计算机视觉之风格迁移(一)——CVPR2016论文Image Style Transfer复现
一、风格迁移简介
风格迁移可以说是计算机视觉领域一大热点,简单来说就是有两副图片,一张内容图片 ,一张风格图片,该技术可以实现以风格图片的风格+内容图片的内容重新生成一张目标图片,例如:
| 内容图片 | 风格图片 | 目标图片 |
 |
 |
 |
说到风格迁移,不得不提到该领域的经典论文:
【CVPR-2016】Image Style Transfer Using Convolutional Neural Networks
有很多小伙伴已经对论文进行过解析,本文就简单介绍一下该论文,主要聚焦在论文的代码复现上。
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
二、论文简介
1.定睛之处
该论文之所以能够成功登上顶会,并且受到广大计算机视觉爱好者的推崇,最关键的一点就是——它证实了卷积神经网络可以将图像的内容和风格分离出来!!
如果说内容我们还可以勉强理解的话,那对于风格这个词就有点天方夜谭了。在现实中,我们可以说这个作家是抽象派,那个作家是抽象派,可以通过对画家作品的印象、直观感受进行区分。然而对于计算机而言,将画家的风格剥离出来貌似令人难以置信,该论文作者提出我们可以独立的操纵内容和风格来产生新的图像。
2.内容表示
该网络使用VGG19对图像进行特征提取,网络中的每一层都定义了一个非线性滤波器组(卷积),其复杂性随着该层在网络中的位置而增加,给定输入图像,每一层都会对其进行编码。
例如,在某l层有Nl个滤波器,则会产生Nl个大小为Ml的特征图,Ml为特征图的高×宽,所以在l层的响应可以存储在矩阵![]()
当网络的处理层次逐渐加深时,网络中的较高层根据输入图像的排列来捕捉高级内容,但并不太注重精确像素值。相比之下,较低层的重建只是简单地再现原始图像的精确像素值,对于内容并不敏感。因此,我们将网络较高层中的特征响应称为内容表示。
低层的内容输出和高层的内容输出如下:
| content_relu1_2 | content_relu2_2 | content_relu3_2 | content_rel4_2 | content_relu5_2 |
 |
 |
 |
 |
 |
3.风格表示
为了获得输入图像风格的表示,作者使用了一个特征空间用于捕捉纹理信息。
这个特征空间可以建立在网络的任何层的滤波器上,它由不同滤波器的组合而成,组合规则如G:![]()
 ,其中Fik为l层第i个特征图中的第k个权重。
,其中Fik为l层第i个特征图中的第k个权重。
(简单来说,就是每一层特征图组合起来生成了纹理信息;内容表示是直接使用某一层特征图,风格表示是对多层特征图进行运算组合)
通过包含多个层的特征相关性,我们获得了输入图像的稳定的、多尺度的表示,该表示捕获其纹理信息,但不捕获全局排列。
4.整体结构
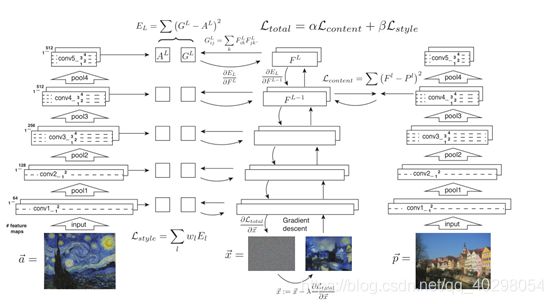
左边为风格图片,采用的loss值为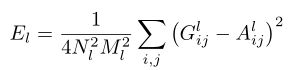
 ,wl为每一层的权重,每一层均输出特征图构成风格。
,wl为每一层的权重,每一层均输出特征图构成风格。
(其中,Gij为风格图片的风格表示,Aij为目标图片的风格表示,利用公式进行计算,N为l层特征图个数,M为每个特征图大小)
右边为内容图片,采用的loss值为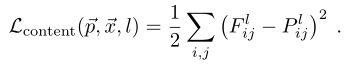 ,仅在倒数第二层输出特征图用于内容表示。
,仅在倒数第二层输出特征图用于内容表示。
(其中Fij为内容图片的特征图,Pij为目标图片的特征图,下标意义同上)
总的loss值为: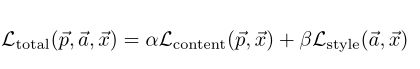
(其中α、β为偏向内容还是偏向风格的参数)
这里只是对论文中的关键地方进行了简单说明,更详细的阐述请在网上自行搜索。
三、代码复现
0.复现环境
scipy==1.2.1
tensorflow_gpu==1.8.0
numpy==1.19.2
使用tensorflow1是因为论文中提到,图片优化采用BFGS方法,在tensorflow2中我不知道如何实现。
在tensorflow2中我使用Adam进行优化,发现效果很差,所以果断选择tensorflow1。
1.VGG网络
def Network_vgg(inputs):
vgg_para = scipy.io.loadmat("vgg19/vgg.mat")
layers = vgg_para["layers"]
feature_bank = {}
with tf.variable_scope("vgg"):
for i in range(len(layers_name)):
if layers[0, i][0, 0]["type"] == "conv":
w = layers[0, i][0, 0]["weights"][0, 0]
b = layers[0, i][0, 0]["weights"][0, 1]
with tf.variable_scope(str(i)):
inputs = conv(inputs, w, b)
elif layers[0, i][0, 0]["type"] == "relu":
inputs = tf.nn.relu(inputs)
feature_bank[layers[0, i][0, 0]["name"][0]] = inputs
else:
inputs = tf.nn.max_pool(inputs, [1, 2, 2, 1], [1, 2, 2, 1], "SAME")
return feature_bank该网络为VGG19,从vgg.mat中读取参数,其中
vgg_para["layers"]——每一层的信息
layers[0, i][0, 0]["weights"][0, 0]——该层的权重
layers[0, i][0, 0]["weights"][0, 1]——该层的偏置
对于.mat格式的具体结构,请见https://zhuanlan.zhihu.com/p/28897952,虽然与该代码略有差异,但是讲的比较清楚。
该文件已经上传CSDN,免费下载,下载完成后将该文件放在vgg19文件夹下,详细地址请见:https://download.csdn.net/download/qq_40298054/13082438
2.关键代码
所有代码均已经上传到github上(地址请看文末),在此仅对关键部分的代码进行说明,如果代码中存在问题或者读者对于代码存在疑问,请私信我。
self.content_layers = ['relu4_2']
self.style_layers = ['relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1']↑ 对于内容特征,仅在高层的某一层中进行提取;对于风格特征,则在每一层中进行提取;该代码即为在哪一层中进行提取。
self.content_img = tf.placeholder("float", [1, H, W, C])
self.style_img = tf.placeholder("float", [1, H, W, C])
self.target_img = tf.get_variable("target", shape=[1, H, W, C],
initializer=tf.truncated_normal_initializer(stddev=0.02))
target_feature = Network_vgg(self.target_img)
content_feature = Network_vgg(self.content_img)↑ 对目标图片、内容图片、风格图片进行特征提取,其中初始目标图片为随机生成的白噪声。
def content_loss(self, target_feature, content_feature):
return tf.nn.l2_loss(target_feature["relu4_2"] - content_feature["relu4_2"])↑ 内容层的loss值计算
def style_loss(self, target_feature, style_feature):
E = 0
for layer in style_feature.keys():
if layer in self.style_layers:
w = 0.2
else:
w = 0
H = int(target_feature[layer].shape[1])
W = int(target_feature[layer].shape[2])
# Gram matrix of x
C = int(target_feature[layer].shape[-1])
F = tf.reshape(tf.transpose(target_feature[layer], [0, 3, 1, 2]), shape=[C, -1])
G_x = tf.matmul(F, tf.transpose(F))
# Gram matrix of style
C = int(style_feature[layer].shape[-1])
F = tf.reshape(tf.transpose(style_feature[layer], [0, 3, 1, 2]), shape=[C, -1])
G_s = tf.matmul(F, tf.transpose(F))
E += w * tf.reduce_sum(tf.square(G_x - G_s)) / (4 * C**2 * H**2 * W**2)
return E↑ E为风格loss值的计算,为每一层的累加。w为每一层的权重,选定层为0.2,其它层为0。G_x和G_s分别为特征图片和风格图片的G矩阵,该矩阵代表了图片排列纹理等信息——即风格。
3.复现结果
| 内容图像 |
风格图像 |
目标图像 |
|
|
|
|
|
|
|
|






