单阶经典检测器: YOLO (You Only Look Once)
目录
- 无锚框预测:YOLOv1
-
- 网络结构
- 特征图的意义
- 损失计算
- 总结
- 依赖锚框:YOLOv2
-
- 网络结构的改善 - DarkNet-19
- 先验框的设计
- 正、负样本与损失函数
- 训练技巧
- 不足
- 多尺度与特征融合:YOLOv3
-
- 改进网络结构: DarkNet-53
- 多尺度预测
- Softmax 改为 Logistic
- YOLOv3 SPP
-
- Mosaic 图像增强
- SPP 模块 (Spatial Pyramid Pooling)
- CIOU loss
-
- IoU loss
- GIoU loss (Generalized IoU)
- DIoU loss (Distance IoU)
- CIoU loss (Complete IoU)
- Focal loss
- YOLOv4
-
- Backbone: CSP-Darknet53
- Neck: SPP + PAN
- YOLOv4 网络结构
- 优化策略
-
- Eliminate grid sensitivity
- Mosaic 图像增强
- IoU threshold (match positive samples)
- Optimizered Anchors
- CIOU (Complete IoU)
- YOLOv5 (v6.1)
-
- Backbone: New CSP-Darknet53
- Neck: SPPF + New CSP-PAN
- YOLOv5 网络结构
- 数据增强
- 训练策略
- 其他
-
- 损失计算
- 预测框偏移值计算
- 匹配正样本 (Build Targets)
- 参考文献
- Faster RCNN 利用了两阶结构,先实现感兴趣区域的生成,再进行精细的分类与回归,虽出色地完成了物体检测任务,但也限制了其速度
- 在此背景下,YOLO v1 利用回归的思想,使用一阶网络直接完成了分类与位置定位两个任务,速度极快。随后出现的 YOLO v2 与 v3 在检测精度与速度上有了进一步的提升,加速了物体检测在工业界的应用,开辟了物体检测算法的另一片天地
无锚框预测:YOLOv1
- paper: Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
网络结构
- YOLO v1 输入图像的尺寸固定为 3 × 448 × 448 3\times448×448 3×448×448,经过 24 个卷积层与两个全连接层后,最后输出的特征图大小为 30 × 7 × 7 30×7×7 30×7×7
 其中最后的两个 Conn. Layer 指全连接层,第一个全连接层将 1024 × 7 × 7 1024\times7\times7 1024×7×7 的特征图展平之后输出 4096- d d d 的向量,第二个全连接层输出 1470- d d d 的向量,之后 reshape 为 30 × 7 × 7 30\times 7 \times7 30×7×7 的输出特征图
其中最后的两个 Conn. Layer 指全连接层,第一个全连接层将 1024 × 7 × 7 1024\times7\times7 1024×7×7 的特征图展平之后输出 4096- d d d 的向量,第二个全连接层输出 1470- d d d 的向量,之后 reshape 为 30 × 7 × 7 30\times 7 \times7 30×7×7 的输出特征图 - 关于 YOLO v1 的网络结构,有以下 3 个细节:(1) 在 3 × 3 3×3 3×3 的卷积后通常会接一个通道数更低的 1 × 1 1×1 1×1 卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力; (2) 除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU; (3) 在训练中使用了 Dropout 与数据增强的方法来防止过拟合
网络在 ImageNet 上使用 224 × 224 224\times224 224×224 的图像分类任务进行预训练,检测任务则是在 448 × 448 448\times448 448×448 的分辨率上进行 (事实上,这种训练方式也是有问题的,会带来 domain shift,这点在 YOLO v2 中就得到了改进)
特征图的意义
- YOLO v1 将输入图像划分成 7 × 7 7×7 7×7 的区域,在每一个区域内预测两个边框,这样整个图上一共预测 7 × 7 × 2 = 98 7×7×2=98 7×7×2=98 个框。这些边框大小与位置各不相同,基本可以覆盖整个图上可能出现的物体
 (如果一个物体的中心点落在了某个区域内,则该区域就负责检测该物体,具体是将该区域的两个框与真实物体框进行匹配,IoU 更大的框负责回归该真实物体框)
(如果一个物体的中心点落在了某个区域内,则该区域就负责检测该物体,具体是将该区域的两个框与真实物体框进行匹配,IoU 更大的框负责回归该真实物体框) - 输出的特征图大小为 7 × 7 × 30 7×7×30 7×7×30,每个区域对应通道数为 30,代表了预测的 30 个特征。预测特征由类别概率、边框置信度及边框位置组成
- (1) 类别概率:由于 PASCAL VOC 数据集一共有 20 个物体类别,因此这里预测的是边框属于哪一个类别,即 Pr ( Class i ∣ Object ) \text{Pr}(\text{Class}_{i}|\text{Object}) Pr(Classi∣Object)
- (2) 置信度: Pr ( Object ) × IoU p r e d t r u t h \boldsymbol{\text{Pr}(\text{Object})\times \text{IoU}_{pred}^{truth}} Pr(Object)×IoUpredtruth,其中 IoU p r e d t r u t h \text{IoU}_{pred}^{truth} IoUpredtruth 为预测框与 GT 框的 IoU, Pr ( Object ) \text{Pr}(\text{Object}) Pr(Object) 为该区域包含物体的概率。因此,如果区域内包含物体,则置信度真值为 IoU p r e d t r u t h \text{IoU}_{pred}^{truth} IoUpredtruth
- (3) 边框位置 ( x , y , w , h ) (x,y,w,h) (x,y,w,h):对每一个边框需要预测其中心坐标及宽、高这 4 个量,两个边框共计 8 个预测值。其中 x , y x,y x,y 指预测框中心点相对于区域边界的相对偏移量, w , h w,h w,h 值相对于图片大小的相对大小,因此 x , y , w , h x,y,w,h x,y,w,h 均在 0 到 1 之间

