跑通CHPDet模型
一、运行环境
- python 3.9.12
- torch 1.12.0+cu116
- numpy==1.22.4
- pycocotools==2.0
- Cython==0.29.30
二、前置工作
项目github地址: https://github.com/zf020114/CHPDet
需要安装的有:
- lib/models/networks/DCNv2
- lib/models/networks/orn
- lib/models/external
如果直接运行python setup.py build develop,因为pytorch版本问题,会出现:
![]()
前两项安装在目前的环境下是无法成功的,我们需要修改一些代码。主要原因是新版的pytorch删去了THC/THC.h函数。
对于DCNv2网上有现成的新版代码适合新版pytorch。我们下载下来替换即可。网址:https://gitcode.net/mirrors/jinfagang/DCNv2_latest
对于orn目前网上没有找到新的代码,我们只能自己修改。参考:https://github.com/CoinCheung/pytorch-loss/pull/37
https://blog.csdn.net/qq_36891089/article/details/124353149

/**
1. 在src/lib/models/networks/orn/csrc/cuda/ActiveRotatingFilter_cuda.cu
和src/lib/models/networks/orn/csrc/cuda/RotationInvariantEncoding_cuda.cu
中添加下面原子操作。
2. 将#include 注释,并把代码中的THCudaCheck替换成AT_CUDA_CHECK
*/
/**
Computes ceil(a / b)
*/
template <typename T>
__host__ __device__ __forceinline__ T THCCeilDiv(T a, T b) {
return (a + b - 1) / b;
}
/**
Computes ceil(a / b) * b; i.e., rounds up `a` to the next highest
multiple of b
*/
template <typename T>
__host__ __device__ __forceinline__ T THCRoundUp(T a, T b) {
return THCCeilDiv(a, b) * b;
}
对于第三项的安装,可以直接运行python setup.py build develop
前面的安装过程如果出现 /orn/csrc/vision.cpp' cannot be absolute,这时可以看一下egg-info/SOURCES.txt里面的路径,要正确。

三、运行代码
3.1 demo.py
可以下载官方的代码,确定程序可以跑通。直接运行 python demo.py multi_pose可能会出现下面错误。
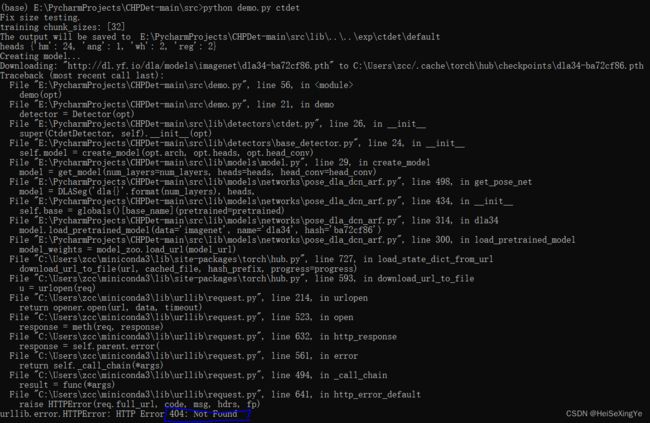
找到网址下载好权值文件,保存到指定路径下就可以了。
还需要指定测试图像位置和权值文件路径。
至此,完成demo的操作,有时间将会更新训练和测试部分。
3.2 make_json_anno.py
这个脚本用来将作者提供的xml格式的标签文件转为coco格式,这里的coco格式与官方的并不完全相同。
原xml格式:每一张图像对应一张xml文件
<annotation>
<folder>0.5folder>
<filename>100001677.jpgfilename>
<path>/home/zf/Dataset/FGSD/US_Navy_trainpath>
<source>
<database>FGSDdatabase>
source>
<size>
<width>674width>
<height>464height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>佩里级name>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<robndbox>
<cx>607.3634729414094cx>
<cy>299.1181166743358cy>
<w>19.54958411723933w>
<h>133.8365566916934h>
<angle>2.97218angle>
robndbox>
<extra>extra>
object>
<object>
<name>提康德罗加级name>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<robndbox>
<cx>145.0018147545185cx>
<cy>361.1216602692171cy>
<w>23.596561322320788w>
<h>175.34243525858705h>
<angle>3.00056angle>
robndbox>
<extra>extra>
object>
annotation>
转换后的coco格式:所有图像信息、label信息以及类别信息都存放在同一个json文件中,按照下面的方式组织排列。
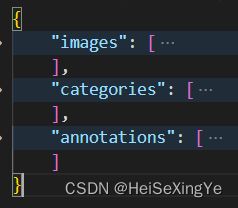
{
"images": [
{
"file_name": "0.5-0.479-luota-20041031.jpg",
"width": 1024,
"height": 1024,
"id": 0
}
],
"categories": [
{
"supercategory": "\u822a\u6bcd",
"name": "\u822a\u6bcd",
"id": 1,
"keypoints": [
"ship head"
],
"skeleton": [
[
1,
1
]
]
}
],
"annotations": [{
"image_id": 0,
"category_id": 15,
"bbox": [
1189.232775,
489.55475,
33.98225,
214.5651
],
"id": 0,
"area": 5468.5536521062495,
"iscrowd": 0,
"segmentation": [
[
1146.9213332144272,
550.5249055305029,
1136.5633833396728,
515.1979874652901,
1140.967327332676,
511.636685822413,
1173.3449971724472,
529.1570956732402,
1286.8942766428356,
669.5733584275171,
1260.4706126848155,
690.9411682847799
]
],
"num_keypoints": 1,
"keypoints": [
[
1138.7653553361743,
513.4173366438516,
2.0
]
]
}
]
}
coco格式中segmentation一共有6个点坐标,分别如下图所示:
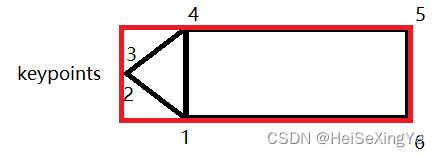
注意:红色的框是我们正常的四个顶点坐标。该脚本的一个作用就是将红色框坐标转为黑色框的顶点坐标。2和3是keypoints附近的点。作者认为船体的头部近似正方形,因此,1和4的横坐标就是红框左边坐标减去w(是短边)。
数据的存放方式:
--data
--coco
--train
--xxx.jpg
--val
--xxx.jpg
--annotations
--xxx.json
总结,我们需要将自己的数据标签转为上面的格式,才可以训练模型。