Yolo-v1~v3学习关键点整理
虽然目前也出了ssd更好用的模型,但是yolo的性能依然非常突出,在日常中也使用的相当之多,这里希望能够对yolo相关内容做一个整理。本文参考和转载较多木盏1大大的内容,从v1-v3,这位大大也有非常详细的描述,在此引上2’3’4。
Yolo简介
yolo的发展从v1-v3,发生了很多本质上的变化,许多特性,对于模型当前的结果都起到了关键作用:
- leaky ReLU5,相比普通ReLU,leaky让负数不直接为0,而是乘以一个很小的系数(恒定),保留负数输出,衰减负数输出;公式如下:
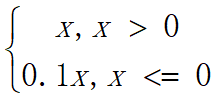
- 分而治之,用网格划分图片区域,每块区域独立检测目标;
- 端到端训练。损失函数的反向传播贯穿整个网络。
- 用BN层作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每层卷积层后面。
- 多尺度训练。在速度和准确率间折中。更高速度,准确率略低;更高准确率,速度略低。
- 底层分类网络darknet-53性能更强,tiny darknet轻量高速。
Yolo v1
论文标题: 《You Only Look Once: Unified, Real-Time Object Detection》
论文地址:https://arxiv.org/pdf/1506.02640.pdf
在yolo_v1上,输入图片被划分为7x7个单元格,各网格用于根据物体中心点位置分类,不对图片切片基于整体进行独立检测。 b-box的(x,y,w,h,class)都是卷积网络预测得到。
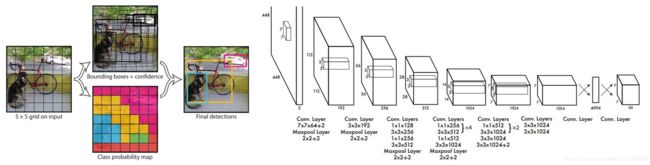
v1输出为7x7x30张量,7x7表示把输入图片划分成7x7网格,每个网格的维度为30=(2*5+20),意味着每个单元格只能预测两个框(而且只认识20类物体),对于密集型目标检测和小物体检测不能很好适用。(最多只能预测49x2=98框)
![]()
SxS表示网格数量,B表示每个网格生成框的个数,5表示预测参数数量(x,y,w,h,score),C表示能检测识别的种类。
端到端训练,yolo_v1是一种端到端训练,输入图像,基于损失函数训练权重,进而预测图像中的预测框的位置、大小、种类、置信度(score)等信息。
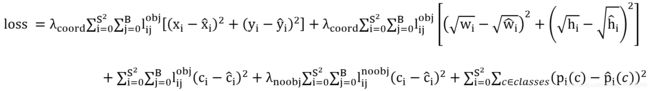
用总方误差( sum-squared error)求预测像素坐标的损失,根号总方误差求宽、高损失,对置信度confidence和分类也用SSE作为损失函数。累加得到yolo v1损失函数。lijobj取值{0,1},即目标有无;λcoord=5;λnoobj=0.5;
v1相比v2、v3,继承特点:
- 全面使用leakyReLU,f=max(0.01x,x)
- 分而治之,网格划分图片区域,每块区域独立检测目标;
- 端到端训练。损失函数的反向传播贯穿整个网络。
Yolo v2
论文标题:《YOLO9000: Better, Faster, Stronger》
论文地址: https://arxiv.org/pdf/1612.08242v1.pdf
实际效果:yolo_v2在VOC2007数据集mAP=76.8,帧数67(fast yolo);mAP=78.6,40Hz(yolo),适应多种场景需求。
v2相比v1的Improve:
1.增设BN层:BN加速收敛,作为一种正则手段减少对其他形式正则化的必要,在每层卷积层后加BN,mAP+=2%.