类别概率 × \times × 置信度 = Pr ( Class i ∣ Object ) × Pr ( Object ) × IoU p r e d t r u t h = Pr ( Class i ) × IoU p r e d t r u t h \text{Pr}(\text{Class}_{i}|\text{Object})\times\text{Pr}(\text{Object})\times \text{IoU}_{pred}^{truth}=\text{Pr}(\text{Class}_{i})\times \text{IoU}_{pred}^{truth} Pr(Classi∣Object)×Pr(Object)×IoUpredtruth=Pr(Classi)×IoUpredtruth
这里有以下 3 点值得注意的细节:
- YOLO v1 并没有先验框,而是直接在每个区域预测框的大小与位置,是一个回归问题。这样做能够成功检测的原因在于,区域本身就包含了一定的位置信息,另外被检测物体的尺度在一个可以回归的范围内
- 一个区域内的两个边框共用一个类别预测,在训练时会选取与物体 IoU 更大的一个边框,在测试时会选取置信度更高的一个边框,另一个会被舍弃,因此整张图最多检测出 49 个物体
- YOLO v1 采用了物体类别与置信度分开的预测方法,这点与 Faster RCNN 不同。Faster RCNN 将背景也当做了一个类别,共计 21 种,在类别预测中包含了置信度的预测
损失计算
在计算损失时,需要按如下方法确定每一个边框是对应着真实物体还是背景框,即区分正、负样本:
- 当一个真实物体的中心点落在了某个区域内时,该区域就负责检测该物体。具体做法是将与该真实物体有最大 IoU 的边框设为正样本,这个区域的类别真值为该真实物体的类别,该边框的置信度真值为预测框与 GT 框的 IoU
- 除了上述被赋予正样本的边框,其余边框都为负样本。负样本没有类别损失与边框位置损失,只有置信度损失,其真值为 0
损失函数 (sum-squared error)
L o s s = λ coord ∑ i = 0 s 2 ∑ j = 0 B 1 i j obj ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 + λ coord ∑ i = 0 s 2 ∑ j = 0 B 1 i j obj ( ω i − ω ^ i ) 2 + ( h i − h ^ i ) 2 + ∑ i = 0 s 2 ∑ j = 0 B 1 i j obj ( C i − C ^ i ) 2 + λ noobi ∑ i = 0 s 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 + ∑ i = 0 s 2 1 i j obj ∑ c ∈ classes ( p i ( c ) − p ^ i ( c ) ) 2 \begin{aligned} Loss&=\lambda_{\text {coord }} \sum_{i=0}^{s^{2}} \sum_{j=0}^{B} 1_{i j}^{\text {obj }}\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2} \\ &+\lambda_{\text {coord }} \sum_{i=0}^{s^{2}} \sum_{j=0}^{B} 1_{i j}^{\text {obj }}\left(\sqrt{\omega_{i}}-\sqrt{\hat{\omega}_{i}}\right)^{2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right)^{2} \\ &+\sum_{i=0}^{s^{2}} \sum_{j=0}^{B} 1_{i j}^{\text {obj }}\left(C_{i}-\hat{C}_{i}\right)^{2} +\lambda_{\text {noobi }} \sum_{i=0}^{s^{2}} \sum_{j=0}^{B} 1_{i j}^{\text {noobj }}\left(C_{i}-\hat{C}_{i}\right)^{2} \\ &+\sum_{i=0}^{s^{2}} 1_{i j}^{\text {obj }} \sum_{c\in\text { classes }}\left(p_{i}(c)-\hat{p}_{i}(c)\right)^{2} \end{aligned} Loss=λcoord i=0∑s2j=0∑B1ijobj (xi−x^i)2+(yi−y^i)2+λcoord i=0∑s2j=0∑B1ijobj (ωi−ω^i)2+(hi−h^i)2+i=0∑s2j=0∑B1ijobj (Ci−C^i)2+λnoobi i=0∑s2j=0∑B1ijnoobj (Ci−C^i)2+i=0∑s21ijobj c∈ classes ∑(pi(c)−p^i(c))2
- 其中, i i i 代表第几个区域,一共有 S 2 S^2 S2 个区域,在此为 49; j j j 代表某个区域的第几个预测边框,一共有 B B B 个预测框,在此为 2; obj \text{obj} obj 代表该框对应了真实物体; noobj \text{noobj} noobj 代表该框没有对应真实物体。这 5 项损失的意义如下:
- (1) 第一项为正样本中心点坐标的损失。 λ coord \lambda_{\text {coord }} λcoord 的目的是为了调节位置损失的权重,YOLO v1 设置 λ coord \lambda_{\text {coord }} λcoord 为 5
- (2) 第二项为正样本宽高的损失。由于宽高差值受物体尺度的影响,因此这里先对宽高进行了平方根处理,在一定程度上降低对尺度的敏感,强化了小物体的损失权重
- (3) (4) 第三、四项分别为正样本与负样本的置信度损失。 λ noobj λ_{\text{noobj}} λnoobj 默认为 0.5,目的是调低负样本置信度损失的权重
- (5) 最后一项为正样本的类别损失
总结
- YOLO v1 利用了回归的思想,使用轻量化的一阶网络同时完成了物体的定位与分类,处理速度极快,可以达到 45 FPS,当使用更轻量的网络时甚至可以达到 155 FPS。得益于其出色的处理速度,YOLO v1 被广泛应用在实际的工业场景中,尤其是追求实时处理的场景
- 当然,YOLO v1也有一些不足之处,主要有如下 3 点:
- 由于每一个区域默认只有两个边框做预测,并且只有一个类别,因此 YOLO v1 有着天然的检测限制。这种限制会导致模型对于小物体,以及靠得特别近的物体检测效果不好
- 由于没有类似于 Anchor 的先验框,模型对于新的或者不常见宽高比例的物体检测效果不好。另外,由于下采样率较大,边框的检测精度不高
- 在损失函数中,大物体的位置损失权重与小物体的位置损失权重是一样的,这会导致同等比例的位置误差,大物体的损失会比小物体大,小物体的损失在总损失中占比较小,会带来物体定位的不准确
依赖锚框:YOLOv2
- paper: Redmon, Joseph, and Ali Farhadi. “YOLO9000: better, faster, stronger.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- 针对 YOLO v1 的不足,2016 年诞生了 YOLO v2。相比起第一个版本,YOLO v2 预测更加精准(Better)、速度更快(Faster)、识别的物体类别也更多(Stronger),在 VOC 2007 数据集上可以得到 mAP 10% 以上的提升效果

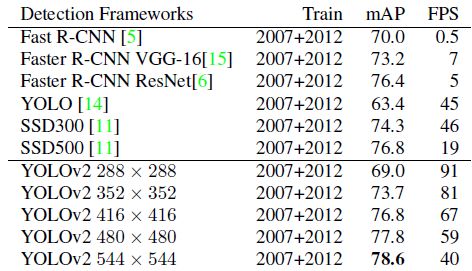
YOLOv2 之后有不同的分辨率是因为 YOLOv2 的网络结构移除了全连接层,可以接受任意尺寸的输入图像 (当然尺寸需为 DarkNet 下采样率 32 的整数倍),并且在训练时采用了多尺度训练
网络结构的改善 - DarkNet-19
- DarkNet-19 拥有 19 个卷积层与 5 个池化层,在增加了一个 Passthrough 层后一共拥有 22 个卷积层,精度与 VGGNet 相当,但浮点运算量只有 VGGNet 的 1/5 左右,因此速度极快

注意,上图中最后一个卷积层 Conv2d 并不包含 BN 和 LeakyReLU,它只是一个单一的卷积层
- 相比起 v1 版本的基础网络,DarkNet 进行了以下几点改进:
- (1) BN 层:DarkNet 在每一个卷积之后,激活函数 LeakyReLU 之前使用了 BN 层. 这个改进带来了 2% 的 mAP 提升。同时,由于 BN 也有一定的正则化效果,YOLOv2 还去掉了 YOLOv1 中的 dropout
- (2)·用连续 3 × 3 3×3 3×3 卷积替代了 v1 版本中的 7 × 7 7×7 7×7 卷积,这样既减少了计算量,又增加了网络深度。此外,DarkNet 去掉了全连接层
- (3) Passthrough 层:DarkNet 还进行了深浅层特征的融合,将浅层 26 × 26 × 512 26×26×512 26×26×512 的特征变换为 13 × 13 × 2048 13×13×2048 13×13×2048,这样就可以直接与深层 13 × 13 × 1024 13×13×1024 13×13×1024 的特征进行通道拼接,这种特征融合有利于小物体的检测。具体而言,先通过 1 × 1 1\times 1 1×1 卷积层对浅层特征降维得到 26 × 26 × 64 26×26×64 26×26×64 的特征图,然后从该特征图上按步长为 2 等间隔选取特征,每一个通道的特征图可以得到 4 张大小减半的特征图 (相当于一个大小为 13,空洞数为 2 的卷积核),将它们堆叠在一起就可以得到长宽减半、通道乘 4 的特征图

