Sim2Real学习总结:A Short Survey
欢迎关注下方二维码哒公众号,回复神秘代码:Sim2Real,文中涉及的文章一键获得
欢迎关注Hello Neural Networks,研究图形学、深度学习、强化学习和Robotic类话题

引言
最近学习了Sim2Real领域的一些相关工作,以此文做一次学习总结,文章主要参照2020的一篇Survey:《Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: a Survey》,虽然工作内容比较旧但是比较经典,有不足之处还请多多指教。此文主要分为以下几个部分:
- 问题的提出
- Sim2Real算法的类别
- Sim2Real不同类别算法的文献简读
- 参考文献
1.问题的提出
Sim2Real,即Simulation to Reality,研究Sim2Real这个问题,旨在解决将模拟环境中的算法迁移到真实世界中来的问题,在强化学习领域较为常见(不单单是强化学习领域的涉及)。
需要明确的三个问题有:①为什么要有Sim2Real相关算法;②Sim2Real有什么困难;③怎么解决Sim2Real中的困难。
①在强化学习领域中,我们假如让机器直接在现实环境中与环境进行交互获得经验,可能会出现很多的问题,比如采样的效率会比较低,多次交互机器磨损可能也多和安全问题难以得到一定的保障等。但是在模拟环境中,上面的问题都会很好的被解决,所以假如我们能够在模拟环境中将算法给训练到位了,再部署到真实环境中,将会极大的降低我们的成本。
②在模拟环境中训练,然后再在现实环境中部署落地是比较理想的情况,但是因为模拟环境和现实环境存在一定的误差(一般称之为gap),比如物理建模(如摩擦力等)、现实的环境差异(如依赖视觉的情况下,现实的光照条件等)等的差异,导致Sim2Real实地实验的时候效果往往不理想。
③解决Sim2Real中的困难可看Part2:Sim2Real算法的类别,里面不同类别对这个问题提供了不同的解决方法,本质上还是解决Reality Gap这么一个问题。
值得一提的是,在真实世界中的采样有着一定的优势,那么是否可以在真实世界中采取一定的约束使得磨损或安全问题得以解决,然后辅以模拟世界的高效率采样来达到一种均衡呢,其实是有文章在做的,此文为:《Generalization through Simulation: Integrating Simulated and Real Data into Deep Reinforcement Learning for Vision-Based Autonomous Flight》。这篇文章将控制和感知分开,控制部分通过使用真实环境采样数据对模型本身进行学习,包括机器人的物理特性和环境交互模型等,感知部分则利用模拟环境中的仿真数据,高效率采样地来学习如何将感知模型进行泛化。
2.Sim2Real算法的类别
Sim2Real算法的类别大致可以分为以下几种:
① Domain Randomization
核心方法:对模拟环境中的参数随机化,如摩檫力(物理)、物体颜色(视觉)等,使得在模拟环境中的参数大概率地囊括了真实环境中的参数,如真实世界环境摩擦系数可能为0.3,但是我在模拟环境中要求智能体在摩擦系数为0.1-1范围内都能适用,这样迁移到真实世界就可以直接部署了。(注:这是种Zero-shot Transfer)
推荐文献:《Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World》(IROS, 2017)
② Domain Adaption
核心方法:通过学习一个模拟环境以及现实环境共同的状态到隐变量空间的映射,在模拟环境中,使用映射后的状态空间进行算法的训练;因而在迁移到现实环境中时,同样将状态映射到隐含空间后,就可以直接应用在模拟环境训练好的模型了。
常见算法:Ⅰ.Discrepancy-based:基于差异的方法通过计算预定义的统计量来测量源和目标域之间的特征距离,以对齐它们的特征空间;
Ⅱ.Adversarial-based:基于对抗性的方法建立一个域分类器来区分特征是来自源域还是目标域。经过训练,该提取器可以同时在源域和目标域产生不变特征;
