Complementary Feature Enhanced Network withVision Transformer for Image Dehazing_2021
概述:
本文提出了一个用于图像去雾的具有视觉转换器的互补特征增强网络,传统的基于 CNN 的去雾模型存在两个基本问题:去雾框架(可解释性有限)和卷积层(与内容无关,无法有效学习远程依赖信息)。 在本文中,首先,提出了一个新的互补特征增强框架,其中互补特征由几个互补的子任务学习,然后共同提高主要任务的性能。 新框架的突出优势之一是有目的地选择的互补任务可以专注于学习弱依赖的互补特征,避免重复和无效的网络学习。 我们基于这样的框架设计了一个新的去雾网络。
具体来说,本文选择固有图像分解作为补充任务,其中反射和阴影预测子任务用于提取颜色和纹理方面的互补特征。 为了有效地聚合这些互补特征,我们提出了一个互补特征选择模块(CFSM)来选择更有用的图像去雾特征。 此外,我们引入了一个新版本的视觉转换器模块,名为 混合局部-全局视觉转换器(HyLoGViT),并将其整合到我们的去雾网络中。HyLoG-ViT 块由用于捕获本地和全局依赖关系的本地和全局视觉转换器路径组成。 因此,HyLoG-ViT 在网络中引入了局部性,并捕获了全局和远程依赖关系。
模型概述
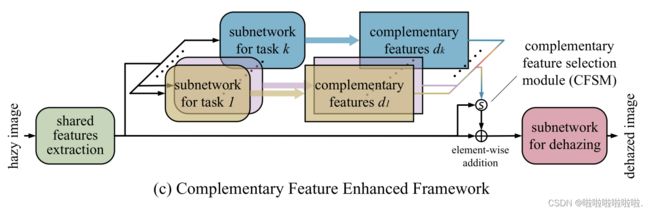
首先介绍了一种新颖的互补特征增强框架,如图 (c)所示。 与以前的框架一次隐式地、低效地学习各种特征的数量不同,新框架背后的核心思想是:不同的互补子任务专注于学习不同的特定特征,即分别与任务相关的互补特征; 然后,这些互补的特征被聚合在一起并服务于主要任务,即去雾。 我们基于这样的框架设计了一个新的去雾网络,其中特定的互补特征由相应的子网络探索,然后在去雾网络中进行协作。
由于观察到颜色和纹理感知是识别对象和理解场景的关键视觉线索,本文选择内在图像分解作为“补充任务”,其中提供从反射预测中学习到的中间特征作为“颜色方面”的互补特征,而“纹理方面”的特征是从阴影预测中学习的。 也就是说,我们的方法从单个图像中联合学习内在图像分解和去雾。 请注意,直接聚合冗余的互补特征效率低下,因为互补子网络可能会输出一些与雾度无关的特征。 因此,进一步提出了一个互补特征选择模块(CFSM)来自动选择有助于去雾任务的“正确”特征并削弱不相关的特征。
混合局部 - 全局视觉转换器(HyLoG-ViT)
最近,视觉转换器因其内容相关的交互和建模远程依赖的灵活性而被称为CNN的替代品,用于学习视觉表示。 然而,复杂度随图像大小的二次增加阻碍了其在高分辨率特征映射的去雾任务中的应用。 此外,不可否认,全局和局部信息聚合对于低级视觉任务很有用,而视觉转换器不具备局部性。
因此,本文提出了一种混合局部全局视觉转换器(HyLoG-ViT),它由局部和全局视觉转换器路径组成。 在局部视觉转换器路径中,标准转换器块在非重叠区域的网格中运行,使模型能够捕获局部区域内的细粒度和短距离信息。 在全局视觉变换器路径中,一个变换器块在缩小的特征图上运行,以捕获全局和远程依赖关系。 然后,来自两条路径的特征通过卷积层进行混合,以提高局部连续性。 与普通视觉转换器架构相比,HyLoGViT 具有较低的计算复杂度,并为网络带来了局部性机制。
主要贡献
- 提出了一个新的框架,并通过共同学习内在图像分解和图像除雾,为图像除雾建立了互补的特征增强网络。反射和阴影预测任务为除雾任务提供了丰富的互补功能,使网络能够生成具有自然色彩和精细细节的高质量无雾图像。
- 为了有效地融合互补特征,我们提出了一个互补特征选择模块(CFSM)。CFSM 通过自适应地增强适当的互补特征通道同时削弱不相关的通道,大大提高了特征聚合的有效性。
- 提出了一种新的视觉变换器变体,即混合局部-全局视觉变换器(HyLoG-ViT),它可以以比普通视觉变换器更低的计算成本对局部和全局依赖项进行建模。 借助 HyLoG-ViT,我们首次提出了基于转换器的去雾网络。
模型介绍
本文提出的去雾结构与之前的去雾框架不同,我们的方法既不依赖于大气散射模型,也不依赖于完全黑盒系统。 内在图像分解的子网络提供颜色和纹理方面的互补特征,使去雾子网络能够产生具有自然色彩和精细细节的无雾图像。 同时,在不同的数据集上进行训练,我们的网络在同质、非同质和夜间去雾任务上表现出良好的泛化性能,而网络架构没有任何变化。