2.高分辨率分类器:使用基于ImageNet预训练分类器,提升输入尺寸为448*448,分类网络(DarkNet-19)filter在高分辨率输入下表现更好,mAP+=4%。
3.参考anchor机制:加入anchor机制(若干预设框图)。去除全连接层直接预测b-box坐标做法,参考FasterR-CNN,用RPN全连接预测每个box预测offset(坐标偏移量)及置信度。——去除一层池化,把448x448图像收缩到416x416,使输出特征图维度为奇数,产生中间单元格(centercell),单独中心单元格可以更好预测物体。YOLO的卷积层下采样系数为32,输出featuremap为13x13(416/32=13)。
Without anchor 69.5mAP 81%recall // With anchor 69.2mAP 88%recall
ps.mAP稍微下降,但是召回率提升意味模型有更多提升的空间,预测框数量从98个/张图变为超过1000个/张图。
///
使用anchor困难1,prior需要手动设定,使用K-means聚类得到,聚类距离函数d=1-IOU(box,centroid);如果用欧式距离,不同尺寸误差会有影响,我们想要的是能使IOU得分更高的优选项,与box的大小没有关系;通过对k-means算法多次取k值,最终在模型复杂度和高召回率间权衡取k=5。
使用anchor困难2,使用anchor机制,模型定位不稳定,主要原因为box在RPN中,采用如下计算式预测tx,ty以及(x,y)坐标,anchor box可以偏移到图像任意位置,且随机初始化权重后需要很长时间才能产生可靠offsets(偏移量)。
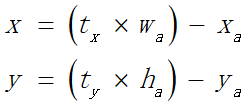

采用直接预测对于网格单元的相对位置,类似yolo_v1做法,不过v2是预测相对位置,相对单元格的左上角坐标。bbox的宽和高是同时确定的,不是通过regression得到。
pw、ph是k-means聚类后的prior(模板框)的宽和高,yolo预测偏移量tw和th,相当于直接预测bbox的宽和高,使用聚类搭配直接位置预测法的操作,yolo为每个bbox预测5个参数(tx,ty,tw,th,to),mAP+=5%。
4.Fine-Grained Features:调整后的yolo在13x13特征图上做目标检测。虽然对大物体检测来说用不着这么细粒度特征图,但对小物体检测十分有帮助。Yolo增加了一个passthrough层,从26x26的分辨率得到特征。
5.multi-scale training:用多种分辨率的输入图片进行训练。
6.darknet-19:作为yolo_v2的底层分类网络,同时使用BN层加速收敛。
Yolo v3
源码:https://github.com/qqwweee/keras-yolo3 (keras);

yolo_v3作为yolo系列目前最新的算法,对之前算法既有保留又有改进。先分析一下yolo_v3上保留特性:
1:分而治之,通过划分单元格基于整体图像做单独检测,只是划分数量不同。
2:用leaky ReLU作为激活函数。
3:端到端训练,一个loss函数搞定训练,只关注输入端和输出端。
4:用BN层作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每层卷积层后面。
5:多尺度训练。在速度和准确率间折中。更高速度,准确率略低;更高准确率,速度略低。
6:底层分类网络darknet-53性能更强,tiny darknet轻量高速。
简单介绍模型结构:
DBL:就是代码中的Darknetconv2d_BN_Leaky,yolo_v3基本组件。
resn:n代表数字, res1,res2,…,res8等,表示含有多少个res unit, yolo_v3大组件,借鉴ResNet残差结构,使网络结构更深。
concat:张量拼接。concat和残差层add不同,会扩充张量维度。将darknet中间层和后面的某层上采样结果拼接。
整个yolo_v3_body包含252层,Input1层;BN和Leaky ReLU都是72层(每层BN后面接Leaky ReLU层);卷积75层,72对接BN、Leaky Relu处理特征,3层作为输出层; add 23层,用于构成res_block,每个res_unit一个add层,共有1+2+8+8+4=23层);上采样和concat都有2次。每个res_block都会用一个零填充,一共有5个res_block。
底层网络:整个v3网络,没有池化层和全连接层。前向传播中,张量尺寸变换通过改变卷积核步长实现,
ps. stride=(2,2),图像边长缩小了一半(即面积缩小到原来的1/4);v3和v2一样,将输出特征图缩小为输入1/32。
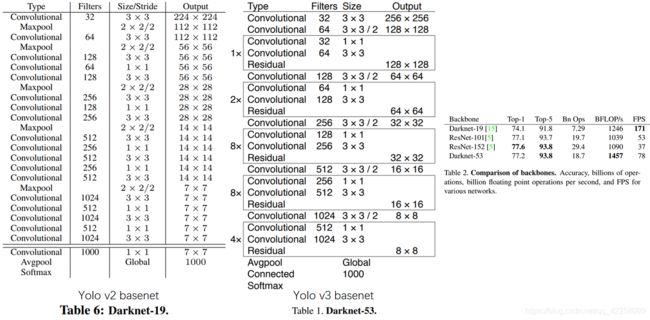
架构对比:
yolo_v2前向张量尺寸变换,通过最大池化实现,共5次;yolo_v3前向张量变化,通过卷积核增大步长实现,也是5次。
(darknet-53最后有一个全局平均池化,yolo-v3没有,张量维度变化只考虑前面那5次)
darknet-19和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53借鉴resnet,有resblock,是引入残差的backbone。
darknet-19速度占据很大优势。yolo_v3是在保证实时性基础上追求performance,从各种细节可以看出(比如b box prior采用k=9)。
