从广义线性回归推导出逻辑回归
从广义线性回归推导出逻辑回归(LogisticRegression) – 潘登同学的Machine Learning笔记
文章目录
- 从广义线性回归推导出逻辑回归(LogisticRegression) -- 潘登同学的Machine Learning笔记
- Logistic回归
- 广义线性回归
-
- 指数族分布(The exponential family distribution)
-
- 推导说明伯努利分布是指数族分布
- sigmoid函数
- 回看多元线性回归
- Loss函数的推导与求解
-
- 采用最大似然估计MLE来构造损失函数
- 求解Loss的最小值
- 直观感受Loss函数的形状
- Logistic的实际应用
-
- 实战Logistic对鸯尾花的分类
Logistic回归
总目标:分类
逻辑回归就是在多元线性回归基础上把结果缩放到 0 到 1 之间。 h θ ( x ) h_{\theta}(x) hθ(x) 越接近1 越是正例, h θ ( x ) h_{\theta}(x) hθ(x) 越接近 0 越是负例,根据中间 0.5 分为二类;
模型:
y ^ = h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x \hat{y} = h_{\theta}(x)= g(\theta^Tx) = \frac{1}{1+e^{-\theta^Tx}} y^=hθ(x)=g(θTx)=1+e−θTx1
y ^ \hat{y} y^值: 概率含义( y ^ \hat{y} y^越大说明分成
正例的概率越大)分类器的本质就是要找到分界,所以当我们把 0.5 作为分界时,我们要找的就是
y ^ = h θ ( x ) = 1 1 + e − θ T x = 0.5 \hat{y} = h_{\theta}(x) = \frac{1}{1+e^{-\theta^Tx}} = 0.5 y^=hθ(x)=1+e−θTx1=0.5
的时候 θ \theta θ的解, 即 z = θ T x = 0 z = \theta^Tx = 0 z=θTx=0的解;而这个函数也称为sigmoid函数;
优化目标:分类的越精确越好, 分对的越多越好
很自然而然的可以想到loss函数大概就是: 分对的概率取个负数(loss越小越好)
L ( θ ) = − ∑ i = 1 m ( y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) L(\theta) = -\sum_{i=1}^{m}(y_{i}\log h_{\theta}(x_{i}) + (1-y_{i})\log (1-h_{\theta}(x_{i})) L(θ)=−i=1∑m(yiloghθ(xi)+(1−yi)log(1−hθ(xi))
这个Loss函数也称为交叉熵;
注意: 这里的y是标签值(0代表负例, 1代表正例), 而 h θ ( x i ) h_{\theta}(x^{i}) hθ(xi)才是预测值;
方便理解起见,考虑这样一种完美情况:
-
这个分类器把所有例子都分对了, 且分类器给出的指标特别完美, y ^ \hat{y} y^的值就是0或1, 没有不确定的因素存在;
-
那么当标签 y i y^i yi是1的时候, 我们的预测值 y i ^ = h θ ( x i ) \hat{y^i}=h_{\theta}(x^{i}) yi^=hθ(xi)也是1, 两者相乘为1; 后一项 ( 1 − y i ) log ( 1 − h θ ( x i ) (1-y^{i})\log (1-h_{\theta}(x^{i}) (1−yi)log(1−hθ(xi)自然是0;
-
那么当标签 y i y^i yi是0的时候, 我们的预测值 y i ^ = h θ ( x i ) \hat{y^i}=h_{\theta}(x^{i}) yi^=hθ(xi)也是0, 两者相乘为0; 后一项 ( 1 − y i ) log ( 1 − h θ ( x i ) (1-y^{i})\log (1-h_{\theta}(x^{i}) (1−yi)log(1−hθ(xi)自然是1;