在我们的去雾模型中,内在图像分解和去雾被认为是一个联合模型,通过探索前者所需的互补特征。 具体来说,我们的网络是一个多任务学习模型,具有以解码器为中心的架构 。
本文的去雾网络概述由一个共享的编码器和三个解码器组成,如上图所示。 表示模糊图像为 IH,共享编码器 E 用于提取浅层和深层特征:

其中![]() 表示用于提取浅层特征 e0 的特征提取层;
表示用于提取浅层特征 e0 的特征提取层;![]() 表示编码器 E 的第 z 阶段,ez 指第 z 阶段的深度特征。 z ∈ [1, · · · , Z],Z 为总阶段数。 三个并行解码器跟随编码器。 解码器 DR 和 DS 分别用于预测无雾图像的反射率和阴影,它们的中间特征作为解码器 DD 的补充特征,以生成高质量的无雾图像。 解码器描述为:
表示编码器 E 的第 z 阶段,ez 指第 z 阶段的深度特征。 z ∈ [1, · · · , Z],Z 为总阶段数。 三个并行解码器跟随编码器。 解码器 DR 和 DS 分别用于预测无雾图像的反射率和阴影,它们的中间特征作为解码器 DD 的补充特征,以生成高质量的无雾图像。 解码器描述为:

其中![]() 、
、![]() 和
和![]() 分别表示解码器DR、DS和DD的第z级,z∈[1,···,Z]。
分别表示解码器DR、DS和DD的第z级,z∈[1,···,Z]。 ![]() 、
、![]() 和
和![]() 分别是解码器 DR、DS 和 DD 在阶段 z 的中间特征。 最终的反射 IR、着色 IS 和无雾图像 ID 分别通过
分别是解码器 DR、DS 和 DD 在阶段 z 的中间特征。 最终的反射 IR、着色 IS 和无雾图像 ID 分别通过![]() 、
、 和
和 ![]() 三个图像重建层生成:
三个图像重建层生成:

清晰的反射和阴影样本
结论:因为反射分量包含场景的实际颜色,而阴影分量包含结构和纹理信息
证明:我们分析了均匀、非均匀和夜间雾霾数据集上朦胧和清晰图像的反射和阴影特征。
清晰反射ICR (清晰反射)保持清晰图像IC 的颜色信息,具有非常低的ΔE 和CIEDE2000值
将可见梯度图可视化,表明着色 ICS(清晰阴影) 保留了丰富的边缘和纹理信息
本文选择用于内在图像分解的无监督学习 (USI3D)方法在我们的训练数据集中生成清晰的反射和阴影样本最重要的是,USI3D 假设反射阴影独立,与上述互补特征的第二个标准一致。 我们模型中的反射偏向子网络可以专注于颜色互补特征学习,避免阴影分量的干扰;
编码器和解码器的详细信息
编码器 E 包括一个特征提取层和一系列 HyLoGViT 块, 提取层由 5 × 5 卷积和基本 ResNet 块 构建,以提取浅层特征。 在解码器 DR 和 DS 中,除了底层 Z 之外,来自前一个解码器块的特征 ![]() 首先通过 4×4 反卷积放大,以步长为 2 的空间分辨率并将通道数减半。 然后,将输出与来自编码器E的同一阶段的特征ez连接起来。
首先通过 4×4 反卷积放大,以步长为 2 的空间分辨率并将通道数减半。 然后,将输出与来自编码器E的同一阶段的特征ez连接起来。
与解码器 DR 和 DS 不同,DD 中的第 z 阶段有三个输入:前一阶段的特征![]() ; 分别来自
; 分别来自 ![]() 和
和![]() 同一阶段的互补特征
同一阶段的互补特征![]() 和
和![]() 。这些输入特征被馈送到互补特征选择模块,以动态地从
。这些输入特征被馈送到互补特征选择模块,以动态地从 ![]() 和
和 ![]() 中选择最有用的通道。
中选择最有用的通道。
补充特征选择模块 (CFSM)
CFSM 以非线性方式融合互补特征。 CFSM 的架构如图所示

主要过程是给定互补特征![]() 和
和![]() 以及特征
以及特征![]() ,它们首先通过元素求和组合。 然后,分别通过全局平均池和全局最大池将输出转换为两个通道统计数据
,它们首先通过元素求和组合。 然后,分别通过全局平均池和全局最大池将输出转换为两个通道统计数据![]() 和
和 ![]()
![]() 。 每个统计量分为两个流:一个流用于
。 每个统计量分为两个流:一个流用于![]() 特征选择,另一个流用于
特征选择,另一个流用于![]() 。以
。以![]() 流为例,
流为例,![]() 和
和![]() 之后是通道缩减1×1 卷积层来计算紧凑的特征向量,
之后是通道缩减1×1 卷积层来计算紧凑的特征向量,![]() 和
和![]() (∈
(∈![]() ,其中 r = 4 在我们的模型中)。 特征向量被送入两个并行的通道放大 1×1 卷积层,并提供特征描述符
,其中 r = 4 在我们的模型中)。 特征向量被送入两个并行的通道放大 1×1 卷积层,并提供特征描述符 ![]() 和
和![]()
![]() 。 最终的特征描述符定义为
。 最终的特征描述符定义为![]() 。
。![]() 通过 Sigmoid 函数生成
通过 Sigmoid 函数生成 ![]() 的注意力分数
的注意力分数![]() 。类似地,我们可以得到
。类似地,我们可以得到![]() 的注意力分数
的注意力分数 ![]() . 特征重新校准和聚合的整体过程定义为:
. 特征重新校准和聚合的整体过程定义为:
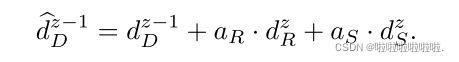
混合局部-全局视觉转换器介绍(HyLoG-ViT)

如图所示,HyLoG-ViT块由两条路径组成。在局部视觉转换器路径中,输入特征图被分组为非重叠区域的网格,并且转换器块仅在每个区域内应用。给定特征图![]() ,其中H,W和C是图的高度,宽度和信道数,则局部视觉变压器路径的计算可以表示为:
,其中H,W和C是图的高度,宽度和信道数,则局部视觉变压器路径的计算可以表示为:

其中 Xg 是全局视觉转换器路径的输出。![]() 是平均池化率 Ng的平均池化;
是平均池化率 Ng的平均池化; ![]() 表示以放大率 Ng 进行的上采样操作。 全局视觉转换器路径提高了效率,同时仍保持聚合全局信息的能力。 两条路径的混合输出通过 3 × 3 卷积层连接并转换为原始维度:
表示以放大率 Ng 进行的上采样操作。 全局视觉转换器路径提高了效率,同时仍保持聚合全局信息的能力。 两条路径的混合输出通过 3 × 3 卷积层连接并转换为原始维度:
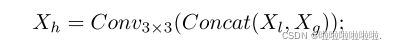
其中 Xh 是 HyLoG-ViT 块的最终输出; Concat(·) 是通道级连接;Conv3×3(·) 是一个 3×3 的卷积层。 这种融合操作保持了局部和全局视觉转换器的优点,并将局部性引入网络。
位置编码:转换器中使用的位置编码旨在保留位置信息。 然而,对于低级视觉任务,不同大小的输入图像通常与训练图像不同。 因此,它可能会降低性能并破坏平移不变性。 请注意,即使没有额外的位置编码模块,我们的模型也能取得良好的效果。 我们认为上述公式中使用的 3×3 卷积足以为 Transformer 提供位置信息。
复杂性分析: 对于局部视觉转换器路径,表示输入特征![]() 分为Nl × Nl区域,每个区域的空间分辨率为
分为Nl × Nl区域,每个区域的空间分辨率为![]() 。然后,局部视觉转换器路径中的自注意力复杂度从 O((HW)2C) 降低到
。然后,局部视觉转换器路径中的自注意力复杂度从 O((HW)2C) 降低到![]() 与标准的自我注意相比。对于全局视觉变压器路径,表示输入特征的空间维度被缩小比Ng缩小,复杂度为
与标准的自我注意相比。对于全局视觉变压器路径,表示输入特征的空间维度被缩小比Ng缩小,复杂度为![]() ,因此,HyLoG ViT块的总自我注意计算复杂度为
,因此,HyLoG ViT块的总自我注意计算复杂度为![]()
损失函数
在本文的训练过程中,反射图![]() 和阴影图
和阴影图![]() 的清晰图像是通过在清晰图像IC的ground truths上操作预先训练的固有图像分解模型USI3D生成的。对于反射和无雾图像估计,我们使用L2重建损失、条件对抗损失和SSIM损失,对网络进行训练。对于阴影估计,我们使用L2重建损失和边缘保留损失,其定义为:
的清晰图像是通过在清晰图像IC的ground truths上操作预先训练的固有图像分解模型USI3D生成的。对于反射和无雾图像估计,我们使用L2重建损失、条件对抗损失和SSIM损失,对网络进行训练。对于阴影估计,我们使用L2重建损失和边缘保留损失,其定义为:

其中 E 是对一批样本的平均操作;![]() 和
和 ![]() 分别是 x 和 y 方向的空间导数。 p 指的是空间位置。总的来说,混合损失函数包含三个部分,即:
分别是 x 和 y 方向的空间导数。 p 指的是空间位置。总的来说,混合损失函数包含三个部分,即:

其中LR,LS和LD分别是三个视觉任务的损失函数。
数据集
室外数据集:RESIDE 数据集、NH-HAZE 数据集和 NHR 数据集 ,分别用于均匀雾霾、非均匀雾霾和夜间雾霾去除。
对于 RESIDE 数据集,我们从 OTS(RESIDE 中的户外训练子集)中随机选择 41240 个样本进行训练,从 SOTS (RESIDE 中的综合客观测试子集)中随机选择 500 个样本进行测试。对于 NH-HAZE 数据集,我们通过随机裁剪、翻转和旋转从 50 个原始高分辨率样本中合成了 9800 个样本;第 41∼45 个样本用于定性评估。 NHR 数据集包含 17900 个样本;我们选择最后的 475 个进行测试,其他的进行训练。
训练过程
我们的模型在 RESIDE 数据集上训练了 32 个 epoch,在 NH-HAZE 数据集上训练了 20 个 epoch,在 NHR 数据集上训练了 5 个 epoch,采用 Adam 优化器进行优化。
实验结果
在 RESIDE、O-HAZE、HAZERD 和真实世界数据集上的同质图像去雾结果。

NH-HAZE数据集上的非均质去雾结果。

NHR和现实世界数据集的夜间除雾结果。
