Python数据分析与可视化模块——第1节 数据分析基础和series
第一章pandas基础之series
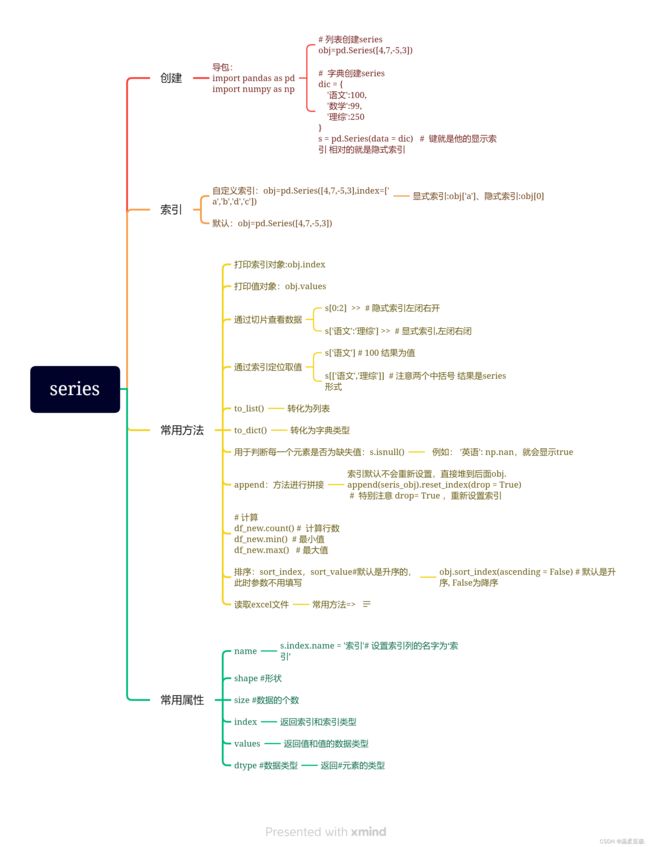
思维导图:
pandas的数据结构
-
Series # 可以看成是一个表中的行或者列
-
Dataframe # 可以看成是表
重点关注是 Dataframe和series的关系
关系 : 表是由行和列组成的 也就是说 Dataframe是由 Series组成的 .
series简介及其简单操作
Series:是由一组数据以及索引组成
创建series
import pandas as pd
import numpy as np
# series里面是数组或者是列表
# 列表创建series
obj=pd.Series([4,7,-5,3])
print(type(obj)) #
# numpy 创建series
s = pd.Series(np.random.randint(0,100,size=(3)))
# series可以看成是字典列表的结合体 ,所以可以用字典进行创建
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data = dic) # 键就是他的显示索引 相对的就是隐式索引
s
# 可以看成是字典和列表的集合体
s['语文'] >> 100 # 也可以写成 s.语文
s[0] >> 100
# 特别注意 :
不要以为是"竖着的" 就是列 ,它也可以是行 ,所以说 series是行或者列 自定义索引
# 索引默认是 0 1 2 3 可以自定义
obj1=pd.Series([4,7,-5,3])
obj1=pd.Series([4,7,-5,3],index=['a','b','d','c'])
# ,注意:Series 中的索引值是可以重复的(了解)
obj1=pd.Series([4,7,-5,3],index=['a','b','b','c'])
obj1series索引和值
>>> obj.values #值是数组的形式
array([ 4, 7, -5, 3], dtype=int64)
>>> obj.index #索引对象
RangeIndex(start=0, stop=4, step=1)
通过切片查看数据
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data=dic)
# 重点注意 : 隐式索引和显式索引的概念
s[0:2] >> # 隐式索引左闭右开
s['语文':'理综'] >> # 显式索引,左闭右闭
通过索引定位取值
# 查找 语文和理综的数据
s['语文'] # 100
s[['语文','理综']] # 注意两个中括号 是series形式
s[[1,0]]运算
s1 = pd.Series(data=[1,4,3],index=['a','b','c'])
s2 = pd.Series(data=[1,2,3],index=['a','b','c'])
s = s1 + s2
s1 + 4series的常用属性
-
name属性
-
shape # 形状
-
size # 数据的个数
-
index
-
values
-
dtype
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data=dic)
s.index.name = '索引'
索引
语文 100
数学 99
理综 250
dtype: int64
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data=dic)
s.shape #代表 3 个
>>> (3,)
s.size
>>> 3
s.index #返回索引
>> Index(['语文', '数学', '理综'], dtype='object')
s.values #返回值
>>array([100, 99, 250], dtype=int64)
s.dtype #元素的类型
>>dtype('int64')
series的常用方法
to_list()
to_dict()
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data=dic)
s.to_list() # 值的转化成列表 [100, 99, 250]
s.to_dict() # {'语文': 100, '数学': 99, '理综': 250}
s.index.to_list() # ['语文', '数学', '理综']
s.values.tolist() # s.to_list() 一样的 注意区别 isnull() 用于判断每一个元素是否为缺失值