- (4) YOLO v2 在每一个区域预测 5 个边框,每个边框有 25 个预测值,因此最后输出的特征图通道数为 125。其中,一个边框的 25 个预测值分别是 20 个类别预测、4 个位置预测及 1 个置信度预测值。这里与 v1 有很大区别,v1 是一个区域内的边框共享类别预测,而这里则是相互独立的类别预测值
先验框的设计
- YOLO v2 吸收了 Faster RCNN 的优点,设置了一定数量的预选框,使得模型不需要直接预测物体尺度与坐标,只需要预测先验框到真实物体的偏移,降低了预测难度
聚类提取先验框尺度
- Faster RCNN 中 Anchor 的大小与宽高是由人手工设计的,因此很难确定设计出的一组预选框是最贴合数据集的,也就有可能为模型性能带来负面影响
- 针对此问题,YOLO v2 通过在训练集上聚类来获得预选框,只需要设定预选框的数量 k k k,就可以利用聚类算法得到最适合的 k k k 个框。在聚类时,两个边框之间的距离使用下式计算,即 IoU 越大,边框距离越近
d ( b o x , c e n t r o i d ) = 1 − I o U ( b o x , c e n t r o i d ) d(box,centroid)=1-IoU(box,centroid) d(box,centroid)=1−IoU(box,centroid)在衡量一组预选框的好坏时,使用真实物体与这一组预选框的平均 IoU 作为标准,显然数量 k k k 越多,平均 IoU 会越大,效果会更好,但相应的也会带来计算量的提升,YOLO v2 在速度与精度的权衡中选择了预选框数量为 5
优化偏移公式
- 在 Faster RCNN 中,中心坐标的偏移公式如下式所示
{ x = ( t x × w a ) + x a y = ( t y × h a ) + y a \left\{\begin{array}{l} x=\left(t_{x} \times w_{a}\right)+x_{a} \\ y=\left(t_{y} \times h_{a}\right)+y_{a} \end{array}\right. {x=(tx×wa)+xay=(ty×ha)+ya其中下标 a a a 代表 Anchor 的属性 - YOLO v2 认为这种预测方式没有对预测偏移进行限制,导致预测的边框中心可以出现在图像的任何位置,尤其是在训练初始阶段,模型参数还相对不稳定。例如 t x t_x tx 是 1 与 -1 时,预测的物体中心点会有两个宽度的差距。因此,YOLO v2 提出了下面的预测公式:
{ b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h p r ( object ) × IoU ( b , object ) = σ ( t 0 ) \left\{\begin{array}{c} b_{x}=\sigma\left(t_{x}\right)+c_{x} \\ b_{y}=\sigma\left(t_{y}\right)+c_{y} \\ b_{w}=p_{w} e^{t_{w}} \\ b_{h}=p_{h} e^{t_{h}} \\ p_{r}(\text { object }) \times \operatorname{IoU}(b, \text { object })=\sigma\left(t_{0}\right) \end{array}\right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethpr( object )×IoU(b, object )=σ(t0) 上图中,实线框代表预测框,虚线框代表先验框。 c x c_x cx 与 c y c_y cy 代表中心点所处区域左上角的坐标, p w p_w pw 与 p h p_h ph 代表了当前先验框的宽高。 σ ( t x ) σ(t_x) σ(tx) 与 σ ( t y ) σ(t_y) σ(ty) 代表预测框中心点与中心点所处区域左上角坐标的距离,加上 c x c_x cx 与 c y c_y cy 即得到预测框的中心坐标。 t w t_w tw 与 t h t_h th 为预测的宽高偏移量。先验框的宽高乘上指数化后的宽高偏移量,即得到预测框的宽高。公式中的 σ σ σ 代表 Sigmoid 函数,作用是将坐标偏移量化到 ( 0 , 1 ) (0,1) (0,1) 区间,这样得到的预测边框的中心坐标 b x b_x bx、 b y b_y by 会限制在当前区域内,保证一个区域只预测中心点在该区域内的物体,有利于模型收敛。YOLO v1 将预测值 t 0 t_0 t0 作为边框的置信度,而 YOLO v2 则是将做 Sigmoid 变换后的 σ ( t 0 ) σ(t_0) σ(t0) 作为真正的置信度预测值
上图中,实线框代表预测框,虚线框代表先验框。 c x c_x cx 与 c y c_y cy 代表中心点所处区域左上角的坐标, p w p_w pw 与 p h p_h ph 代表了当前先验框的宽高。 σ ( t x ) σ(t_x) σ(tx) 与 σ ( t y ) σ(t_y) σ(ty) 代表预测框中心点与中心点所处区域左上角坐标的距离,加上 c x c_x cx 与 c y c_y cy 即得到预测框的中心坐标。 t w t_w tw 与 t h t_h th 为预测的宽高偏移量。先验框的宽高乘上指数化后的宽高偏移量,即得到预测框的宽高。公式中的 σ σ σ 代表 Sigmoid 函数,作用是将坐标偏移量化到 ( 0 , 1 ) (0,1) (0,1) 区间,这样得到的预测边框的中心坐标 b x b_x bx、 b y b_y by 会限制在当前区域内,保证一个区域只预测中心点在该区域内的物体,有利于模型收敛。YOLO v1 将预测值 t 0 t_0 t0 作为边框的置信度,而 YOLO v2 则是将做 Sigmoid 变换后的 σ ( t 0 ) σ(t_0) σ(t0) 作为真正的置信度预测值
正、负样本与损失函数
确定正、负样本
- 首先将预测的位置偏移量作用到先验框上,得到预测框的真实位置。如果一个预测框与所有真实物体的最大 IoU 小于一定阈值(默认为 0.6)时,该预测框视为负样本。每一个真实物体的中心点落在了某个区域内,该区域就负责检测该物体,将与该物体有最大 IoU 的预测框视为正样本 ( 1. 在计算正、负样本的过程中,虽然有些预测框的最大 IoU 可能小于 0.6,即被赋予了负样本,但如果后续是某一个真实物体对应的最大 IoU 的框时,该预测框会被最终赋予成正样本,以保证 recall;2. 有些预测框的最大 IoU 大于 0.6,但是在一个区域内又不是与真实物体有最大 IoU,这种预测框会被舍弃掉不参与损失计算,既不是正样本也不是负样本)
- 上面是论文中叙述的确定正负样本的方法,但如果按照上述方法确定正负样本的话会导致正样本特别少,正负样本不均衡,因此在源码实现中可以采用如下方法确定正样本:(1) 将 GT 框映射到 13 × 13 13\times13 13×13 的 Grid cell 上;(2) 每个 Grid Cell 上有 k k k 个锚框,将 GT 框分别与这 k k k 个锚框的左上顶点重合计算 IoU,如果 IoU 大于 0.3 就将该锚框看作正样本
 按照上述方法,每个 GT 框就可以对应多个正样本,这增加了训练时正样本的个数,有利于网络的训练
按照上述方法,每个 GT 框就可以对应多个正样本,这增加了训练时正样本的个数,有利于网络的训练
损失函数
Loss t = ∑ i = 0 W ∑ j = 0 H ∑ k = 0 A ( 1 max IoU < Thresh × λ noobj × ( − b i j k o ) 2 + 1 k < 12800 × λ prior × ∑ r ∈ ( x , y , w , h ) ( prior k r − b i j k r ) 2 + 1 k truth × λ coord × ∑ r ∈ ( x , y , w , h ) ( truth r − b i j k r ) 2 + 1 k truth × λ obj × ( IoU t r u t h k − b i j k o ) 2 + 1 k truth × λ class × ∑ c = 1 C ( truth c − b i j k c ) 2 ) \begin{aligned} \text { Loss }_{t} =\sum_{i=0}^{W} \sum_{j=0}^{H} \sum_{k=0}^{A}&\left(1_{\max \text { IoU }<\text { Thresh }} \times \lambda_{\text {noobj }} \times\left(-b_{i j k}^{o}\right)^{2}\right.\\ &+1_{k<12800} \times \lambda_{\text {prior }} \times \sum_{r \in(x, y, w, h)}\left(\text { prior }_{k}^{r}-b_{i j k}^{r}\right)^{2} \\ &+1_{k}^{\text {truth }} \times \lambda_{\text {coord }} \times \sum_{r \in(x, y, w, h)}\left(\text { truth }^{r}-b_{i j k}^{r}\right)^{2} \\ &+1_{k}^{\text {truth }} \times \lambda_{\text {obj }} \times\left(\text { IoU }_{\text truth}^{k}-b_{i j k}^{o}\right)^{2} \\ &\left.+1_{k}^{\text {truth }} \times \lambda_{\text {class }} \times \sum_{c=1}^{C}\left(\text { truth }^{c}-b_{i j k}^{c}\right)^{2}\right) \end{aligned} Loss t=i=0∑Wj=0∑Hk=0∑A(1max IoU < Thresh ×λnoobj ×(−bijko)2+1k<12800×λprior ×r∈(x,y,w,h)∑( prior kr−bijkr)2+1ktruth ×λcoord ×r∈(x,y,w,h)∑( truth r−bijkr)2+1ktruth ×λobj ×( IoU truthk−bijko)2+1ktruth ×λclass ×c=1∑C( truth c−bijkc)2)
- 第一项为负样本的置信度损失, b i j k o b^o_{ijk} bijko 为置信度 σ ( t o ) σ(t_o) σ(to);上面采用的是平方差损失,实际上也可以采用交叉熵损失
- 第二项为先验框与预测框的损失,只存在于前 12800 次迭代中,目的是使预测框先收敛于先验框,模型更稳定
- 第三项为正样本的位置损失
- 后两项分别为正样本的置信度损失与类别损失,这里类别损失感觉采用交叉熵损失更合理
训练技巧
多尺度训练
- 由于移除了全连接层,因此 YOLO v2 可以接受任意尺寸的输入图片。在训练阶段,为了使模型对于不同尺度的物体鲁棒,YOLO v2 采取了多种尺度的图片作为训练的输入
- 由于下采样率为 32,为了满足整除的需求,YOLO v2 选取的输入尺度集合为 { 320 , 352 , 384 , . . . , 608 } \{320,352,384,...,608\} {320,352,384,...,608},训练时每 10 个 batch 就随机选取一个分辨率进行训练,这样训练出的模型可以预测多个尺度的物体。并且,输入图片的尺度越大则精度越高,尺度越低则速度越快,因此 YOLO v2 多尺度训练出的模型可以适应多种不同的场景要求
多阶段训练
- 由于物体检测数据标注成本较高,因此大多数物体检测模型都是先利用分类数据集来训练卷积层,然后再在物体检测数据集上训练。例如,YOLO v1 先利用 ImageNet 上 224 × 224 224×224 224×224 大小的图像预训练,然后在 448 × 448 448×448 448×448 的尺度上进行物体检测的训练。这种转变使得模型要适应突变的图像尺度,增加了训练难度
- YOLO v2 针对以上问题,优化了训练过程:
- (1) 利用 DarkNet 在 ImageNet 上预训练分类任务,图像尺度为 224 × 224 224×224 224×224
- (2) 将 ImageNet 图片放大到 448 × 448 448×448 448×448 继续训练分类任务,通过微调来让模型首先适应变化的尺度
- (3) 去掉分类卷积层,在 DarkNet 上增加 Passthrough 层及 3 个卷积层,利用尺度为 448 × 448 448×448 448×448 的输入图像完成物体检测的训练

