VggNet网络结构及代码复现
1. VGGNet网络论文详解
1. Abstract:
本文的主要贡献:使用非常小的(3*3)卷积核(感受野思想)的架构来增加网络的深度,从而提高图形识别的准确性。并在ImageNet Challenge 2014 中的Localization Task获得第一名,Classification Task获得第二名。
2. ConvNet 配置:
网络层结构的设计灵感来源于Flexible, high performance convolutional neural networks for image classification和ImageNet classification with deep convolutional neural networks这两篇paper。
2.1 结构:
唯一的预处理:从每一个像素点减去在训练集上计算的平均RGB值。
卷积层:
- Kernel Size:(3, 3)
- Stride:1
- Padding:Same Padding
池化层:
- Kernel Size:(2, 2)
- Stride:2
3个全连接层:
- 4096 —> 4096
- 4096 —> 4096
- 4096 —> 1000
所有隐藏层都配备了 ReLu 激活函数。并且作者没有使用LRN(Local Response Normalisation by AlexNet),这种归一化的方式没有提高模型的性能,却使得内存消耗核计算时间的增加,如下图:

卷积层的通道数(number of channels)以64开始并在最大池化层后增加2倍,直至到达512。
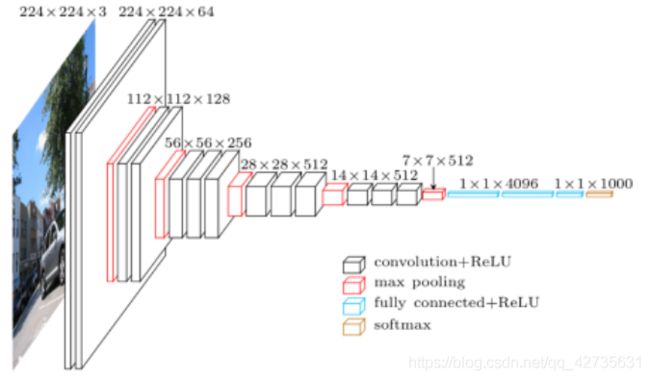
结构如下图所示:

网上的图:对应于上面的VGG(D)
2.2 感受野:
在本文中,使用了3个 3*3 卷积核代替了 7*7 卷积核,使用了2个 **33 卷积核代替了 5*5 卷积核,这样做的好处:
- 增加了网络的深度以学习到更复杂的东西
- 减少了模型的参数
下面介绍为什么可以代替以及模型参数为什么会减少
2.2.1 为什么可以代替
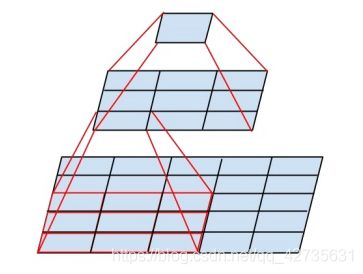
以2个 3*3 卷积核代替 5*5 卷积核为例:首先介绍特征图在通过卷积后大小是如何变的:
Feature Size的计算公式: n o u t = n i n − k + 2 p s + 1 n_{out} = \frac {n_{in}-k+2p} {s} + 1 nout=snin−k+2p+1
- n i n n_{in} nin:size of input feature
- n o u t n_{out} nout:size of output feature
- k k k:kernel size
- p p p:padding size
- s s s:stride size
现在我们有一个特征图的大小为(5,5),卷积核的padding默认为0,stride默认为1
- 通过一个卷积核大小为 5*5 后的大小变为:(1,1)
- ‘ 5 − 5 + 0 1 + 1 = 1 `\frac {5 - 5 + 0} {1}+1=1 ‘15−5+0+1=1
- 通过二个卷积核大小为 3*3 后的大小变为:(1,1)
- 5 − 3 + 0 1 + 1 = 3 \frac {5-3+0} {1} + 1 = 3 15−3+0+1=3
- 3 − 3 + 0 1 + 1 = 1 \frac{3-3+0} {1}+1=1 13−3+0+1=1
过程如下图:
2.2.2 模型参数为什么会减少
以3个 3*3 卷积核代替 7*7 卷积核为例:假设输入通道与输出通道相同,都为 C C C
- 3个 3*3 卷积核的参数: 3 ⋅ ( 3 2 C 2 ) = 27 C 2 3\cdot(3^2C^2)=27C^2 3⋅(32C2)=27C2
- 1个 7*7 卷积核的参数: 7 2 C 2 = 49 C 2 7^2C^2=49C^2 72C2=49C2
2.3 初始化
使用此Understanding the difficulty of training deep feedforward neural networks文章中提到的的初始化方式——Xavier 初始化可以不需要预训练。
2. 基于Pytorch代码复现:
2.1 模型预览
model = models.vgg16(pretrained=True)
print(model)
summary(model, input_size=(3, 224, 224))
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-32 [-1, 512, 7, 7] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.78
Params size (MB): 527.79
Estimated Total Size (MB): 747.15
---------------------------------------------------------------
2.2 模型搭建:
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weight=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weight:
self._init_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def make_features(cfgs: list):
layers = []
in_channels = 3
for v in cfgs:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels=in_channels, out_channels=v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
# key对应于论文的模型
# A -> vgg11
# B -> vgg13
# D -> vgg16
# E -> vgg19
cfgs = {
"A": [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
"B": [64, 64, 'M', 128, 128, 'M', 256, 156, 'M', 512, 512, 'M', 512, 512, 'M'],
"D": [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
"E": [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
def vgg(model_name='D', **kwargs):
assert model_name in cfgs, "Warning: model {} not in cfgs dict!!!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
3. 训练结果如下:
- 训练数据集与验证集大小以及训练参数设置
Using 3306 images for training, 364 images for validation
Using cuda GeForce RTX 2060 device for training.
lr: 0.0001
batch_size:1
- 使用自己定义的网络训练结果
[epoch 1/10] train_loss: 1.428 val_acc: 0.401
[epoch 2/10] train_loss: 1.343 val_acc: 0.407
[epoch 3/10] train_loss: 1.277 val_acc: 0.503
[epoch 4/10] train_loss: 1.162 val_acc: 0.549
[epoch 5/10] train_loss: 1.120 val_acc: 0.555
[epoch 6/10] train_loss: 1.112 val_acc: 0.519
[epoch 7/10] train_loss: 1.052 val_acc: 0.610
[epoch 8/10] train_loss: 0.991 val_acc: 0.684
[epoch 9/10] train_loss: 0.939 val_acc: 0.701
[epoch 10/10] train_loss: 0.922 val_acc: 0.687
Best acc: 0.701
Finished Training
Train 耗时为:828.6s
- 使用预训练模型参数训练结果
[epoch 1/10] train_loss: 0.670 val_acc: 0.805
[epoch 2/10] train_loss: 0.411 val_acc: 0.868
[epoch 3/10] train_loss: 0.406 val_acc: 0.824
[epoch 4/10] train_loss: 0.338 val_acc: 0.876
[epoch 5/10] train_loss: 0.318 val_acc: 0.907
[epoch 6/10] train_loss: 0.283 val_acc: 0.887
[epoch 7/10] train_loss: 0.244 val_acc: 0.896
[epoch 8/10] train_loss: 0.282 val_acc: 0.879
[epoch 9/10] train_loss: 0.269 val_acc: 0.904
[epoch 10/10] train_loss: 0.388 val_acc: 0.863
[epoch 10/10] train_loss: 0.249 val_acc: 0.868
Best acc: 0.907
Finished Training
Train 耗时为:614.8s
上一篇:AlexNet
下一篇:GoogLeNet
完整代码