所以无论标签值为多少, 求和的每一项都是1, 前面又有负号,那么Loss函数就是最小的,就是-m; (不可能存在 ( y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) (y^{i}\log h_{\theta}(x^{i}) + (1-y^{i})\log (1-h_{\theta}(x^{i})) (yiloghθ(xi)+(1−yi)log(1−hθ(xi))比1大的情形,因为标签是0和1, y i y^{i} yi是概率值, 这个式子其实就是0和1的加权平均, 最大值显然是1)
后面还会详细讲loss函数, 先有初步感知即可;
广义线性回归
考虑一个分类或回归问题,我们就是想预测某个随机变量 y,y 是某些特征(feature)x 的函数。为了推导广义线性模式,我们必须做出如下三个假设:
- p ( y ∣ x ; θ ) p(y|x;\theta) p(y∣x;θ)服从指数族分布
- 给定 x x x,我们的目的是为了预测 T ( y ) T(y) T(y)在条件 x x x下的期望, 一般情况下 T ( y ) = y T(y)=y T(y)=y, 这就意味着我们希望预测
h ( x ) = E [ y ∣ x ] ( h 表 示 模 型 ) h(x) = E[y|x] (h表示模型) h(x)=E[y∣x](h表示模型) - 参数 η \eta η和输入x是线性相关的: η = θ T x \eta = \theta^Tx η=θTx
`
指数族分布(The exponential family distribution)
指数族分布有:高斯分布、二项分布、伯努利分布、多项分布、泊松分布、指数分布、 beta 分布、拉普拉斯分布、gamma 分布。对于回归来说,如果因变量 y 服从某个指数族分布,那么我们就可以用广义线性回归来建模。比如说如果 y 是服从伯努利分布,我们可以 使用逻辑回归(也是一种广义线性模型)。
指数族分布的一般形式
P ( y ; η ) = b ( y ) e ( η T T ( y ) − a ( η ) ) P(y;\eta) = b(y) e^{(\eta^TT(y)-a(\eta))} P(y;η)=b(y)e(ηTT(y)−a(η))
其中:
- η \eta η是自然参数(natural parameter,also called theoretical parameter)
- T(y) 是充分统计量(sufficient statistic),一般情况下就是 y
- a ( η ) a(\eta) a(η) 是对数部分函数(log partition function),这部分确保 Y 的分布 P ( y ; η ) P(y;\eta) P(y;η) 计算的结果加起来(连续函数是积分)等于 1
推导说明伯努利分布是指数族分布
伯努利分布
P ( y ; p ) = p y ( 1 − p ) 1 − y P(y;p) = p^y(1-p)^{1-y} P(y;p)=py(1−p)1−y
将上式写成指数形式
P ( y ; η ) = e y log p + ( 1 − y ) log ( 1 − p ) = e ( log ( p 1 − p ) y + log ( 1 − p ) ) \begin{aligned} P(y;\eta) & = e^{y \log p+(1-y)\log(1-p)} \\ & = e^{(\log(\frac{p}{1-p})y+\log(1-p))} \\ \end{aligned} P(y;η)=eylogp+(1−y)log(1−p)=e(log(1−pp)y+log(1−p))
对应回指数族分布的一般形式:
- η = θ T x = log p 1 − p \eta = \theta^Tx = \log \frac{p}{1-p} η=θTx=log1−pp
则有:
e θ T x = p 1 − p ⇒ p = e θ T x − e θ T x ⋅ p = e θ T x 1 + e θ T x = 1 1 + e − θ T x e^{\theta^Tx} = \frac{p}{1-p} \\ \begin{aligned} \Rightarrow p & = e^{\theta^Tx} - e^{\theta^Tx} \cdot p \\ & = \frac{e^{\theta^Tx}}{1+e^{\theta^Tx}} \\ & = \frac{1}{1+e^{-\theta^Tx}} \\ \end{aligned} eθTx=1−pp⇒p=eθTx−eθTx⋅p=1+eθTxeθTx=1+e−θTx1
诶!! 这不就是sigmoid函数吗?
