深圳租房数据可视化分析【Plotly库绘图】
深圳租房数据可视化分析【plotly库绘图】
- 一、技术介绍
-
-
- 1、可视化技术支持来源:
- 2、选择plotly理由:
-
- 二、代码实现及分析:
-
-
- 1、导入库及解读数据集:
- 2、数据清洗与转换
- 3、统计数据
- 4、不同区域之间的租金对比
- 5、装修与租金:
- 6、楼层与租金
- 7、年份与租金:
- 8、地理位置(朝向)与租金
- 9、户型与租金:
- 10、综合比较户型、地理位置、装修,找出对于房价租金影响最大的因素
- 11、出租方式
-
- 三、项目小结与租房建议:
一、技术介绍
Python中最常用的 14 种数据可视化类型:

1、可视化技术支持来源:
- https://blog.csdn.net/weixin_40787712/article/details/122787372
- https://www.jianshu.com/p/41735ecd3f75?utm_campaign=hugo
2、选择plotly理由:
不选择matplotlib和seaborn等绘图库而选择plotly为主要绘图库的原因及plotly的介绍如下:
- matplotlib和seaborn等缺点就是画出来的图不能交互,简单来说就是matplotlib和seaborn给出的就是一个图片,当将鼠标放到图上的时候,不会显示出图中具体的数字是多少。
- 而plotly是一个可交互,基于浏览器的绘图库,主打功能是绘制在线可交互的图表,所绘制出来的图表赏心悦目,在使用plotly之后,可以将图片放大缩小,可以显示与不显示不同类别数据,等等。它所支持的语言不只是Python,还支持诸如r,matlab,javescript等语言。plotly绘制的图能直接在jupyter中查看,也能保存为离线网页,或者保存在plot.ly云端服务器内,以便在线查看。
二、代码实现及分析:
1、导入库及解读数据集:
import pandas as pd
import numpy as np
import plotly.express as px
1.1 查看头部数据得到数据集基本结构:
df = pd.read_excel("shenzhen.xls")
df.head()

1.2 查看数据集大小
df.shape
![]()
1.3 查看数据集各列的数据类型:
df.dtypes

对各列数据进行解释说明:
- name: 小区的名字
- layout:户型
- location:朝向
- size:建筑面积大小
- sizeInside:套内面积大小
- zhuangxiu:精装、豪装、普装、毛坯
- numberFloor:楼层数
- time:建成时间
- zone:区域
- position:所在区的具体位置
- money:价格
- way:出租方式(整租或者合租)
2、数据清洗与转换
2.1 查询数据集空值和缺失值
通过info()查看数据表的基本信息(维度,列名称,数据格式,所占空间等)
df.info()

通过isnull().sum()得到每一列的缺失值
df.isnull().sum()

2.2 填充缺失值
缺失值的填充有多种方法:
- 填充具体值
- 填充现有数据的某个统计值,比如均值、众数、中位数等
- 填充前后项的值等
2.2.1 size(建筑面积大小)缺失值处理:
查找size为空的数据行
size_null =df[df["size"].isnull()==True]
size_null

通过循环数据集当缺失值数据的layout相等时,将其size数据赋予缺失项
for i in range(len(df)):
print(df['layout'][i])
if df['layout'][i]=='3室2厅1卫':
print(df['size'][i])
df.iloc[91,3]=df['size'][i]
break
if df['layout'][i]=='3室2厅2卫':
print(df['size'][i])
df.iloc[193,3]=df['size'][i]
2.2.2 sizeInside (套内面积大小)缺失值处理:
df['sizeInside'].fillna(method="ffill", inplace=True)
2.2.3 zhuangxiu(装修)缺失值处理:
df["zhuangxiu"].fillna(method="ffill", inplace=True)
2.2.4 numberFloor(楼层)缺失值处理:
df["numberFloor"].fillna(method="ffill", inplace=True)
以上三项均采用向前填充法:
2.2.5 time(建成时间)缺失值处理:
对于time的处理,采用的是通过小区名在网上搜索出具体的建成时间
分别为:
- times = [“1991年建成”,“2019年建成”,“2003年建成”,“2004年建成”,“2019年建成”,“2019年建成”,“2020年建成”]
#通过对应的索引位置来填充缺失值
for i in range( len(time_null)):
df.iloc[time_null.index.tolist()[i],7] = times[i]
2.2.6 money(租金)缺失值处理:
这里采用interpolate()插值法,计算的是缺失值前一个值和后一个值的平均数。
df['money'] = df['money'].interpolate()
最后通过info再次查看数据集信息,根据信息显示,数据完整,已无缺失项
df.info()

