显示出合理的鲁棒性。三种有损压缩算法的定性结果可以在图 3 中找到。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qXeSPTO9-1662902285771)(./pic/lossyAttack.PNG)]
作者的工作探索了相对较新的 JPEG-2000 和 WebP 压缩算法。在质量因子设置为 90 的情况下,结果显示在表 2 中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I9Iu0mqC-1662902285771)(./pic/lossyCompression.PNG)]
Photoshop的效果
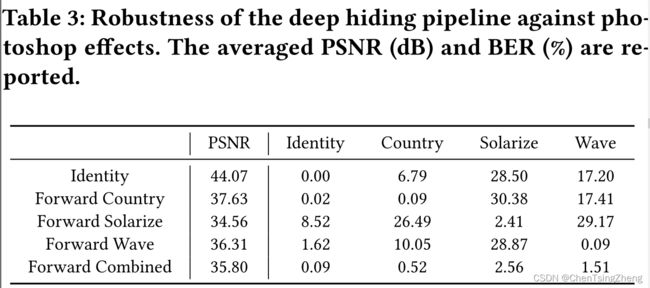
这里作者为了证明前向ASL对黑箱扰动攻击的适用性,用不同的Photoshop效果进行试验。采用了三种不同的PhotoShop效果:
- Country:以类似的方式改变整个图像的颜色;
- Solarize:让暗区显示为亮,亮区显示为暗
- Wave:局部改变像素位置

图是肉眼一见就能看出不同的,但是事实上它这种的失真攻击相比起JPEG肉眼无法辨别的这种攻击而言,对图像的失真更小。在训练期间应用指定的ASL只提高了对相应失真攻击的鲁棒性,而组合模型对所有的失真攻击都是鲁棒的。
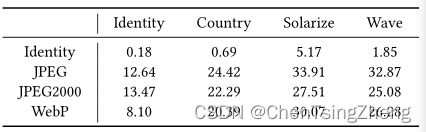
对Photoshop效应和有损压缩的联合研究
作者进一步训练一个综合模型,使其同时对有损压缩和Photoshop效应具有鲁棒性。
在训练期间,随机选择并应用其中一个photoshop扭曲或有损压缩。然而,在推理阶段,一个photoshop效果和一个有损压缩被依次应用于编码的图像。结果显示在表4中。我们观察到,前向ASL的应用导致了一个具有合理鲁棒性的组合模型,以应对photoshop效应和有损压缩的联合失真。例如,在PhotoShop的Country效果和JPEG压缩的联合失真下,该模型的误码率仍为24.42%。
Analysis And Discussion
扩展到其他域
在Hiding images in plain sight: Deep steganography.这一篇文章中,将一个全彩图像隐藏到另一个全彩图像中,作者在这里扩展到使用前向ASL将图像作为隐藏信息隐藏到另一个图像上。
作者扩展到视频以及生成JPEG抗性的对抗性攻击上。
与目前研究相比
作者不是第一个解决鲁棒性数据隐藏中无差别失真的人。现在的尝试可以归纳为2类:1.失真逼近和2.两阶段可分离训练。
JPEG抗性的目标对抗性例子。行中显示的是对抗性例子的质量系数q,而列中显示的是用于评估的q。报告的数值是目标攻击的成功率(越高越好)。每个条目有两个值:左边的表示[27]的性能,右边的表示我们的正向ASL的性能。
失真逼近。以JPEG为例,在HiDDeN这篇文章中,使用跨度为8×8的卷积层来代替DCT变换来模拟JPEG的操作。然后将屏蔽/剔除应用于代表DCT域系数的结果网络激活。这两种近似方法被称为JPEG-Mask和JPEG-Drop。具体来说,JPEG-mask应用固定的屏蔽,只保留低频系数,而JPEG-Drop随机地丢弃一些系数,但以渐进的方式对高效系数有较高的丢弃率。
Photoshop效果总体上对容器图像造成更多的视觉变化,但构成的失真攻击比有损压缩要弱得多。

我们试图从频率的角度来解释这一现象。图8的结果显示,秘密是以高频的形式嵌入的。鉴于有损压缩,如JPEG,被广泛认为倾向于去除高频,这种现象的发生似乎是合理的,因为Photoshop效应主要改变了编码图像上的低频内容。这也可以解释为什么增加对一种有损压缩的鲁棒性也能提高对另一种有损压缩的鲁棒性(见表2)。这种频率观点部分地受到[34]的启发,用于通过深度隐写术的视角解释UAP[23, 33]。
总结
这篇文章主要任务还是从一个新的角度来分析为何ASl可以增强深度学习水印的鲁棒性。分解了现在深度学习信息隐藏常用框架中的ASL(攻击模拟层)。分解后分为前向ASL和后向ASL,实验结果证明主要的影响因素是前向传播而不是后向传播。建议采用前向ASL作为一种简单而有效的方法来改进深层水印管道,使其对不可微分和/或黑箱失真(如有损压缩和Photoshop效应)具有鲁棒性。
第一遍阅读,可能很多地方不是很细致,到时候再补了。