基于深度学习的点云分割网络及点云分割数据集
作者:Sura
引言
点云分割是根据空间、几何和纹理等特征对点云进行划分,使得同一划分内的点云拥有相似的特征。点云的有效分割是许多应用的前提,例如在三维重建领域,需要对场景内的物体首先进行分类处理,然后才能进行后期的识别和重建。传统的点云分割主要依赖聚类算法和基于随机采样一致性的分割算法,在很多技术上得到了广泛应用,但当点云规模不断增大时,传统的分割算法已经很难满足实际需要,这时就需要结合深度学习进行分割。本文将重点介绍5种前沿的点云分割网络,包括PointNet/PointNet++、PCT、Cylinder以及JSNet网络,最后介绍5中常用的点云分割数据集。
1. PointNet/PointNet++
说起点云分割网络,就不得不介绍PointNet,它来源于CVPR的论文“Deep Learning on Point Sets for 3D Classification and Segmentation”。PointNet是首个输入3D点云输出分割结果的深度学习网络,属于开山之作,成为了后续很多工作的BaseLine,网络的总体结构如图1所示。
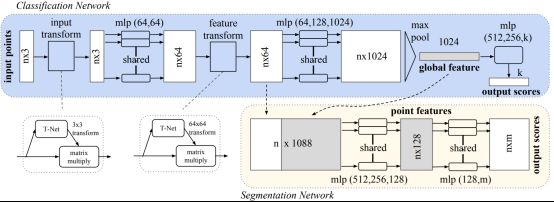
图1 PointNet网络
整体的PointNet网络中,除了点云的感知以外,还有T-Net,即3D空间变换矩阵预测网络,这主要是由于点云分类的旋转不变性,当一个N×D在N的维度上随意的打乱之后,其表述的其实是同一个物体,因此针对点云的置换不变性,其设计的网络必须是一个对称的函数。
在PointNet网络中,对于每一个N×3的点云输入,网络先通过一个T-Net将其在空间上对齐(旋转到正面),再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的1×1024的向量就是N个点云的全局特征。
PointNet网络在ShapeNet数据集上的实验效果如表1所示,可以看出,大多数分割都取得了SOAT效果。部分分割结果如图2所示,可以看出分割结果相当平稳,并且具有很强的鲁棒性。
表1 PointNet在ShapeNet上的分割效果对比


图2 PointNet部分分割结果
PointNet++主要是为了克服PointNet自身的一些缺点,其中最大的缺点就是缺失局部特征。由于PointNet直接暴力地将所有的点最大池化为一个全局特征,因此局部点与点之间的联系并没有被网络学习到。在分类和物体的Part Segmentation中,这样的问题还可以通过中心化物体的坐标轴部分地解决,但在场景分割中,这就会导致效果变差。
为了克服PointNet的缺点,作者在PointNet++中主要借鉴了CNN的多层感受野的思想。CNN通过分层不断地使用卷积核扫描图像上的像素并做内积,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。而PointNet++就是仿照了这样的结构,先通过在整个点云的局部采样并划一个范围,将里面的点作为局部的特征,用PointNet进行一次特征的提取。因此,通过了多次这样的操作以后,原本的点的个数变得越来越少,而每个点都是有上一层更多的点通过PointNet提取出来的局部特征,也就是每个点包含的信息变多了。
PointNet++的网络结构如图3所示,同时作者对比了PointNet和PointNet++的分割效果如图4所示,可见PointNet++的效果全面优于PointNet。

图3 PointNet++网络结构

图4 PointNet++分割结果
2. PCT网络
近年来,NLP领域的Transformer大火,同时也有大量学者将其从NLP领域迁移到图像和点云领域。清华大学将Transformer应用于3D点云分割技术,设计了全新的PCT(Point Cloud Transformer)网络,其网络结构如图5所示。
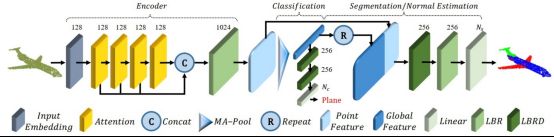
图5 PCT网络结构
PCT应用Transformer进行点云分割的具体原理如图6所示,其中星号代表Transformer的查询向量,黄色到蓝色代表注意力权重逐渐增加,最后一列代表分割结果。