- 这种多阶段训练的方法为 YOLO v2 带来了接近 4% 的 mAP 提升
不足
- (1) 单层特征图:虽然采用了 Passthrough 层来融合浅层的特征,增强多尺度检测性能,但仅仅采用一层特征图做预测,细粒度仍然不够,对小物体等检测提升有限,并且没有使用残差这种较为简单、有效的结构
- (2) 受限于其整体结构,依然没有很好地解决小物体的检测问题
- (3) 太工程化:YOLO v2 的整体实现有较多工程化调参的过程,尤其是后续损失计算有些复杂,不是特别 “优雅”,导致后续改进与扩展空间不足
多尺度与特征融合:YOLOv3
- paper: Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018).
- YOLO v3 在保持速度优势的前提下,进一步提升了检测精度,尤其是对小物体的检测能力

改进网络结构: DarkNet-53
DarkNet-53 in image classification
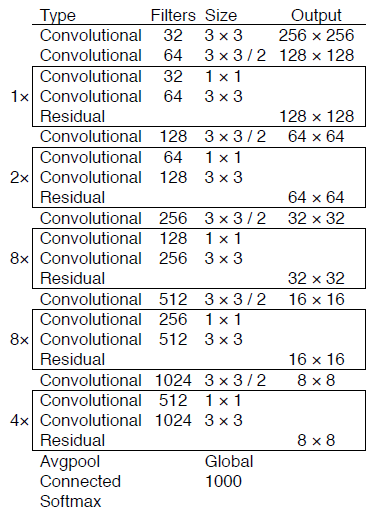
上图中的 Convolutional 代表 Conv + BN + Leaky ReLU;Residual 代表 skip connection
Comparison of backbones

DarkNet in detection

上图中的上采样采用上池化,即元素复制扩充的方法使得特征尺寸扩大,没有学习参数
DarkNet-53 结构的新特性
- (1) 残差思想
- (2) 多层特征图:通过上采样与 Concat 操作,融合了深、浅层的特征,最终输出了 3 种尺寸的特征图,用于后续预测。多层特征图对于多尺度物体及小物体检测是有利的
- (3) 无池化层:之前的 YOLO 网络有 5 个最大池化层,用来缩小特征图的尺寸,下采样率为 32,而 DarkNet-53 并没有采用池化的做法,而是通过步长为 2 的卷积核来达到缩小尺寸的效果,下采样次数同样是 5 次,总体下采样率为 32
值得注意的是,YOLO v3 的速度并没有之前的版本快,而是在保证实时性的前提下追求检测的精度。如果追求速度,YOLO v3 提供了一个更轻量化的网络 tiny-DarkNet,在模型大小与速度上,实现了 SOTA
多尺度预测
- YOLO v3 输出了 3 个大小不同的特征图,从上到下分别对应深层、中层与浅层的特征。深层的特征图尺寸小,感受野大,有利于检测大尺度物体,而浅层的特征图则与之相反,更便于检测小尺度物体
- YOLO v3 依然沿用了预选框 Anchor,由于特征图数量不再是一个,因此匹配方法也要相应地进行改变。具体方法是,依然使用聚类的算法得到了 9 种不同大小宽高的先验框,然后按照下表所示的方法进行先验框的分配,这样,每一个特征图上的一个点只需要预测 3 个先验框