然后再回想这个二分类本质到低是啥?
二分类不就跟赌大小一样嘛? 要么是大,要么是小;
那这个二分类任务不就可以看成伯努利分布吗?
如果p就是预测正确的概率, 那预测正确的数量y的概率密度函数不就是 p y ( 1 − p ) 1 − y p^y(1-p)^{1-y} py(1−p)1−y嘛…
sigmoid函数

- sigmoid函数的作用
逻辑回归就是在多元线性回归基础上把结果缩放到 0 到 1 之间。 h θ ( x ) h_{\theta}(x) hθ(x) 越接近1 越是正例, h θ ( x ) h_{\theta}(x) hθ(x) 越接近 0 越是负例,根据中间 0.5 分为二类; 所以sigmoid函数的作用就起到非线性变换的目的;
注意:这始终是广义线性回归模型, 线性回归就是 y = θ T x y=\theta^Tx y=θTx, 我们想求解的永远是 θ \theta θ而不是这个sigmoid;
回看多元线性回归
在多元线性回归中, 我们不是假设误差 ε \varepsilon ε服从正太分布嘛;
正态分布也是一种指数分布;
f ( ε i ∣ μ , σ 2 ) = 1 2 π σ 2 e − ( ε i − μ ) 2 2 σ 2 = 1 2 π σ 2 e − y 2 2 σ 2 ⋅ e 2 μ y − μ 2 2 σ 2 \begin{aligned} f(\varepsilon_i|\mu,\sigma^2) &= \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(\varepsilon_i-\mu)^2}{2\sigma^2}}\\ &= \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{y^2}{2\sigma^2}}\cdot e^{\frac{2\mu y-\mu^2}{2\sigma^2}} \end{aligned} f(εi∣μ,σ2)=2πσ21e−2σ2(εi−μ)2=2πσ21e−2σ2y2⋅e2σ22μy−μ2
其中, 乘号前面视为 b ( y ) b(y) b(y), 2 μ 2 σ 2 \frac{2\mu}{2\sigma^2} 2σ22μ视为 η \eta η, y视为 T ( y ) T(y) T(y), μ 2 2 σ 2 \frac{\mu^2}{2\sigma^2} 2σ2μ2视为 a ( η ) a(\eta) a(η);
所以多元线性回归的形式就是
y ^ = η = θ T x \hat{y} = \eta = \theta^Tx y^=η=θTx
Loss函数的推导与求解
我们的目标, 根据已知的 x , y x,y x,y,找到一组 θ \theta θ使得 x x x作为已知条件下y发生的概率最大;
P ( 预 测 正 确 ) = { g ( θ , x i ) , 当 y i = 1 时 1 − g ( θ , x i ) , 当 y i = 0 时 P(预测正确)= \begin{cases} g(\theta, x_i), 当y_i = 1时 \\ 1 - g(\theta, x_i), 当y_i = 0时 \\ \end{cases} P(预测正确)={g(θ,xi),当yi=1时1−g(θ,xi),当yi=0时
( g ( θ , x i ) g(\theta, x_i) g(θ,xi)就是 y ^ \hat{y} y^, 也就是 h θ ( x i ) h_{\theta}(x_i) hθ(xi))
- 也可以这样理解
| y ^ ⇓ \hat{y}\Downarrow y^⇓ y ⇒ y\Rightarrow y⇒ | 0 | 1 |
|---|---|---|
| 0 | 1 − g ( θ , x i ) 1 - g(\theta, x_i) 1−g(θ,xi) | |
| 1 | g ( θ , x i ) g(\theta,x_i) g(θ,xi) |
-
将上式写在一条式子中