Ⅲ.Reconstruction- based:基于重构的方法旨在找到域之间的不变特征或共享特征。他们通过构建一个辅助重构任务并利用共享特征恢复原始输入来实现这一目标,这样,共享特性应该是不变的,并且独立于域,其实就是找到一个共同的隐空间。
推荐文献:Ⅰ.Discrepancy-based:《Learning transferable features with deep adaptation networks》(ICML, 2015);
Ⅱ.Adversarial-based:《Unsupervised pixel-level domain adaptation with generative adversarial networks》(CVPR, 2017);
Ⅲ.Reconstruction- based:《Adapting Deep Visuomotor Representations with Weak Pairwise Constraints》(CVPR)
③ Transfer Learning
核心方法:将不同任务分配给仿真环境和现实环境去做,然后将仿真环境得到的模型在现实环境做Fine-tune并作一定的适配。
推荐文献:Ⅰ.《Sim-to-Real Robot Learning from Pixels with Progressive Nets》;
Ⅱ.《Generalization through Simulation: Integrating Simulated and Real Data into Deep Reinforcement Learning for Vision-Based Autonomous Flight》
④ Inverse Dynamic Model
核心方法:通过在现实环境中学习一个逆转移概率矩阵来直接在现实环境中应用模拟环境中训练好的模型。
推荐文献:《Transfer from Simulation to Real World through Learning Deep Inverse Dynamics Model》
⑤ Knowledge Distillation
核心方法:为了适配真实环境的变化,在模拟环境中针对真实环境的变化进行了多次的学习,知识蒸馏能将这多次学习的结果整合成一个模型以适配(类似于多个老师教一个学生知识),并在后面真实环境部署中持续学习,并教会学生模型怎么去做的更好。
推荐文献:《Continual reinforcement learning deployed in real-life using policy distillation and sim2real transfer》
⑥ Meta Learning
核心方法:旨在从模拟环境中的多个训练任务中学习对潜在测试任务的适应能力,并在部署到真实环境中通过Fine-ture即可适应。
推荐文献:《Learning to reinforcement learn》
⑦ Robust RL
核心方法:有点像Domain Randomization,但是它是考虑了智能体在模拟环境中考虑了最坏的情况下仍然能够完成任务,这是Robust的,基于此,迁移到真实环境中也是Robust的。
推荐文献:Ⅰ.《Robust reinforcement learning for continuous control with model misspecification》;
Ⅱ.《Action robust reinforcement learning and applications in continuous control》
⑧ Imitation Learning
核心方法:采用专家演示代替人工构造固定的奖励函数来训练模型,这样得到的奖励会更加Robust,迁移到真实环境中也更为适应。(个人感觉思想有点像Domain Adaption,考虑了模拟环境和真实环境的潜在的共性,只是人工构造固定的奖励无法较为深入挖掘这种共性,而智能体自己去学习奖励函数可能会挖掘出这种共性)
推荐文献:《Sim-to-Real Transfer of Accurate Grasping with Eye-In-Hand Observations and Continuous Control》(NIPS AIRW 2017)
⑨ System Identification