YOLO v3 使用的方法有别于 SSD,虽然都利用了多个特征图的信息,但 SSD 的特征是从浅到深地分别预测,没有深浅的融合,而 YOLO v3 的基础网络更像是 SSD 与 FPN 的结合
YOLO v3 默认使用了 COCO 数据集,一共有 80 个物体类别,因此一个先验框需要 80 维的类别预测值、4 个位置预测及 1 个置信度预测,3 个预测框一共需要 3 × ( 80 + 4 + 1 ) = 255 3×(80+4+1)=255 3×(80+4+1)=255 维,也就是每一个特征图的预测通道数
Softmax 改为 Logistic
- YOLO v3 的另一个改进是使用 Logistic 函数代替 Softmax 函数,以处理类别的预测得分。实验证明,Softmax 可以被多个独立的 Logistic 分类器取代,并且准确率不会下降,这样的设计可以实现物体的多标签分类,实现类别间的解耦
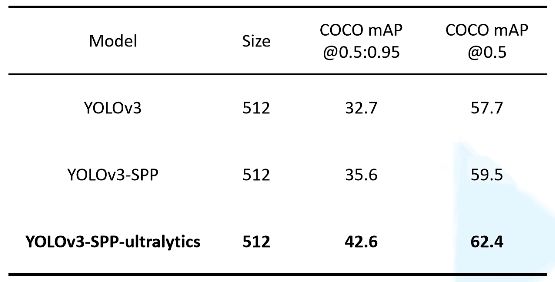
YOLOv3 SPP
Mosaic 图像增强
- Mosaic 图像增强就是将多张图片 (默认为 4) 拼接在一起输入网络进行训练,这可以增加数据多样性、增加图片中的目标个数,并使得 BN 能一次性统计多张图片的参数 (相当于 batch size × \times × 4)
SPP 模块 (Spatial Pyramid Pooling)
SPP 模块
- 如下图所示,SPP 模块由 4 条支路组成,输入在经过不同大小的池化层后按通道进行连接得到最后的输出 (当然为了使不同支路输出特征图大小相同,还需要进行适当的 padding)。SPP 模块使得模型能更好地进行不同尺度的特征融合

加入 SPP 模块后,DarkNet 结构如下:

实验证明,在第二个和第三个输出层前也以类似的方法加上 SPP 模块也可以进一步提升 mAP,不过提升幅度没有那么大
CIOU loss
IoU loss
- 在 YOLOv3 中,正样本的位置损失采用的是 L2 损失,但 L2 损失并不能很好地反映预测框与 GT 框的重合程度 (IoU):

- 为此,可以使用 IoU loss 来直接最大化预测框与 GT 框的 IoU:
L IoU = − ln IoU L_{\text{IoU}}=-\ln \text{IoU} LIoU=−lnIoU也可以采用
L IoU = 1 − IoU L_{\text{IoU}}=1- \text{IoU} LIoU=1−IoUIoU loss 相比 L2 loss 能够更好的反应重合程度,并且具有尺度不变性。但 IoU loss 也有一个很明显的缺陷,就是当预测框和 GT 框不相交时 IoU 恒为 0,IoU 对预测框位置的偏导也为 0,此时就很难通过梯度对预测框位置进行优化使得 IoU 增加
GIoU loss (Generalized IoU)
- Generalized IoU (GIoU):当两个边框不相交时,GIoU 也不恒为一个常量,而是能衡量出不相交的程度:
GIoU = IoU + u A c − 1 ∈ ( − 1 , 1 ] \text{GIoU}=\text{IoU}+\frac{u}{A^c}-1\in(-1,1] GIoU=IoU+Acu−1∈(−1,1]其中, u u u 为预测框和 GT 框的并集面积, A c A^c Ac 为能够同时覆盖预测框和 GT 框的最小矩形面积 (淡蓝框面积)

- GIoU loss
L GIoU = 1 − GIoU ∈ [ 0 , 2 ) L_{\text{GIoU}}=1-\text{GIoU}\in[0,2) LGIoU=1−GIoU∈[0,2)
DIoU loss (Distance IoU)
- Distance IoU: 在下图所示情况中,IoU 和 GIoU 都无法衡量出预测框和 GT 框的重合程度
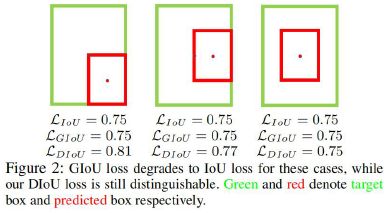 相比之下,DIoU 能够更精准地反映出两个边框的重合程度:
相比之下,DIoU 能够更精准地反映出两个边框的重合程度:
DIoU = IoU − d 2 c 2 ∈ ( − 1 , 1 ] \text{DIoU}=\text{IoU}-\frac{d^2}{c^2}\in(-1,1] DIoU=IoU−c2d2∈(−1,1]其中, d d d 为预测框和 GT 框中心点之间的距离, c c c 为能够同时覆盖预测框和 GT 框的最小矩形的对角线长度

- DIoU loss: DIoU loss 相比 IoU loss 和 GIoU loss 能够直接最小化两个边框之间的距离,因此收敛速度更快,并且能够达到更高的定位精度
L DIoU = 1 − DIoU ∈ [ 0 , 2 ) L_{\text{DIoU}}=1-\text{DIoU}\in[0,2) LDIoU=1−DIoU∈[0,2)
CIoU loss (Complete IoU)
- Complete IoU: 一个优秀的回归定位损失应该考虑到 3 种几何参数:重叠面积 IoU、中心点距离 c c c、长宽比,因此 CIoU 在 DIoU 的基础上增加了长宽比参数:
CIoU = IoU − ( d 2 c 2 + α v ) ∈ ( − 1 , 1 ] \text{CIoU}=\text{IoU}-\left(\frac{d^2}{c^2}+\alpha v\right)\in(-1,1] CIoU=IoU−(c2d2+αv)∈(−1,1]其中,
v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 α = v ( 1 − I o U ) + v v=\frac{4}{\pi^{2}}\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right)^{2}\\ \alpha=\frac{v}{(1-I o U)+v} v=π24(arctanhgtwgt−arctanhw)2α=(1−IoU)+vv - CIoU loss:
L CIoU = 1 − CIoU L_{\text{CIoU}}=1-\text{CIoU} LCIoU=1−CIoU
Focal loss
- YOLOv3 采用 focal loss 时 mAP 反而降低了 2 个百分点,因此默认并没有采用 focal loss
YOLOv4
- paper: Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. “Yolov4: Optimal speed and accuracy of object detection.” arXiv preprint arXiv:2004.10934 (2020).
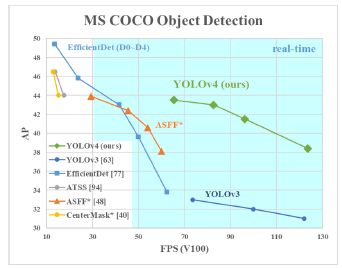
- YOLOv4 就是把当年所有的常用技术罗列了一遍,然后做了一堆消融实验,相当于在 YOLOv3 SPP 的基础上做了进一步的改进。和原始的 YOLOv3 相比效果确实有很大的提升,但和 Ultralytics 版的 YOLOv3 SPP 相比提升不大
Backbone: CSP-Darknet53
CSP 模块
- CSP 模块先使用步长为 2 的卷积层进行降采样,然后将输入分为两个支路,左路使用 1 × 1 1\times1 1×1 卷积层将通道数变为原来的一半,右路同样先使用 1 × 1 1\times1 1×1 卷积层将通道数变为原来的一半,然后接两个 ResBlock,再使用 1 × 1 1\times1 1×1 卷积层输出。两个支路的输出按通道连接使得通道数翻倍,最后使用 1 × 1 1\times1 1×1 卷积层输出
 其中,Mish 激活函数为
其中,Mish 激活函数为

- 可以看到,CSP 模块通过在模块内部将输入特征图大小减半、通道数减半大大降低了计算复杂度和内存开销,同时精心设计的网络结构也有不错的学习能力
CSPDarknet-53
- CSPDarknet-53 其实就是若干个 CSP 模块的串联。除了第一个 DownSample 模块结构与上面的 CSP 模块略有不同之外 (e.g. 两个支路的第一个 1 × 1 1\times1 1×1 卷积层并没有将通道数减半),其余的 DownSample 模块均与 CSP 模块结构相同