P ( 预 测 正 确 ) = g ( θ , x i ) y i ⋅ ( 1 − g ( θ , x i ) ) 1 − y i P(预测正确)=g(\theta, x_i)^{y_i} \cdot (1 - g(\theta, x_i))^{1-y_i} P(预测正确)=g(θ,xi)yi⋅(1−g(θ,xi))1−yi -
改写成熟悉的形式
P ( y ∣ x ; θ ) = ( h θ ( x ) ) y ⋅ ( 1 − h θ ( x ) ) 1 − y P(y|x;\theta)=(h_{\theta}(x))^{y} \cdot (1 - h_{\theta}(x))^{1-y} P(y∣x;θ)=(hθ(x))y⋅(1−hθ(x))1−y
采用最大似然估计MLE来构造损失函数
-
最大化正确分类的概率
L ( θ ) = ∏ i = 1 m P ( y i ∣ x i ; θ ) = ∏ i = 1 m ( h θ ( x i ) ) y i ⋅ ( 1 − h θ ( x i ) ) 1 − y i \begin{aligned} {\Bbb{L}(\theta)} &= \prod_{i=1}^{m} P(y_i|x_i;\theta)\\ &= \prod_{i=1}^{m}(h_{\theta}(x_i))^{y_i} \cdot (1 - h_{\theta}(x_i))^{1-y_i}\\ \end{aligned} L(θ)=i=1∏mP(yi∣xi;θ)=i=1∏m(hθ(xi))yi⋅(1−hθ(xi))1−yi -
取对数, 将连乘变为连加
log L ( θ ) = ∑ i = 1 m [ y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ] \begin{aligned} \log {\Bbb{L}(\theta)} = \sum_{i=1}^{m}[y_i \log h_{\theta}(x_i) + (1-y_i)\log(1 - h_{\theta}(x_i))] \end{aligned} logL(θ)=i=1∑m[yiloghθ(xi)+(1−yi)log(1−hθ(xi))] -
上面求最大, 下面求最小(得出Loss function)
L o s s = − ∑ i = 1 m [ y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ] Loss = - \sum_{i=1}^{m}[y_i \log h_{\theta}(x_i) + (1-y_i)\log(1 - h_{\theta}(x_i))] Loss=−i=1∑m[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
求解Loss的最小值
-
先对sigmoid函数求导
g ( z ) = 1 1 + e − z g ′ ( z ) = e − z 1 ( 1 + e − z ) 2 = 1 1 + e − z ( 1 − 1 1 + e − z ) = g ( z ) ( 1 − g ( z ) ) g(z) = \frac{1}{1+e^{-z}} \\ \begin{aligned} g'(z) &= e^{-z}\frac{1}{(1+e^{-z})^2}\\ &= \frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})\\ &= g(z)(1-g(z))\\ \end{aligned} g(z)=1+e−z1g′(z)=e−z(1+e−z)21=1+e−z1(1−1+e−z1)=g(z)(1−g(z)) -
回到对Loss的求导
