第4关: 网页排序——PageRank算法
要求:编写实现网页数据集PageRank算法的程序,对网页数据集进行处理得到网页权重排序。 ####相关知识 ######PageRank算法原理 1.基本思想: 如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/L(T) 其中PR(T)为T的PageRank值,L(T)为T的出链数。则A的PageRank值为一系列类似于T的页面重要性得分值的累加。
即一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。

2.PageRank简单计算: 假设一个由只有4个页面组成的集合:A,B,C和D。如图所示,如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

![]()
继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
![]()
换句话说,根据链出总数平分一个页面的PR值。
![]()
完整PageRank计算公式
由于存在一些出链为0不链接任何其他网页的网页,因此需要对 PageRank公式进行修正,即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85
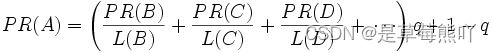
更加准确的表达为:

P1,P2,...,Pn是被研究的页面,M(Pi)是Pi链入页面的数量,L(Pj)是Pj链出页面的数量,而N是所有页面的数量。PageRank值是一个特殊矩阵中的特征向量。这个特征向量为:

R是如下等式的一个解:
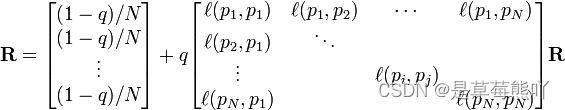
如果网页i有指向网页j的一个链接,则

否则![]() =0.
=0.
PageRank计算过程
PageRank 公式可以转换为求解![]()
的值, 其中矩阵为 A = q × P + ( 1 一 q) * 。 P 为概率转移矩阵,为 n 维的全 1 行. 则=
幂法计算过程如下: X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1。R = AX。
while (1){ if ( |X - R| < e) return R; //如果最后两次的结果近似或者相同,返回R else { X =R; R = AX; } }
MapReduce计算PageRank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决
对于如下图所示的相互链接网页关系
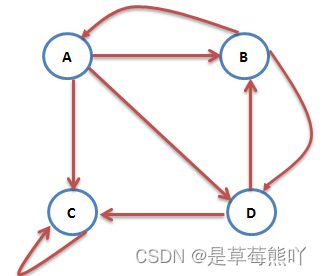
可以利用转移矩阵进行表示。转移矩阵是一个多维的稀疏矩阵,把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:
1. A B C D 2. B A D 3. C C 4. D B C
可以看A有三条出链,分布指向A、B、C,实际上爬取的网页结构数据就是这样的。 1.Map阶段 Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出

这样进行一次迭代相当于需要两次MapReduce,但第一次的MapReduce只是简单的排序,不需要任何操作,用java调用Hadoop的Streaming. ####编程要求 本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
- 在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
- 在main函数中,已经设置好了待处理文档路径(即input),在评测中设置了结果输出路径(即output),不要修改循环输出路径即可保证完成。
- 在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
- 原则上循环迭代次数越多越精准,但是为了保证平台资源,只允许运行5次迭代,多余过程被忽略无法展示,请勿增加循环次数。
- 本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
import java.io.IOException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PageRank {
public static class MyMapper extends Mapper
{
private Text id = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException
{
String line = value.toString();
//判断是否为输入文件
if(line.substring(0,1).matches("[0-9]{1}"))
{
boolean flag = false;
if(line.contains("_"))
{
line = line.replace("_","");
flag = true;
}
//对输入文件进行处理
String[] values = line.split("\t");
Text t = new Text(values[0]);
String[] vals = values[1].split(" ");
String url="_";//保存url,用作下次计算
double pr = 0;
int i = 0;
int num = 0;
if(flag)
{
i=2;
pr=Double.valueOf(vals[1]);
num=vals.length-2;
}
else
{
i=1;
pr=Double.valueOf(vals[0]);
num=vals.length-1;
}
for(;i
{
private Text result = new Text();
private Double pr = new Double(0);
public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException
{
double sum=0;
String url="";
//****请通过url判断否则是外链pr,作计算前预处理****//
/*********begin*********/
for(Text val:values)
{
//发现_标记则表明是url,否则是外链pr,要参与计算
if(!val.toString().contains("_"))
{
sum=sum+Double.valueOf(val.toString());
}
else
{
url=val.toString();
}
}
pr=0.15+0.85*sum;
String str=String.format("%.3f",pr);
result.set(new Text(str+" "+url));
context.write(key,result);
/*********end**********/
//****请补全用完整PageRank计算公式计算输出过程,q取0.85****//
/*********begin*********/
/*********end**********/
}
}
public static void main(String[] args) throws Exception
{
String paths="file:///tmp/input/Wiki0";//输入文件路径,不要改动
String path1=paths;
String path2="";
for(int i=1;i<=5;i++)//迭代5次
{
System.out.println("This is the "+i+"th job!");
System.out.println("path1:"+path1);
System.out.println("path2:"+path2);
Configuration conf = new Configuration();
Job job = new Job(conf, "PageRank");
path2=paths+i;
job.setJarByClass(PageRank.class);
job.setMapperClass(MyMapper.class);
//****请为job设置Combiner类****//
/*********begin*********/
job.setCombinerClass(MyReducer.class);
/*********end**********/
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileOutputFormat.setOutputPath(job, new Path(path2));
path1=path2;
job.waitForCompletion(true);
System.out.println(i+"th end!");
}
}
}