图6 PCT点云分割原理
为了更好地捕获点云中的local context,作者在最远点采样和最近邻居搜索的支持下增强了输入嵌入,同时Transformer在点云分割领域的成功,也逐渐打通了NLP、图像、点云等不同领域的壁垒,对于“模型大一统”具有重要意义。PCT点云分割与其他分割算法的对比如图7所示,大量的实验表明,PCT在形状分类,part分割和法向量估算任务方面达到了最先进的性能。
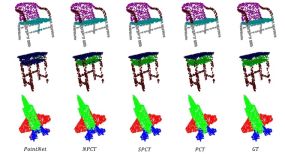
图6 PCT点云分割效果与其他算法对比
3. Cylinder网络
Cylinder网络来源于CVPR论文“Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation”,Cylinder网络结构如图7所示。Cylinder网络由圆柱坐标体素划分和非对称3D卷积网络组成,作者认为圆柱分割可以有效提高分割精度,此外作者还引入了一个point-wise模块来改进体素块输出,提高辨识精度。
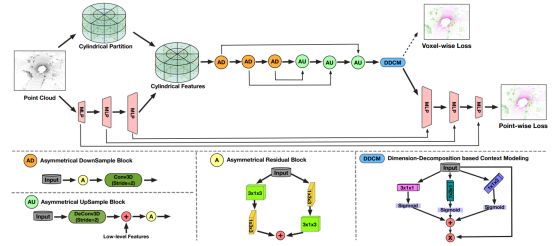
图7 Cylinder网络结构
作者认为基于柱坐标的voxel的划分,可以与激光雷达扫描过程保持一致。进而有效地减少空voxel的比率。此外,作者将Cylinder网络在两个大型室外场景数据集(SemanticKITTI和nuScenes)上进行了评估,评估效果对比如表2和表3所示。评估显示,在SemanticKITTI数据集上,Cylinder网络排名第一。在nuScenes数据集上,新方法的表现也大大超过了之前的方法。
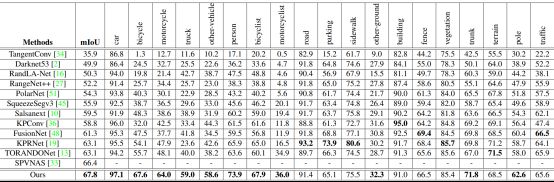
表2 Cylinder网络在SemanticKITTI数据集上的对比效果

表3 Cylinder网络在nuScenes数据集上的对比效果
4. JSNet网络
JSNet来源于AAAI论文“JSNet: Joint Instance and Semantic Segmentation of 3D Point Clouds”,JSNet可以同时解决3D点云的实例和语义分割问题,其网络结构如图8所示。
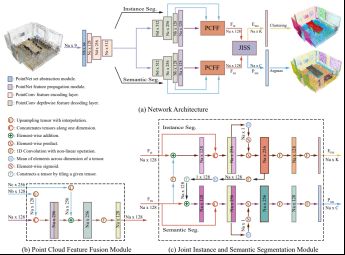
图8 JSNet网络结构
JSNet首先建立有效的骨干网络,以从原始点云数据中提取鲁棒的特征。其次为了获得更多的判别特征,提出了一种点云特征融合模块来融合骨干网的不同层特征。此外,JSNet开发了联合实例语义分割模块以将语义特征转换为实例嵌入空间,然后将转换后的特征进一步与实例特征融合以促进实例分割。同时,该模块还将实例特征聚合到语义特征空间中,以促进语义分割。最后,JSNet通过对实例嵌入应用简单的均值漂移聚类来生成实例预测。
如表4和表5所示是JSNet网络在大型3D室内点云数据集S3DIS上的评估结果,图9是JSNet网络的分割效果。实验结果表明,JSNet网络在3D实例分割中的性能优于最新方法,在3D语义预测方面有重大改进,同时有利于零件分割。
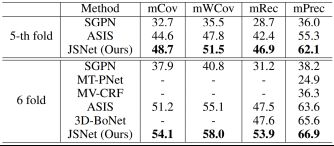
表4 JSNet网络在S3DIS数据集上的实例分割结果
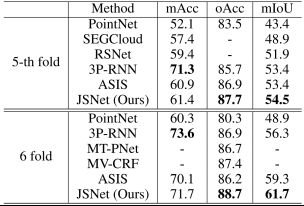
表5 JSNet网络在S3DIS数据集上的语义分割结果