∂ ∂ θ j L o s s = − ∑ i = 1 m [ y i ⋅ 1 h θ ( x i ) ⋅ ∂ h θ ( x i ) ∂ θ j − ( 1 − y i ) ⋅ 1 1 − h θ ( x i ) ⋅ ∂ h θ ( x i ) ∂ θ j ] = − ∑ i = 1 m [ y i ⋅ 1 h θ ( x i ) ⋅ − ( 1 − y i ) ⋅ 1 1 − h θ ( x i ) ] ∂ h θ ( x i ) ∂ θ j = − ∑ i = 1 m [ y i ⋅ 1 g ( θ T x i ) ⋅ − ( 1 − y i ) ⋅ 1 1 − g ( θ T x i ) ] g ( θ T x i ) ( 1 − g ( θ T x i ) ) ∂ θ T x i ∂ θ j = − ∑ i = 1 m [ y i ( 1 − g ( θ T x i ) ) − ( 1 − y i ) g ( θ T x i ) ] x i j = − ∑ i = 1 m [ y i − g ( θ T x i ) ] x i j = ∑ i = 1 m [ h θ ( x i ) − y i ] x i j \begin{aligned} \frac{\partial}{\partial \theta_j}Loss &= -\sum_{i=1}^{m}[y_i \cdot \frac{1}{h_{\theta}(x_i)} \cdot \frac{\partial h_{\theta}(x_i)}{\partial \theta_j} - (1-y_i) \cdot \frac{1}{1 - h_{\theta}(x_i)} \cdot \frac{\partial h_{\theta}(x_i)}{\partial \theta_j}] \\ &= -\sum_{i=1}^{m}[y_i \cdot \frac{1}{h_{\theta}(x_i)} \cdot - (1-y_i) \cdot \frac{1}{1 - h_{\theta}(x_i)}]\frac{\partial h_{\theta}(x_i)}{\partial \theta_j} \\ &= -\sum_{i=1}^{m}[y_i \cdot \frac{1}{g(\theta^Tx_i)} \cdot - (1-y_i) \cdot \frac{1}{1 - g(\theta^Tx_i)}]g(\theta^Tx_i)(1-g(\theta^Tx_i)) \frac{\partial \theta^Tx_i}{\partial \theta_j}\\ &= -\sum_{i=1}^{m}[y_i(1-g(\theta^Tx_i))-(1-y_i)g(\theta^Tx_i)]x_i^j \\ &= -\sum_{i=1}^{m}[y_i-g(\theta^Tx_i)]x_i^j \\ &= \sum_{i=1}^{m}[h_{\theta}(x_i) - y_i]x_i^j \\ \end{aligned} ∂θj∂Loss=−i=1∑m[yi⋅hθ(xi)1⋅∂θj∂hθ(xi)−(1−yi)⋅1−hθ(xi)1⋅∂θj∂hθ(xi)]=−i=1∑m[yi⋅hθ(xi)1⋅−(1−yi)⋅1−hθ(xi)1]∂θj∂hθ(xi)=−i=1∑m[yi⋅g(θTxi)1⋅−(1−yi)⋅1−g(θTxi)1]g(θTxi)(1−g(θTxi))∂θj∂θTxi=−i=1∑m[yi(1−g(θTxi))−(1−yi)g(θTxi)]xij=−i=1∑m[yi−g(θTxi)]xij=i=1∑m[hθ(xi)−yi]xij
注意:其中 x i j x_i^j xij是因为对第i个样本的第j个参数求导, 所以 x i j x_i^j xij其实就是数据矩阵中的 x i j x_{ij} xij; -
欸!!!这个Loss函数怎么跟多元线性回归那么相似呢?
因为都是广义线性回归, 所以长的都差不多;
直观感受Loss函数的形状
采用了一个breast_cancer的数据集, 然后里面的数据的含义就不解释了(过于敏感), 就只是画loss函数, 与真正的分类任务还差的比较多; (因为一旦维度高了之后,loss函数就画不在3维空间里了)
话不多说, 上代码!!!