#s.isnull() #用于判断每一个元素是否为缺失值,为缺失值返回True,否则返回False
s.isnull()聊聊Nan 和 null None 和空字符串 " " 的 区别 :
None : 表示 空无一物 ,啥也没存储
空就是空,它不是整型,不是浮点型,也不是字符串,就是一个NoneType。所以在使用len(None)时候会报错,因为NoneType没有字符串才有的方法。
Null: 表示空无一物,啥也没有存储。
-
数据库中才使用Null
-
在数据库查询时Null就等同于python中的None
空字符串" ": 有存储个东西,是空字符串,空字符串有哪些特征呢?
-
长度为0
-
类型为string 以下是在python中验证了空字符串的特点。
NaN: 一般叫做pandas的缺失值 和None 基本差不多
区别
-
nan可以运算
-
None不可以做运算
-
进行引入
dic = {
'语文':100,
'数学':' ',
'理综':None,
'英语': np.nan
}
s = pd.Series(data=dic)
s.isnull() #用于判断每一个元素是否为缺失值,为null返回True,否则返回False
append方法进行拼接
obj = pd.Series([1,234,4,55,6,777])
seris_obj = pd.Series([31,34]) # 特别注意:此处得是series类型
obj.append(seris_obj)0 1 1 234 2 4 3 55 4 6 5 777 0 31 1 34 dtype: int64
obj = pd.Series([1,234,4,55,6,777])
seris_obj = pd.Series([31,34])
# 进行索引的重新排序
obj.append(seris_obj).reset_index(drop = True) # 特别注意 drop= True
删除元素
通过索引的值来删除
obj = pd.Series([1,234,4],index = ['a','b','c']) #类型是 字符串或者int
obj.drop('a',inplace = True) # 删除的是索引 inplace = True 对原对象进行修改 或者赋值
obj排序
sort_index默认是升序的,此时参数不用填写
sort_values
obj = pd.Series([1,234,4],index = [123,22,33])
obj.sort_index(ascending = False) # 默认是升序, False为降序
obj = pd.Series([1,234,4])
obj.sort_values(ascending = False)统计方法
min max median mean, describe
obj = pd.Series([1,234,np.nan])
>>>obj.describe()count 2.00000 mean 117.50000 std 164.75588 min 1.00000 25% 59.25000 50% 117.50000 75% 175.75000 max 234.00000 dtype: float64
读取excel文件
pandas 提供了 read_excel 函数来读取“xls”“xlsx”两种 Excel 文件,如果是csv文件就用read_csv方法进行读取.
import pandas as pd
df = pd.read_excel('./豆瓣电影数据.xlsx') # read_excel方法进行读取excel文件
df.head() # 默认取前五行
# 属性
print(type(df['年代'])) # 查看 数据类型
df['年代'].index # 查看series的索引属性
df['年代'].values # 查看 series的 值
df['年代'].size # 查看个数
df['年代'].shape # 查看形状
df['年代'].dtype # 查看里面元素的类型
# 方法
df['年代'].to_dict()[1]
df['年代'].tolist()
df['年代'].isnull()
df['年代'].head(10)
df_new = df['年代'].head(10).drop(7) #删除 索引为7 的数据
df_new.sort_index(ascending= False) # 降序排列
df_new.append(pd.Series([1999])).reset_index(drop = True)
# 计算
df_new.count() # 计算行数
df_new.min() # 最小值
df_new.max() # 最大值