目标图像未保持原图像大小,论文中按照原图像大小进行输出,读者可自行修改(上述结果为训练1000轮得出)。
图片处理过程中,选取的像素大小为512×512,可根据个人计算机性能进行修改。
由于内容和风格分离然后进行组合,所以两者之间必然存在一个偏重问题,由α和β进行控制,我用代码分别对不同的α/β值进行测试,结果如下:
| 内容图片 | 风格图片 |
|
|
|
| α/β=10e-4 | α/β=10e-3 |
|
|
|
| α/β=10e-2 | α/β=10e-1 |
|
|
|






由实验结果可以看出,α/β值的提高说明对于内容越来越偏重而对于风格越来越忽略(上述结果为训练2000轮得出)。
论文中提到,对于目标图像的初始值,无论是用随机的白噪声,还是内容图片作为初始,结果都会收敛到相似图像。但是在实验中我发现,在迭代1000次的基础下,采用内容图片作为初始效果比白噪声要好,很可能是因为迭代次数较少的原因,结果如下:
| 内容图片作为初始目标图片(迭代1000) | 白噪声作为初始目标图片(迭代1000) | 白噪声作为初始目标图片(迭代2000) |
|
|
|
 |


4.总结
这篇论文是2016年的,4年过去了技术必定已经发展了起来,由于本人也是因为兴趣原因,这两天才开始看这部分内容,代码必然也参考了其他朋友的复现,然后在其中做了一些修改。这部分代码数量比较少,逻辑比较简单,很多细节部分没有进行处理,所以对于有些图像的迁移实现的并不是那么完美,我还尝试使用人的照片进行风格迁移,发现效果有些差强人意。
接下来我准备首先在这个代码的基础上,在学习一些优化的方法,对于这个代码进行优化。这部分内容结束后,准备接下来继续看大佬论文的优化和实现方法,如果发现了更好的方法(当然必然存在更好的方法)我会继续研究复现,并把结果发在这里。
如果也有进行这方面研究的朋友或者感兴趣的朋友,可以联系我大家集思广益一起去阅读论文进行复现,在调试过程中遇到问题可以一起讨论(问题十分之多,自己独木难支),毕竟在深度学习这方面我也算是个新手,目前在读研期间,有共同爱好者请务必联系!!!
github地址:https://github.com/Lonely79/Style_Transfer_1.git