#%%逻辑回归loss图像
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
data = load_breast_cancer()
x,y = scale(data['data'][:,:2]),data['target'] #这里为了方便画图,所以只取x的两列
#求出两个维度对应的数据在逻辑回归算法下的最优解
lr = LogisticRegression(fit_intercept=False) #为了方便画图,不加截距项
lr.fit(x,y)
#把参数取出来
w = lr.coef_
#已知w的情况下,传进来数据x,返回数据的y_predict
def p_theta_function(feature,w):
Z = feature.dot(w.T) #Z = xθ
return 1/(1+np.exp(-1*Z))
def loss_fuction(samples_features,samples_labels,w):
result = 0
#遍历数据集中的每一条数据,并且计算每条样本的损失,加到result身上得到整体数据集损失
for feature,label in zip(samples_features,samples_labels):
#这是计算一条样本的y_predict
p_result = p_theta_function(feature,w)
loss_result = -1*label*np.log(p_result) - (1-label)*np.log(1-p_result)
result += loss_result
return result
w1_space = np.arange(w[:,0]-0.6,w[:,0]+0.6,1.2/49)
w2_space = np.arange(w[:,1]-0.6,w[:,1]+0.6,1.2/49)
w1,w2 = np.meshgrid(w1_space, w2_space)
w_list = []
for i in range(50):
temp = []
for j in range(50):
temp.append(loss_fuction(x,y,np.array([w1[i][j],w2[i][j]])))
w_list.append(temp)
result = np.array(w_list)
fig=plt.figure()
ax1 = plt.axes(projection='3d')
ax1.contour(w1,w2,result,30)
ax1.view_init(elev=90., azim=140)
plt.show()
fig=plt.figure()
ax2 = plt.axes(projection='3d')
ax2.plot_surface(w1,w2,result,rstride = 1, cstride = 1,cmap='rainbow')
ax2.view_init(elev=20., azim=140)
plt.show()
结果图像:


Logistic的实际应用
贯彻Machine Learning的一致思路, 当然少不了梯度下降和正则项;
Logistic的实际求解是通过梯度下降解决的, 这里不再细说;
- 含正则项的Logistic的Loss函数
L o s s = − ∑ i = 1 m [ ( h θ ( x i ) ) y i + ( 1 − h θ ( x i ) ) 1 − y i ] + λ 2 ∑ i = 1 n θ j 2 Loss = -\sum_{i=1}^{m}[(h_{\theta}(x_i))^{y_i} + (1 - h_{\theta}(x_i))^{1-y_i}] + \frac{\lambda}{2}\sum_{i=1}^{n} \theta_j^2 Loss=−i=1∑m[(hθ(xi))yi+(1−hθ(xi))1−yi]+2λi=1∑nθj2
- 其偏导为
∂ ∂ θ j L o s s = ∑ i = 1 m [ h θ ( x i ) − y i ] x i j + λ θ j \frac{\partial}{\partial \theta_j}Loss = \sum_{i=1}^{m}[h_{\theta}(x_i) - y_i]x_i^j + \lambda \theta_j ∂θj∂Loss=i=1∑m[hθ(xi)−yi]xij+λθj
实战Logistic对鸯尾花的分类
目标:将数据分为属于setosa和不属于setosa
绘图查看 花瓣长度和花瓣宽度与鸯尾花种类的关系
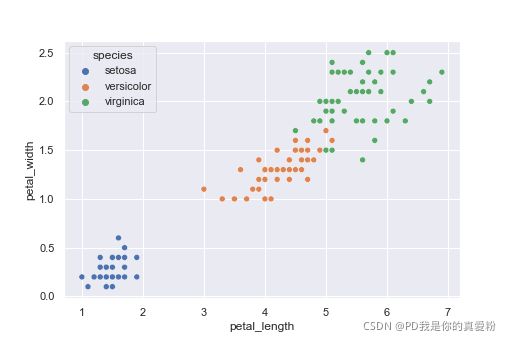
话不多说, 上代码!!!
#%% 逻辑回归实战对鸯尾花的分类
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import seaborn as sns
path = 'iris.csv'
data = pd.read_csv(path)
x = data.iloc[:100,2:4]
y = data.iloc[:100,4]
y = (y == 'setosa').astype(int) #把品种转化为0和1
sns.set()
sns.scatterplot(data['petal_length'],data['petal_width'],hue = data['species'])
#划分训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3)
log_reg = LogisticRegression(solver='sag',max_iter=100000)
log_reg.fit(x_train,y_train)
log_reg.coef_
y_hat = log_reg.predict_proba(x_test)
#这个第一列表示是零这一类的的概率
#将概率转化为预测结果
y_hat = (y_hat[:,0]<0.5).astype(int)
#比较预测结果与实际值
print(y_hat == y_test)
结果如下:

LogisticRegression逻辑回归就是这样了, 继续下一章吧!pd的Machine Learning