2.3 数据转换
通过自定义的函数,传给apply(),利用split()对字段进行分割,将一些数据转换数据类型df1 = df.copy() # 防止原数据改动
def apply_size(x):
return float(x.split("面积")[1].split("㎡")[0])
def apply_sizeInside(x):
return float(x.split("面积")[1].split("㎡")[0])
def apply_numberFloor(x):
return x.split("(")[0]
def apply_time(x):
return float(x.split("年")[0])
def apply_way(x):
return x.split("|")[0]
df1[ "sizeInside"] = df1[ "sizeInside" ].apply(apply_sizeInside)
df1["size"]= df1["size"].apply(apply_size)
df1["numberFloor"] = df1["numberFloor"].apply(apply_numberFloor)
df1["time"] = df1["time"].apply(apply_time)
df1["way"] = df1["way"].apply(apply_way)
df1.tail() # 查看数据转换后的尾部数据

3、统计数据
3.1 建筑面积、套内面积、租金的均值,方差
通过agg方法里的mean求出所有数字型数据的平均值,由于上面将时间time也转换为了数字型,这里我们利用del删除time,同理方差通过var实现mean = df1.agg("mean")
del mean["time"]
mean

var = df1.agg("var")
del var["time"]
var

4、不同区域之间的租金对比
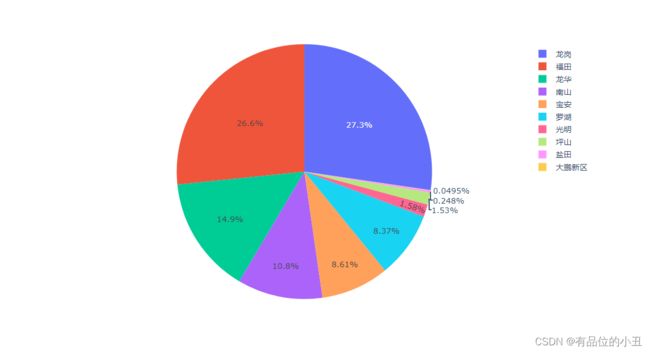
4.1 房源分布情况
zone = pd.DataFrame(df[ "zone" ].value_counts()).reset_index()
fig=px.pie(zone,names="index" ,values="zone")
fig.show()
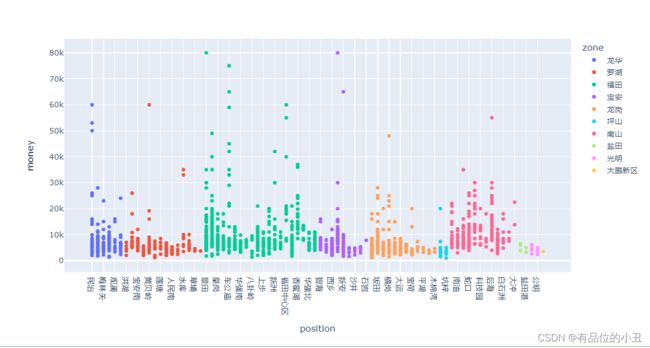
4.2 各辖区的房租分布
fig = px.scatter(df,x="position",y="money",color="zone")
fig.show()
4.3 具体位置的租金
将zone和position数据列进行合并,并计算出租金平均值df1["zone_position"]=df1["zone"] + "_" + df1["position"]
zone_position_mean=(df1.groupby("zone_position")["money"].mean().reset_index().sort_values("money",ascending=True,ignore_index=True)) # 升序排列
zone_position_mean

fig = px.scatter(zone_position_mean,x="zone_position",y="money",color="zone_position")
fig.show()

