BERT(二)--论文理解:BERT 模型结构详解
转载请注明出处:https://blog.csdn.net/nocml/article/details/124951994
传送门:
BERT(一)–论文翻译:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT(二)–论文理解:BERT 模型结构详解
Transformer系列:
Transformer(一)–论文翻译:Attention Is All You Need 中文版
Transformer(二)–论文理解:transformer 结构详解
Transformer(三)–论文实现:transformer pytorch 代码实现
文章目录
- 1. 整体结构
- 2. 输入处理
- 3. 特征选择/学习模块
- 4. 输出模块
-
- 4.1 NSP任务模块 Pooler
- 4.2 MLM任务输出模块
1. 整体结构
transformer是基于机器翻译任务提出的,采用了主流的encoder-decoder框架。而做为后来者的BERT,其核心特征提取模块延用了transformer中的encoder,继而又把此模块应用到了一个(两个子任务)新的任务上。个人看法,BERT在算法上并没有做很多的改进,但在算法的应用上,取得了很大的成功,奠定了预训练模型在NLP领域的主导地位。
为了适用新的任务,BERT构建了自己的输入处理模块与输出处理模块。整体结构如下图:
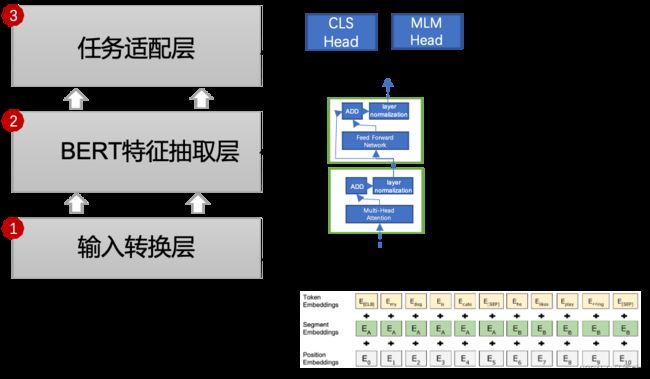
如上图所示模块1为输入模块,其作用是对原始的文字输入进行信息提取,分别提取了字信息,位置信息与句信息(文字是属于前一句还是后一句。)。模块2为特征提取模块,结构采用了transformer中的encoder结构,之前在transfor的文章里讲过,这里不在赘述。模块3为任务处理模块,主要是对模块2的输出做了相应的转换,以支持不同的子任务。后面的两个小节会详细讲解第1和第3个模块。
2. 输入处理
BERT的输入与transformer的输入相比,多了一项句子特征,即当前字符是属于第一句话,还是属于第二句话。之所以增加这个特征,是因为BERT在训练时有个预测句子关系的任务。其它两个特征没有改变,还是字符特征和位置信息特征。但在采集位置信息时,做了一些调整,transfomer里使用的是正弦波,BERT里舍弃了这个相对复杂的方法,直接对位置下标做embedding。 最后把把3个embedding后的向量直接相加,得到最终的字符串表示。整个处理方法简单有效,从而也说明了特征抽取模块的学习能力的强大。这里我还是贴一下原始论文中的图。

其实上面这个图表达的很清楚了,但秉着事无巨细的态度,还是把相关的步骤细化一下。如下图:
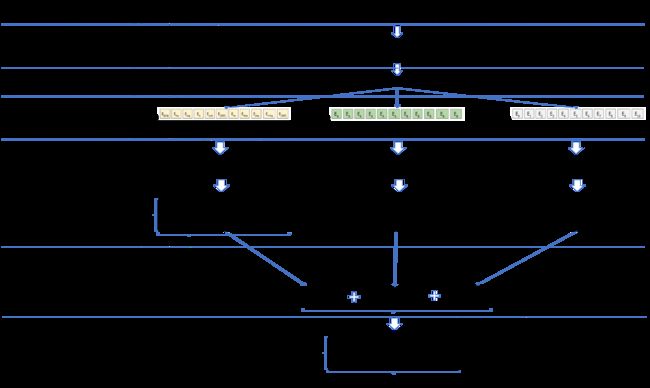
上图中最终的输出是[sentence length,model size] 如果是输出了一个batch,那输出的shape应为[batch size, sentence length, model size](注:上面的shape是我习惯的叫法,也可以表达为[batch size, sequence length, hidden size])
3. 特征选择/学习模块
此模块为Transformer中的encoder模块,具体参考我之前发的关于Transformer的blog。
4. 输出模块
Bert的训练有两个子任务,一个任务(NSP, Next Sentence Prediction)是预测输入中的A和B是不是上下句。另一个是预测随机mask掉的字符的任务(MLM, Masked LM)。两个子任务的输入均来自特征抽取模块,不同的是NSP任务的输入只选取了CLS对应的输出,而序列预测任务的输入则是除CLS对应位置的其它位置的数据。模型最终的损失是这两个子任务损失的加和。整体如下图。

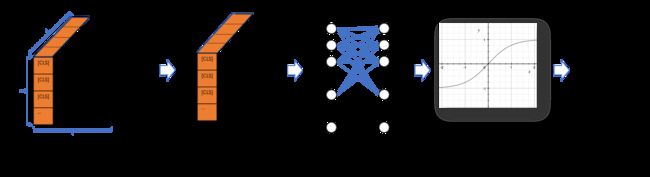
4.1 NSP任务模块 Pooler
在Pooler模块中,会取出每一句的第一个单词(CLS对应的位置数据),做全连接和激活。得到的输出用以做分类任务(NSP任务),整体流程如下图。
# transformers 中的源码
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
4.2 MLM任务输出模块
MLM 任务的输出为BERT提取模块的输出(除CLS对应位置的输出),任务的目标是预测每个被mask掉的字符的原始字符是什么。按照transformers库中的实现来理解,具体的操作可以分为两部分:
- 第一部分为输入转换,其具体操作为先对MLM模块的输出应用一个输出输入均为hidden_size的linear层,之后应用激活函数,这里的激活函数可以有多个选择,用户可以自定义,之后再做leyer normalization。这块比较简单,直接上源码,如下:
class BertPredictionHeadTransform(nn.Module): def __init__(self, config): super().__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) if isinstance(config.hidden_act, str): self.transform_act_fn = ACT2FN[config.hidden_act] else: self.transform_act_fn = config.hidden_act self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps) def forward(self, hidden_states: torch.Tensor) -> torch.Tensor: hidden_states = self.dense(hidden_states) hidden_states = self.transform_act_fn(hidden_states) hidden_states = self.LayerNorm(hidden_states) return hidden_states - 第二部分为把第一部分的输出中的每个字符分类,预测masked字符的原始字符,其操作是使用输入大小为hidden size, 输出大小为vocab size 的linear层对字符进行分类。源码如下:
class BertLMPredictionHead(nn.Module): def __init__(self, config): super().__init__() self.transform = BertPredictionHeadTransform(config) # The output weights are the same as the input embeddings, but there is # an output-only bias for each token. self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False) self.bias = nn.Parameter(torch.zeros(config.vocab_size)) # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings` self.decoder.bias = self.bias def forward(self, hidden_states): hidden_states = self.transform(hidden_states) hidden_states = self.decoder(hidden_states) return hidden_states