文献‘‘Generative Adversarial Nets‘‘总结
目录
1、摘要
2、Adversarial Nets
3、理论结果
3.1全局最优性
3.2算法1的收敛性
4、实验
5、实验结果
6、代码结果
1、摘要
本文提出了一个通过对抗性过程来估计生成模型的新框架, 在这个框架中, 同时训练两个模型:生成模型G捕捉数据分布, 判别模型D估计样本来自训练数据而不是来自G的概率. G的训练过程是最大化D出错的概率. 这个框架对应于一个极大极小的双人博弈. 最优的情况是, G恢复训练数据的分布, D处处为0.5. 在G和D由多层感知器定义的情况下, 可以用反向传播训练整个系统.
2、Adversarial Nets
为了学习数据点 的生成分布
的生成分布 , 本文定义了输入噪声变量
, 本文定义了输入噪声变量![]() 的先验, 然后将到数据空间的映射表示为
的先验, 然后将到数据空间的映射表示为![]() , 其中
, 其中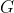 是由参数
是由参数 组成的多层感知器表示的可微函数.本文还定义了第二个输出单个标量的多层感知器
组成的多层感知器表示的可微函数.本文还定义了第二个输出单个标量的多层感知器![]() .
.  表示来自数据而不是的概率. 训练
表示来自数据而不是的概率. 训练 使训练样本和生成的样本标签分配正确的概率最大, 同时训练使
使训练样本和生成的样本标签分配正确的概率最大, 同时训练使![]() 最小. 换句话说, 和用值函数
最小. 换句话说, 和用值函数![]() 进行以下二人极小极大博弈:
进行以下二人极小极大博弈:
![]()

3、理论结果
生成器隐式定义一个概率分布为当![]() 时得到的样本
时得到的样本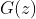 的分布. 因此, 如果给定足够的能力和训练时间, 希望算法1收敛到一个好的
的分布. 因此, 如果给定足够的能力和训练时间, 希望算法1收敛到一个好的![]() 估计.
估计.
将在3.1节中展示这个极小极大游戏对于![]() 有一个全局最优值. 然后在3.2节中说明, 算法1优化了
有一个全局最优值. 然后在3.2节中说明, 算法1优化了![]() , 从而得到了预期的结果. 以下是算法1的流程:
, 从而得到了预期的结果. 以下是算法1的流程:

3.1全局最优性
首先考虑任意给定生成器G的最优鉴别器D:
命题1. 当G固定时, 最优鉴别器D为
![]()
证明略.
D的训练目标可以解释为最大化估计条件概率![]() 的对数似然, 其中
的对数似然, 其中 表示是来自
表示是来自![]() (y =1)还是来自(y =0).
(y =1)还是来自(y =0). ![]() 中的极小极大博弈现在可以重新表述为:
中的极小极大博弈现在可以重新表述为:
![]()
![]()
![]()

定理1. 当且仅当![]() 时, 得到虚拟训练标准
时, 得到虚拟训练标准![]() 的全局最小值. 此时
的全局最小值. 此时![]() 达到值
达到值
![]() .
.
证明略.
3.2算法1的收敛性
命题2. 如果和有足够的容量, 并且在算法1的每一步, 在给定的情况下, 允许鉴别器达到 其最优值, 并更新以优化
![]()
然后收敛到![]() .
.
证明略.
4、实验
本文训练对抗网的一系列数据集, 包括MNIST、多伦多面部数据库(TFD)和CIFAR-10. 生成网络混合使用rectifier linear激活和sigmoid激活, 而鉴别网络使用maxout激活. 同时将Dropout应用于鉴别网络的训练.以下是GAN算法流程.
GAN算法流程:
首先初始化![]() 和
和![]() 的参数.
的参数.
在每次迭代中:
1、从数据集 中采样
中采样 个样本点
个样本点![]() . (注意这个是一个超参数, 需要自 己去调)
. (注意这个是一个超参数, 需要自 己去调)
2、从一个任意分布中采样m个向量![]() .
.
3、将第2步中的 作为输入放到
作为输入放到![]() 里面, 获得个生成的数据
里面, 获得个生成的数据 ![]() .
.
4、更新![]() 的参数, 最大化:
的参数, 最大化:
![]()
5、从上述分布中采样出m个向量![]() . (这些不用和步骤2中的一致)
. (这些不用和步骤2中的一致)
6、更新![]() 的参数, 最小化
的参数, 最小化
![]()
5、实验结果
四种模型在两种数据集上的对比:

以下是本文模型生成的样本:

6、代码结果
该代码(附在文章最下方)是一个通俗易懂的GAN用于MNIST数据集的例子(非原文献代码).
部分损失结果:

生成的图(训练次数较少):

以下代码主要来自廖星宇的《深度学习之PyTorch》:
import torch
from torch import nn
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import numpy as np
import matplotlib.pyplot as plt
def preprocess_img(x):
x = tfs.ToTensor()(x) # x (0., 1.)
return (x - 0.5) / 0.5 # x (-1., 1.)
def deprocess_img(x): # x (-1., 1.)
return (x + 1.0) / 2.0 # x (0., 1.)
def discriminator():
net = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
)
return net
def generator(noise_dim):
net = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(True),
nn.Linear(1024, 1024),
nn.ReLU(True),
nn.Linear(1024, 784),
nn.Tanh(),
)
return net
def discriminator_loss(logits_real, logits_fake): # 判别器的loss
size = logits_real.shape[0]
true_labels = torch.ones(size, 1).float()
false_labels = torch.zeros(size, 1).float()
bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(logits_real, true_labels) + bce_loss(logits_fake, false_labels)
return loss
def generator_loss(logits_fake): # 生成器的 loss
size = logits_fake.shape[0]
true_labels = torch.ones(size, 1).float()
bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(logits_fake, true_labels) # 假图与真图的误差。训练的目的是减小误差,即让假图接近真图。
return loss
# 使用 adam 来进行训练,beta1 是 0.5, beta2 是 0.999
def get_optimizer(net, LearningRate):
optimizer = torch.optim.Adam(net.parameters(), lr=LearningRate, betas=(0.5, 0.999))
return optimizer
def train_a_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss,
noise_size, num_epochs, num_img):
f, a = plt.subplots(num_img, num_img, figsize=(num_img, num_img))
plt.ion() # 打开互动模式,持续绘制
for epoch in range(num_epochs):
for iteration, (x, _) in enumerate(train_data):
bs = x.shape[0]
# 训练判别网络
real_data = x.view(bs, -1) # 真实数据
logits_real = D_net(real_data) # 判别网络得分
rand_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
fake_images = G_net(rand_noise) # 生成的假的数据
logits_fake = D_net(fake_images) # 判别网络得分
d_total_error = discriminator_loss(logits_real, logits_fake) # 判别器的 loss
D_optimizer.zero_grad()
d_total_error.backward()
D_optimizer.step() # 优化判别网络
# 训练生成网络
rand_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
fake_images = G_net(rand_noise) # 生成的假的数据
gen_logits_fake = D_net(fake_images)
g_error = generator_loss(gen_logits_fake) # 生成网络的 loss
G_optimizer.zero_grad()
g_error.backward()
G_optimizer.step() # 优化生成网络
if iteration % 20 == 0:
print('Epoch: {:2d} | Iter: {:<4d} | D: {:.4f} | G:{:.4f}'.format(epoch,
iteration,
d_total_error.data.numpy(),
g_error.data.numpy()))
imgs_numpy = deprocess_img(fake_images.data.cpu().numpy())
for i in range(num_img ** 2):
a[i // num_img][i % num_img].imshow(np.reshape(imgs_numpy[i], (28, 28)), cmap='gray')
a[i // num_img][i % num_img].set_xticks(())
a[i // num_img][i % num_img].set_yticks(())
plt.suptitle('epoch: {} iteration: {}'.format(epoch, iteration))
plt.pause(0.01)
plt.ioff()
plt.show()
if __name__ == '__main__':
EPOCH = 10
BATCH_SIZE = 128
LR = 5e-4
NOISE_DIM = 96
NUM_IMAGE = 4 # 用于在训练时显示图像
train_set = MNIST(root='/mnist',
train=True,
download=True,
transform=preprocess_img)
train_data = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
D = discriminator()
G = generator(NOISE_DIM)
D_optim = get_optimizer(D, LR)
G_optim = get_optimizer(G, LR)
train_a_gan(D, G, D_optim, G_optim, discriminator_loss, generator_loss, NOISE_DIM, EPOCH, NUM_IMAGE)