图9 JSNet网络的分割效果
5. 点云分割数据集
深度神经网络的训练往往需要大量的数据集,同时深度神经网络性能的优劣也往往是在公开数据集上进行评估,因此选择合适的数据集至关重要。常用的点云分割数据集主要有如下几个:
5.1 Semantic3D
经典的大型室外场景点云分割数据集,由激光雷达扫描周围场景得到。Semantic3D提供了一个带有大标签的自然场景的3D点云数据集,总计超过40亿个点,8个类别标签。
数据集包含了各种城市和乡村场景,如农场,市政厅,运动场,城堡和广场。该数据集包含15个训练数据集和15个测试数据集,另外还包括4个缩减了的测试数据集。数据集中的点都含有RGB和深度信息,并被标记为8个语义类别,分别是1:人造地形;2:自然地形;3:高植被;4:低植被;5:建筑物;6:硬景观;7:扫描人工制品,8:汽车,附加标签0:未标记点,标记没有地面真值的点。
数据集地址:Semantic3D


5.2 S3DIS
S3DIS数据集是斯坦福大学开发的带有像素级语义标注的语义数据集,是常用的室内场景分割数据集,使用Matterport相机收集数据,包含6个Area,13个语义元素,11种场景。
其中13个语义元素分别包括:天花板ceiling、地板floor、墙壁wall、梁beam、柱column、窗window、门door、桌子table、椅子chair、沙发sofa、书柜bookcase、板board、混杂元素(其他)clutter;11种场景分别包括办公室office、会议室conference room、走廊hallway、礼堂auditorium、开放空间open space、大堂lobby、休息室lounge、储藏室pantry、复印室copy room、储藏室storage和卫生间WC。
数据集地址:http://buildingparser.stanford.edu/dataset.html


5.3 SemanticKITTI
SemanticKITTI数据集是一个基于KITTI Vision Benchmark里程计数据集的大型户外点云数据集,显示了市中心的交通、住宅区,以及德国卡尔斯鲁厄周围的高速公路场景和乡村道路。原始里程计数据集由22个序列组成,作者将序列00到10拆分为训练集,将11到21拆分为测试集,并且为了与原始基准保持一致,作者对训练和测试集采用相同的划分,采用和KITTI数据集相同的标定方法,这使得该数据集和KITTI数据集等数据集可以通用。
SemanticKITTI数据集作者提供了精确的序列扫描注释,并且在点注释中显示了前所未有的细节,包含28个类,确保了类与Mapillary Visiotas数据集和Cityscapes数据集有很大的重叠,并在必要时进行了修改,以考虑稀疏性和垂直视野。
数据集地址:SemanticKITTI - A Dataset for LiDAR-based Semantic Scene Understanding

5.4 ShapeNet
ShapeNet数据集是一个由对象的三维CAD模型表示的形状存储库,注释丰富,规模较大。ShapeNet包含来自多种语义类别的3D模型,并按照WordNet分类法组织,能够完成部件分割任务,即不仅知道这个点云数据大的分割,还要将它的小部件进行分割。它总共包括十六个大的类别,每个大的类别有可以分成若干个小类别,十六个类别具体包括:飞机Airplane、包Bag、帽子Cap、汽车Car、椅子Chair、耳机Earphone、吉他Guitar、刀Knife、灯Lamp、电脑Laptop、摩托车Motorbike、杯子Mug、手枪Pistol、火箭Rocket、滑板Skateboard、桌子Table。
数据集地址:ShapeNet


5.5 PartNet
PartNet数据集是用于细粒度和分层零件级3D对象理解的大规模基准。数据集包含573585个零件实例,涵盖26671个3D模型,涵盖24个对象类别。PartNet数据集启用并充当许多任务的催化剂,例如形状分析,动态3D场景建模和仿真,可负担性分析等。数据集建立了用于评估3D零件识别的三个基准测试任务:细粒度语义分割,分层语义分割和实例分割。
数据集地址:Login

6. 总结
近年来,随着自动驾驶和三维重建技术的不断发展,需要处理的点云规模越来越庞大,传统的聚类算法和基于随机采样一致性的分割算法较难满足实时性和精度要求。而基于深度学习的点云分割网络较好地解决了上述问题,本文重点介绍了几种前沿的点云分割网络,包括PointNet/PointNet++、PCT、Cylinder以及JSNet网络,并介绍了5种常用的点云分割数据集。读者在应用深度学习进行点云分割或设计点云分割网络时,要根据自身需求和实际工况,有针对地选择合适的点云分割网络和数据集。