细节分析:
b-box 预测。V2采用维度聚类加直接检测目标位置实现b-box预测。v3选用b-box priors的k=9(对于tiny-yolo,k=6),priors是在数据集上聚类得到的,有确定的数值,如下:每个anchor prior代表样本框的高、宽。进行b-box预测时,采用逻辑回归。v3每次对b-box预测(tx,ty,tw,th,to),再计算绝对的(x,y,w,h,c)(与v2相同)。
跨尺度预测:yolov3输出3个不同尺度的feature map,y1,y2,y3,深度都是255,边长为13:26:52,借鉴FPN(feature pyramid networks),采用多尺度对不同size目标检测,越精细grid cell可以检测越精细的物体。
yolov3设定每个网格预测3个box,每个box有5个参数(x,y,w,h,confidence)及80个类别概率,3*(5+80)=255。
v3用上采样获取多尺度feature map,前一次网络计算结果拼接后面网络层上采样(深层特征,特征信息丰富,位置信息模糊,浅层特征,特征信息少,但位置信息准确),检测效果更好。
基于逻辑回归进行目标可能性判定。逻辑回归用于对anchor包围部分进行目标性评分(objectness score),即检测目标可能性,从9个anchor priors找最优anchor,减少计算量,不是最佳anchor即使超过设定评分阈值,也不进行预测。中心坐标(tx和ty),v3每个网格关于自身位置基于sigmoid预测中心坐标,再结合w、h位移得到准确位置。
注意点:
1.9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。
2.每个输出在每个网格都有3个预测框,是作者设置的9除以3得到的数量;从输出张量的维度看13x13x255,255=3*(5+80)。80表示80个类,5表示位置信息和置信度,3表示输出3个prediction。从代码看,3*(5+80)中的3是直接由num_anchors/3得到的。
3. 预测对象类别不使用softmax,改成logistic regression进行预测输出,能支持多标签对象(比如人有Woman 和 Person两个标签)。作者使用logistic回归,对每个anchor包围的内容进行了一个目标性评分(objectness score)。基于NMS来选择最优anchor进行predict,不是所有anchor都会有输出。
4. 对比V2,V3,对于416x416的输入,在每个尺度的特征图的每个网格设置3个先验框,总共有 (132+262+522)x3x85个预测,V2只有13x13x5x(5+20)个预测,v3的预测参数量数量增加超多,其mAP及对小物体的检测有一定提升。
5.Loss函数:在目标检测任务里,有四类关键信息是需要确定的:(x,y),(w,h),class,confidence,基于各信息特点,设计损失函数,得到最终loss_function,搞定端到端训练,相比v1有不少调整,除了(w,h)的损失函数依然采用总方误差,其他部分损失函数用的是二值交叉熵,见代码。
xy_loss=object_mask*box_loss_scale*K.binary_crossentropy(raw_true_xy,raw_pred[...,0:2],from_logits=True)
wh_loss=object_mask*box_loss_scale*0.5*K.square(raw_true_wh-raw_pred[...,2:4])
confidence_loss=object_mask*K.binary_crossentropy(object_mask,raw_pred[...,4:5],from_logits=True)+(1-object_mask)*K.binary_crossentropy(object_mask,raw_pred[...,4:5],from_logits=True)*ignore_mask
class_loss=object_mask*K.binary_crossentropy(true_class_probs,raw_pred[...,5:],from_logits=True)
xy_loss=K.sum(xy_loss)/mf
wh_loss=K.sum(wh_loss)/mf
confidence_loss=K.sum(confidence_loss)/mf
class_loss=K.sum(class_loss)/mf
loss+=xy_loss+wh_loss+confidence_loss+class_loss
https://blog.csdn.net/leviopku ↩︎
https://blog.csdn.net/leviopku/article/details/82588059 ↩︎
https://blog.csdn.net/leviopku/article/details/82588959 ↩︎
https://blog.csdn.net/leviopku/article/details/82660381 ↩︎
f=max(0.01x,x)不饱和,计算高效,收敛快,不失活,但非中心对称。详见https://blog.csdn.net/u013146742/article/details/51986575;https://blog.csdn.net/kangyi411/article/details/78969642 ↩︎