Neck: SPP + PAN
- Backbone CSPDarkNet-53 之后生成 3 种不同分辨率特征图的网络结构可以被称为 neck 部分

SPP 模块 (Spatial Pyramid Pooling)
- 类似 YOLOv3-SPP,YOLOv4 在 neck 部分采用了 SPP 模块用于加强不同尺度的特征融合
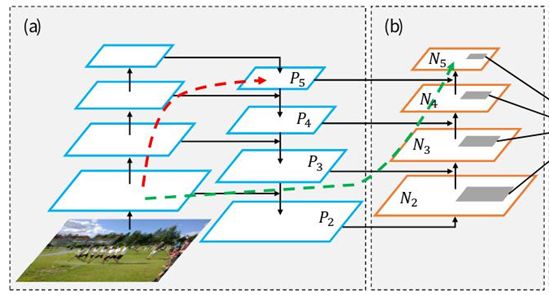
PAN 模块 (Path Aggregation Network)
- PAN 的主要思想是在 FPN (蓝色) 的基础上再增加由浅层向深层融合信息的模块
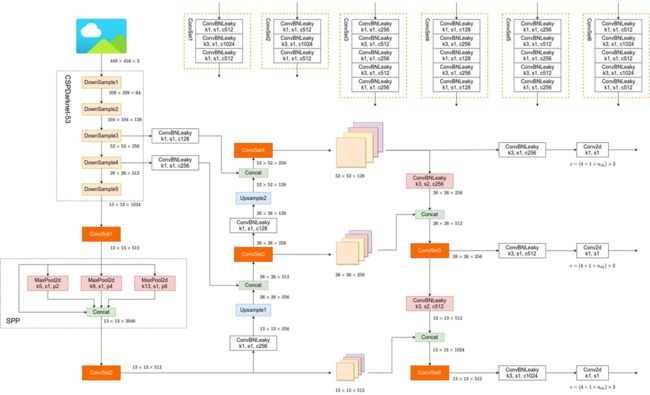
YOLOv4 网络结构
优化策略
Eliminate grid sensitivity
- YOLOv2 和 YOLOv3 都是采用如下方式计算预测框的中心点坐标:
这样虽然能将中心坐标限制在网格内,有利于网络收敛,但也给模型带来了网格敏感度。比如当真实目标中心点非常靠近网格的左上角或右下角点时,如果要输出正确的中心点坐标,就必须使得 σ ( t x ) \sigma(t_x) σ(tx) 和 σ ( t y ) σ ( t_y ) σ(ty) 为 0 或 1,也就是网络预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到 - 为了解决这个问题,作者引入了一个大于 1 的缩放系数 ( s c a l e x y {\rm scale}_{xy} scalexy):
b x = ( σ ( t x ) ⋅ scale x y − scale x y − 1 2 ) + c x b y = ( σ ( t y ) ⋅ scale x y − scale x y − 1 2 ) + c y \begin{aligned} &b_{x}=\left(\sigma\left(t_{x}\right) \cdot \text { scale }_{x y}-\frac{\text { scale }_{x y}-1}{2}\right)+c_{x} \\ &b_{y}=\left(\sigma\left(t_{y}\right) \cdot \text { scale }_{x y}-\frac{\text { scale }_{x y}-1}{2}\right)+c_{y} \end{aligned} bx=(σ(tx)⋅ scale xy−2 scale xy−1)+cxby=(σ(ty)⋅ scale xy−2 scale xy−1)+cy通过引入这个系数,网络的预测值能够很容易达到 0 或者 1,现在比较新的实现方法包括 YOLOv5 都将 s c a l e x y {\rm scale}_{xy} scalexy 设置为 2,即:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x ∈ [ − 0.5 , 1.5 ] b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y ∈ [ − 0.5 , 1.5 ] \begin{aligned} &b_{x}=\left(2 \cdot \sigma\left(t_{x}\right)-0.5\right)+c_{x}\in[-0.5,1.5] \\ &b_{y}=\left(2 \cdot \sigma\left(t_{y}\right)-0.5\right)+c_{y}\in[-0.5,1.5] \end{aligned} bx=(2⋅σ(tx)−0.5)+cx∈[−0.5,1.5]by=(2⋅σ(ty)−0.5)+cy∈[−0.5,1.5]
Mosaic 图像增强
- 类似于 YOLOv3-SPP,YOLOv4 也采用了 Mosaic 图像增强从而增加数据多样性、增加图片中的目标个数,并使得 BN 能一次性统计多张图片的参数 (相当于 batch size × \times × 4)
IoU threshold (match positive samples)
- YOLOv2 和 YOLOv3 采用如下方式确定正样本:(1) 将 GT 框映射到 k × k k\times k k×k 的 Grid cell 上;(2) 每个 Grid Cell 上有 k k k 个锚框,将 GT 框分别与这 k k k 个锚框的左上顶点重合计算 IoU,如果 IoU 大于 0.3 就将该锚框看作正样本。这种方法能够增加正样本数量,缓解正负样本不均衡的问题
- 而前面提到,YOLOv4 为了缓解网格敏感性,将中心坐标的偏移范围由 [ 0 , 1 ] [0,1] [0,1] 修改为了 [ − 0.5 , 1.5 ] [-0.5,1.5] [−0.5,1.5],因此可以利用这点来确定更多的正样本。例如在下图中,GT 框的中心点位于网格的左上方,因此对于该网格的左侧和上方网格而言,偏移量在 [ − 0.5 , 1.5 ] [-0.5,1.5] [−0.5,1.5] 的区间内,因此也将左侧和上方网格的 AT 2 设为正样本,这样就一共确定了 3 个正样本 (在源码实现中,就是只多确定上下左右四个方向的网格中的正样本,忽略斜上方和斜下方的网格)
 其他情况可以参考下图,其中当中心点坐标正好在网格中心时,并不会再去确定其他网格中的正样本,这是因为此时偏移量达到了极限值 -0.5 和 1.5,网络很难输出正确的位置偏移量
其他情况可以参考下图,其中当中心点坐标正好在网格中心时,并不会再去确定其他网格中的正样本,这是因为此时偏移量达到了极限值 -0.5 和 1.5,网络很难输出正确的位置偏移量

Optimizered Anchors
- YOLOv4 加入了 512 × 512 512\times512 512×512 分辨率的训练样本重新做了锚框聚类,得到了 9 种新的锚框 (但 YOLOv5 仍然采用的是 YOLOv3 中的 9 种锚框尺寸)

CIOU (Complete IoU)
- YOLOv4 和 YOLOv3-SPP 一样,在计算回归损失时使用 CIOU 而非平方损失:
CIoU = IoU − ( d 2 c 2 + α v ) ∈ ( − 1 , 1 ] \text{CIoU}=\text{IoU}-\left(\frac{d^2}{c^2}+\alpha v\right)\in(-1,1] CIoU=IoU−(c2d2+αv)∈(−1,1]其中,
v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 α = v ( 1 − I o U ) + v v=\frac{4}{\pi^{2}}\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right)^{2}\\ \alpha=\frac{v}{(1-I o U)+v} v=π24(arctanhgtwgt−arctanhw)2α=(1−IoU)+vv - CIoU loss:
L CIoU = 1 − CIoU L_{\text{CIoU}}=1-\text{CIoU} LCIoU=1−CIoU
YOLOv5 (v6.1)
YOLOv5 目前暂时只有 Github 仓库而没有论文发表 (~ 2022/03)