小结:
以上地区分别处在宝安商圈,罗湖CBD,福田CBD,南山CBD区域是中央商务区。是城市的功能核心,是城市经济、科技、文化的密集区,位于城市的黄金地带。集中了大量的金融、商贸、文化、服务以及大量的商务办公和酒店、公寓等设施。具有最完善的交通、通信等现代化的基础设施和良好环境,有大量的公司、金融机构、企业财团在这里开展各种商务活动。所以处于此地段的房屋租金普遍偏高。
5、装修与租金:
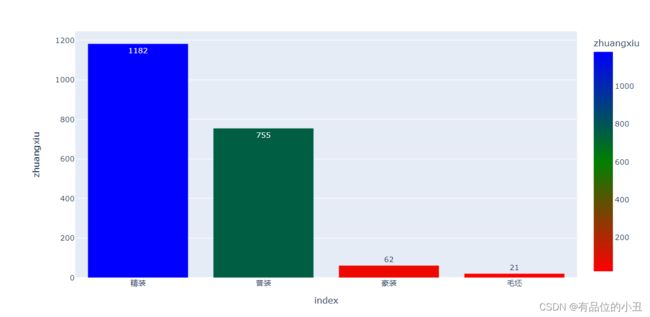
5.1 装修的情况分布
zhuangxiu = pd.DataFrame(df1["zhuangxiu"].value_counts()).reset_index()
zhuangxiu

fig = px.bar(zhuangxiu,x="index",y="zhuangxiu",text="zhuangxiu",color="zhuangxiu",color_continuous_scale=["red","green" ,"blue"])
fig.show()
装修与租金之间的关系
fig = px.scatter(df,x="zhuangxiu",y="money",color="zhuangxiu")
fig.show()

通过可视化可知,除毛坯装修之外,其他三者装修对租金影响不大
6、楼层与租金
数据处理时已将楼层转换为低,中,高三类,这里利用小提琴图,箱型图和散点将三类楼层进行可视化分析
fig = px.violin(df1,y="money",color="numberFloor", box=True, points="all")
fig.show()

通过可视化,得到低楼层租金相比于中高楼层更贵一些
7、年份与租金:
对年份进行重定义:年份=建成时间和当前年份的时间间隔
df1["time"] = df1["time"].astype("float")
df1["time"] = 2023 - df1["time"]
df1.head()

time=df1["time" ].value_counts()
fig = px.scatter(df1,x="time",y="money",color="time")
fig.show()

通过分析年份与房子租金的关系,并对数据分析进行可视化得出结论,高租金房子普遍年份在5-10年之间,刚新建的房子和随着房屋年份的增加租金也随之降低。这是由于新建房屋周围公共服务设施及公共设施不够完善,老房屋周围基础设施较为老化造成的,而在5到10年时段,小区的服务设施及公共设施达到完善,房屋的租金也随之达到高点。
8、地理位置(朝向)与租金
8.1 不同朝向下租金的价格分布
fig = px.violin(df,y="money",color="location")
fig.show()

8.2 取每个朝向的最大值/平均值进行纵向对比
price1=(df.groupby("location")["money"].max().reset_index().sort_values( "money").reset_index(drop=True))
price2=(df.groupby("location")["money"].mean().reset_index().sort_values( "money").reset_index(drop=True))
fig1=px.bar_polar(price1,theta="location",color='money',color_discrete_sequence=px.colors.sequential.Plasma_r,template='plotly_white')
fig2=px.bar_polar(price2,theta="location",color='money',color_discrete_sequence=px.colors.sequential.Plasma_r,template='plotly_white')
fig1.show()
fig2.show()


通过分析地理位置与房子租金的关系,户型朝向南北的房子,租金最贵,平均房租在10k以上;其次是朝东西向的房子,平均房租在9k-10k左右;然后租金由多而少依次是朝东南向,朝西北向,朝东向,朝西南向,平均房租在7k-8k左右。最后是朝南,朝北,朝东北的房子,平均租金在7k以下,其中朝东北的房子房租最低,在6k左右。越朝南的房子,租金越贵,越朝北的房子,租金越便宜。
9、户型与租金:
将layout分成3个具体的属性:室、厅、卫;当layout为其他时,直接删除该部分数据
在这里使用的是Pandas中的extract函数,提取出几室几厅几卫
df2 = df1["layout"].str.extract(r'(?P\d)室(?P\d)厅(?P\d)卫' )
df2.head()