左图为 YOLOv5 的 n n n, s s s, m m m, l l l, x x x 模型 (输入分辨率为 640 × 640 640\times640 640×640,下采样率为 32 倍,输出 3 个尺度的特征图);右图为 YOLOv5 的 n 6 n6 n6, s 6 s6 s6, m 6 m6 m6, l 6 l6 l6, x 6 x6 x6 模型 (输入分辨率为 1280 × 1280 1280\times1280 1280×1280,下采样率为 64 倍,输出 4 个尺度的特征图);下面主要讲解 n n n, s s s, m m m, l l l, x x x 模型


Backbone: New CSP-Darknet53

可以看到,YOLOv5 相比 YOLOv4,在 Backbone 上并没有太大的变化
补充细节:Focus layer or Conv 6 × 6 6\times6 6×6?
- 在 YOLOv5 的 v6.0 版本之前,backbone 的第一层其实是 Focus 层,它与 YOLOv2 的 Passthrough 层类似,都使用了 space-to-depth 操作来使得特征图长宽减半、通道数翻倍,具体代码如下:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # Conv = conv2d + BN + SiLU
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
Focus(3, 64, k=3, p=1) # YOLOv5 v6.0 之前 backbone 的第一层
- 之所以设计 Focus 层是因为 YOLOv5 的作者最开始是从 YOLOv3 开始改进的,为了减少参数量和计算量,作者设计了 Focus 层来取代 YOLOv3 backbone 中最开始的 4 个卷积层
 不过,Focus 层的 space-to-depth 操作会丢失一定的空间信息 (毕竟它等价于步长为 2 的卷积),这可能会降低最终的 mAP,因此 YOLOv5 也并没有在输入层之外的地方使用 Focus 层
不过,Focus 层的 space-to-depth 操作会丢失一定的空间信息 (毕竟它等价于步长为 2 的卷积),这可能会降低最终的 mAP,因此 YOLOv5 也并没有在输入层之外的地方使用 Focus 层 - 而 issue4825 指出该 Focus 层其实就等价于一个步长为 2,padding 为 2 的 6 × 6 6\times6 6×6 卷积层,验证代码如下:
import torch
from models.common import Focus, Conv
focus = Focus(3, 64, k=3, p=1).eval()
conv = Conv(3, 64, k=6, s=2, p=2).eval()
# Express focus layer as conv layer
conv.bn = focus.conv.bn # copy BN parameters
# conv.conv.weight.shape: [64, 3, 6, 6]
# focus.conv.conv.weight.shape: [64, 12, 3, 3]
conv.conv.weight.data[:, :, ::2, ::2] = focus.conv.conv.weight.data[:, :3]
conv.conv.weight.data[:, :, 1::2, ::2] = focus.conv.conv.weight.data[:, 3:6]
conv.conv.weight.data[:, :, ::2, 1::2] = focus.conv.conv.weight.data[:, 6:9]
conv.conv.weight.data[:, :, 1::2, 1::2] = focus.conv.conv.weight.data[:, 9:12]
# Compare
x = torch.randn(16, 3, 640, 640)
with torch.no_grad():
# Results are not perfectly identical, errors up to about 1e-7 occur (probably numerical)
assert torch.allclose(focus(x), conv(x), atol=1e-6)
- 上述等价过程可由下图表示,也就是将 Focus 层中的 4 个 3 × 3 3\times3 3×3 卷积核参数整合到了 1 个 6 × 6 6\times6 6×6 卷积核中。这样的话,用 6 × 6 6\times6 6×6 卷积核以步长为 2 在输入特征图上滑动的确等价于用 4 个 3 × 3 3\times3 3×3 卷积核以步长为 1 在 space-to-depth 操作之后的输入特征图上滑动
- 可以使用如下代码比较 Focus 层和卷积层的运行速度。虽然实际运行速度受硬件及 CUDA 版本影响,但卷积层相比 Focus 层实现更简单,并且在更新的硬件条件下表现得更好
from utils.torch_utils import profile
# Profile
results = profile(input=torch.randn(16, 3, 640, 640), ops=[focus, conv, focus, conv], n=10, device=0)
YOLOv5 v5.0-434-g0dc725e torch 1.9.0+cu111 CUDA:0 (A100-SXM4-40GB, 40536.1875MB)
Params GFLOPs GPU_mem (GB) forward (ms) backward (ms) input output
7040 23.07 2.682 4.055 13.78 (16, 3, 640, 640) (16, 64, 320, 320)
7040 23.07 2.368 3.474 9.989 (16, 3, 640, 640) (16, 64, 320, 320)
7040 23.07 2.343 3.556 11.57 (16, 3, 640, 640) (16, 64, 320, 320)
7040 23.07 2.368 3.456 9.961 (16, 3, 640, 640) (16, 64, 320, 320)
Neck: SPPF + New CSP-PAN
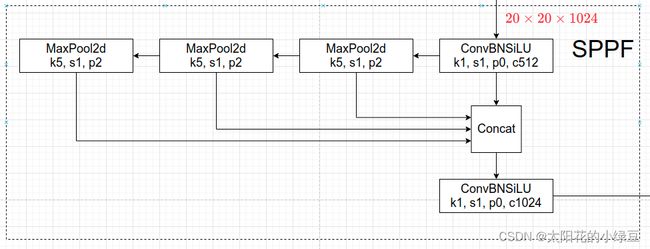
SPPF
- 可以看到,SPPF 用 3 个串行的池化层代替了原来的 3 个并行池化层来降低参数量和计算量。原因就在于 2 个 5 × 5 5\times5 5×5 池化层等价于 1 个 9 × 9 9\times9 9×9 池化层,3 个 5 × 5 5\times5 5×5 池化层等价于 1 个 13 × 13 13\times13 13×13 池化层
New CSP-PAN
- 在 YOLOv4 中,Neck 的 PAN 结构是没有引入 CSP 结构的,但在 YOLOv5 中作者在 PAN 结构中加入了 CSP,也就是 neck 部分的 C3 模块 (详见下面的网络结构图)
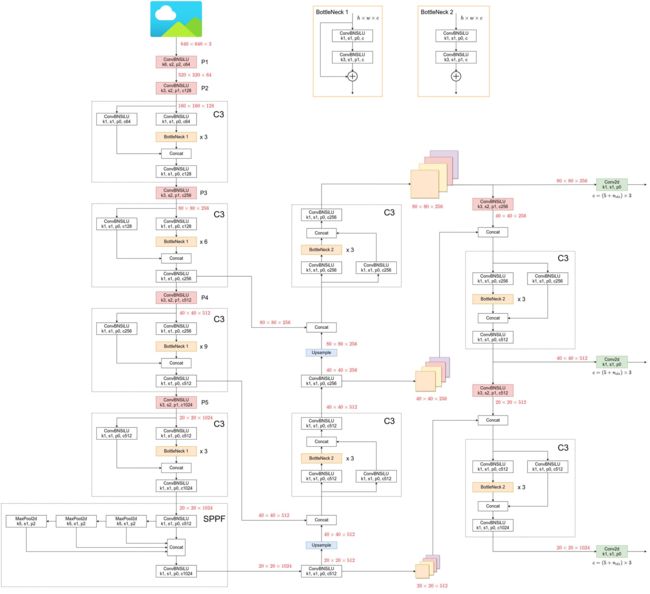
YOLOv5 网络结构
数据增强
- (1) Mosaic: 将四张图片拼成一张图片
- (2) Copy paste: 根据目标的实例分割信息,将图像中的目标抠下来随机粘贴到其他图像中

- (3) Random affine: Rotation, Scale, Translation and Shear
- (4) MixUp: 将两张图片按照一定的透明度融合在一起形成一张新的图片。代码中只有较大的模型才使用到了 MixUp,而且每次只有 10% 的概率会使用到
- (5) Albumentations: 主要是做些滤波、直方图均衡化以及改变图片质量等等,代码里写的只有安装了 albumentations 包才会启用,但在项目的 requirements.txt 文件中 albumentations 包是被注释掉了的,所以默认不启用
- (6) Augment HSV (Hue, Saturation, Value),随机调整色度,饱和度以及明度
- (7) Random horizontal flip
训练策略
- Multi-scale training (0.5~1.5x): 多尺度训练 (和 YOLOv2 类似),假设设置输入图片的大小为 640 × 640 640 × 640 640×640,训练时采用尺寸是在 0.5 × 640 ∼ 1.5 × 640 0.5 × 640 ∼ 1.5 × 640 0.5×640∼1.5×640 之间随机取值,注意取值时取得都是 32 的整数倍 (因为网络会最大下采样 32 倍)
- AutoAnchor (For training custom data): 训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成 Anchors 模板
- Warmup and Cosine LR scheduler: 训练前先进行 Warmup 热身,然后在采用 Cosine 学习率下降策略
- EMA (Exponential Moving Average): 给训练的参数加了一个动量,让它更新过程更加平滑
- Mixed precision: 混合精度训练,能够减少显存的占用并且加快训练速度,前提是 GPU 硬件支持
- Evolve hyper-parameters: 超参数优化,没有炼丹经验的人勿碰,保持默认就好
其他
损失计算
Loss = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c \text { Loss }=\lambda_{1} L_{c l s}+\lambda_{2} L_{o b j}+\lambda_{3} L_{l o c} Loss =λ1Lcls+λ2Lobj+λ3Lloc
- 其中, L c l s L_{c l s} Lcls 为正样本的分类损失 (二分类交叉熵损失 BCE); L o b j L_{o b j} Lobj 为置信度损失 (二分类交叉熵损失 BCE),真值 o b j = Pr ( Object ) × CIoU p r e d t r u t h obj=\boldsymbol{\text{Pr}(\text{Object})\times \text{CIoU}_{pred}^{truth}} obj=Pr(Object)×CIoUpredtruth; L l o c L_{l o c} Lloc 为正样本的定位损失 (CIoU loss)
平衡不同尺度的置信度损失
L o b j = 4.0 ⋅ L o b j small + 1.0 ⋅ L o b j medium + 0.4 ⋅ L o b j large L_{o b j}=4.0 \cdot L_{o b j}^{\text {small }}+1.0 \cdot L_{o b j}^{\text {medium }}+0.4 \cdot L_{o b j}^{\text {large }} Lobj=4.0⋅Lobjsmall +1.0⋅Lobjmedium +0.4⋅Lobjlarge
这里的 {4.0, 1.0, 1.0} 是针对 COCO 数据集设置的超参数
预测框偏移值计算
- 为了消除 Grid 敏感度,YOLOv4 引入了缩放因子:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x ∈ [ − 0.5 , 1.5 ] b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y ∈ [ − 0.5 , 1.5 ] \begin{aligned} &b_{x}=\left(2 \cdot \sigma\left(t_{x}\right)-0.5\right)+c_{x}\in[-0.5,1.5] \\ &b_{y}=\left(2 \cdot \sigma\left(t_{y}\right)-0.5\right)+c_{y}\in[-0.5,1.5] \end{aligned} bx=(2⋅σ(tx)−0.5)+cx∈[−0.5,1.5]by=(2⋅σ(ty)−0.5)+cy∈[−0.5,1.5] - 在 YOLOv5 中除了调整预测 Anchor 相对 Grid 网格左上角 ( c x , c y ) (c_x, c_y) (cx,cy) 偏移量以外,还调整了预测目标高宽的计算公式。之前是:
b w = p w ⋅ e t w b h = p h ⋅ e t h \begin{aligned} b_{w} &=p_{w} \cdot e^{t_{w}} \\ b_{h} &=p_{h} \cdot e^{t_{h}} \end{aligned} bwbh=pw⋅etw=ph⋅eth原来的计算公式并没有对预测目标宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题。因此在 YOLOv5 调整为如下式子:
b w = p w ⋅ ( 2 ⋅ σ ( t w ) ) 2 b h = p h ⋅ ( 2 ⋅ σ ( t h ) ) 2 \begin{aligned} b_{w} &=p_{w} \cdot\left(2 \cdot \sigma\left(t_{w}\right)\right)^{2} \\ b_{h} &=p_{h} \cdot\left(2 \cdot \sigma\left(t_{h}\right)\right)^{2} \end{aligned} bwbh=pw⋅(2⋅σ(tw))2=ph⋅(2⋅σ(th))2这样,预测框的最大宽高就为对应锚框宽高的 4 倍
匹配正样本 (Build Targets)
- YOLOv5 和 YOLOv4 匹配正样本的区别主要在于 GT Box 与 Anchor Templates 模板的匹配方式。在 YOLOv4 中是直接将每个 GT Box 与对应的 Anchor Templates 模板计算 IoU,只要 IoU 大于设定的阈值就算匹配成功。但在 YOLOv5 中,只要 GT Box 的宽高均满足在某个 Anchor Template 宽高的 0.25 0.25 0.25 倍和 4.0 4.0 4.0 倍之间就算匹配成功。具体而言,作者先去计算每个 GT Box 与对应的 Anchor Templates 模板的高宽比例,即:
r w = w g t / w a t r h = h g t / h a t \begin{aligned} r_{w} &=w_{g t} / w_{a t} \\ r_{h} &=h_{g t} / h_{a t} \end{aligned} rwrh=wgt/wat=hgt/hat然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算 GT Box 和 Anchor Templates 分别在宽度以及高度方向的最大差异 (当相等的时候比例为 1,差异最小)
r w max = max ( r w , 1 / r w ) r h max = max ( r h , 1 / r h ) \begin{aligned} r_{w}^{\max } &=\max \left(r_{w}, 1 / r_{w}\right) \\ r_{h}^{\max } &=\max \left(r_{h}, 1 / r_{h}\right) \end{aligned} rwmaxrhmax=max(rw,1/rw)=max(rh,1/rh)接着统计 r w m a x r_w^{max} rwmax 和 r h m a x r_h^{max} rhmax 之间的最大值,即宽度和高度方向差异最大的值:
r max = max ( r w max , r h max ) r^{\max }=\max \left(r_{w}^{\max }, r_{h}^{\max }\right) rmax=max(rwmax,rhmax)如果 GT Box 和对应的 Anchor Template 的 r m a x r^{max} rmax 小于阈值anchor_t(在源码中默认设置为 4.0),即 GT Box 和对应的 Anchor Template 的高、宽比例相差不算太大,则将 GT Box 分配给该 Anchor Template 模板 - 剩下的步骤和 YOLOv4 中一致,通过匹配上下左右的锚框来增加正样本个数:
参考文献
- 《深度学习之 PyTorch 物体检测实战》
- YOLO 系列理论合集 (YOLOv1~v3)
- YOLOv3-SPP-ultralytics: https://github.com/ultralytics/yolov3
- YOLOv4 网络详解: video, blog
- YOLOv5 网络详解: video, blog
- YOLOv5 官方源码仓库: https://github.com/ultralytics/yolov5 and Documentation
- yolov5 中的 Focus 模块的理解