# 合并到原数据
df1 = pd.concat([df2,df1],axis=1)
# 原地删除原字段layout
df1.drop("layout",axis=1,inplace=True)
df1

# 基于3个字段删除空值
df1.dropna(subset=["shi","ting","wei"],inplace=True)
# 将转换的三个字段数据都转换成类型
def apply_layout(x):
return int(x)
layout = ["shi","ting","wei"]
for i in layout:
df1[i] = df1[i].apply(lambda x: apply_layout(x))
为了更好的进行可视化分析,对三个字段赋予权重:
layout_weight=df1["shi"]*0.5+df1['ting']*0.3+df1['wei']*0.2
fig = px.scatter(df1,x=layout_weight,y="money",color=layout_weight)
fig.show()
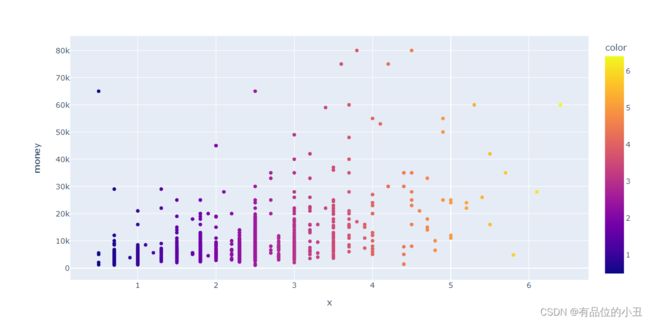
经分析,总体上layout_weight值小的房源数量也相对较多layout_weight值越小,其租金越少;layout_weight值越大,其租金逐渐增长。其中,当layout_weight值在0~4时,租金普遍在20K以下,租金的最大值也随着layout值变大而变大。当layout_weight值超过4时,其平均租金也逐渐上涨(layout_weight值中,室权重占比50%,厅权重占比30%,卫权重占比20%)
10、综合比较户型、地理位置、装修,找出对于房价租金影响最大的因素
10.1 户型与租金关系图:
fig = px.scatter(df1,x=layout_weight,y="money",color=layout_weight)
fig.show()

10.2 朝向与租金关系图:
fig = px.violin(df,y="money",color="location")
fig.show()

10.3 装修与租金关系图:
fig = px.scatter(df,x="zhuangxiu",y="money",color="zhuangxiu")
fig.show()

通过对上三幅图的对比,当户型权重越高时,房租价格普遍偏高;而南北通透的房屋租金最高,朝东西的房屋租金最低,其中南北对于房屋租金的影响比东西对与房屋的影响更为明显。所以南北通透或是阳面占比大是房屋高租金的关键,而其他朝向对租金影响不太大。在装修上除了毛坯房租金价格普遍较低其他三类装修对租金价格影响不大。
综上:户型对租金的影响最大,地理位置其次,装修影响最小。
11、出租方式
way=pd.DataFrame(df1["way"].value_counts()).reset_index()
fig=px.pie(way,names="index",values="way")
fig.show()

fig = px.scatter(df,x="way",y="money",color="way")
fig.show()

三、项目小结与租房建议:
通过以上分析得到以下租房建议(仅供参考):
① 商圈和金融圈以及发达工业区租金普遍偏高
② 低楼层租金普遍较高,出行会方便一点,适合出行不便的人,但中高楼层风景好,也可避免低层噪音干扰,合适喜爱安静的人
③ 新小区和老旧小区较5-10年的小区会便宜,但基础设施不够完善或老化
④ 若没有朝向要求,尽量避免选择朝北、朝南和朝南北的房型
⑤ 装修程度上,若不需要进行改造自己爱好的房型选择普装和精装较合适,若想要自己喜欢的装修风格,可以选择毛坯房,租金较便宜但需要额外的装修费用
⑥ 户型按居住人口选择合适即可,多户型意味着更高的租金