核心方法:为物理系统建立一个精确的数学模型,使仿真器更加真实,但是获得足够逼真的模拟器的挑战仍然存在,很难构建高质量的渲染图像来模拟真实的视觉,或许图形学的发展可能能为这个方法提供一定的帮助。
3.Sim2Real不同类别算法的文献简读
① Domain Randomization
论文:《Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World》

简介:
使用Domain Randomization,通过在模拟器中随机化渲染将模型转换为真实图像,在模拟图像上训练模型。当在模拟环境中有足够多的可变性时,现实环境在模型中可能只有其中一种变化,使得仅使用来自具有非真实随机纹理的模拟器的数据,就可以训练一个真实环境中的目标检测器。该检测器可精确到1.5厘米,并且对干扰和部分遮挡具有鲁棒性。论文中为了展示探测器的能力,他们展示了模型可以在杂乱的环境中执行抓取。截至该论文发稿时,该论文是第一次成功地将仅在模拟RGB图像上训练的深度神经网络(未对真实图像进行预训练)转移到现实世界,以实现机器人控制,这是一篇开山之作。
Keypoint:
Ⅰ.本文首次证明了Domain Randomization对于要求精度的机器人任务是有用的,文中还提供了一项关于不同随机选择和训练方法对转移成功的影响的消融研究。文中并且指出,对于足够数量的纹理,使用真实图像预训练对象检测器是不必要的。
Ⅱ.本文需要训练一个对象检测器,该检测器将单个单目相机帧映射到每个对象的笛卡尔坐标{(xi,yi,zi)}。该网络需要实现除了感兴趣的对象之外,也适应某些包含网络必须忽略的干扰的场景。
Ⅲ.Domain Randomization包含了以下的几项内容:
桌子上干扰物对象的数量和形状
桌子上所有目标物体的位置以及纹理
桌子、地板、背景以及机械臂的纹理
摄像机的位置、方向以及视野
场景中光源的数量
场景中光源的位置、朝向以及光学反射特征
加入到图像中随机噪声的类型以及数量(如椒盐噪声、高斯噪声等)
上面需要进行的纹理随机可以通过以下几种方式进行随机:
RBG值随机化
两个像素之间的梯度随机化
两个像素之间采取checker pattern的方式随机化
Ⅳ.网络架构使用了VGG-16的体系结构,并且大多数实验采用了ImageNet上预训练获得的权重来初始化卷积层。

②Domain Adaption
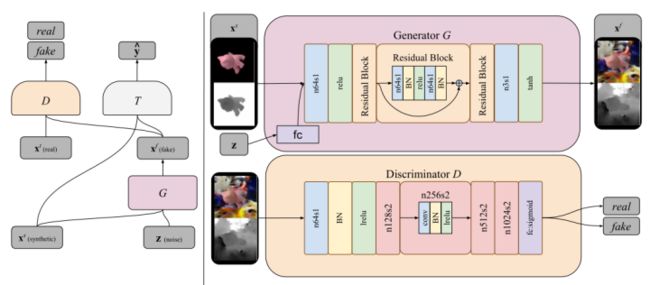
论文:《Unsupervised pixel-level domain adaptation with generative adversarial networks》

简介:
本文训练一个模型来改变源域中的图像,使其看起来像是从目标域中采样的,同时保持其原始内容,这样的话,直接在现实世界采样后再transfer到目标域即可直接接入任务模型完成任务了。文中提出了一种新的基于生成性对抗网络(GAN)的架构,该架构能够以无监督的方式学习这种转换,即不使用来自两个域的对应对。截至该论文发稿时,与现有方法相比,该无监督像素级域自适应方法(PixelDA)具有许多优势。
Keypoint:
Ⅰ.与特定于任务的体系结构分离:在以往大多数Domain Adaption方法中,Domain Adaption过程与用于推理的特定于任务的体系结构紧密结合(即图像域和任务域耦合起来一起做源域or目标域,然后transfer)。而该文针对图像域做transfer,分离了任务域,使得不必重新训练整个领域适应过程。
Ⅱ.跨标签空间的泛化:以前的模型将Domain Adaption与特定任务相结合,所以源域和目标域中的标签空间被限制为匹配。相比之下,本文运用了GAN,提出的PixelDA模型能够处理测试时目标标签空间与训练时标签空间不同的情况。
Ⅲ.训练稳定性:本文在源图像和生成图像上都加入了一个特定于任务的损失训练(见文章3.1. Learnin章节),以及一个像素相似性正则化(目的是使得源域前景content与转换后的前景content差异不大,但是又实实在在的让转换后的特征向量与目标域相近,见文章3.2. Content–similarity loss章节),用以避免模式崩溃,并稳定训练。通过使用这些工具能够减少模型不同随机初始化过程中相同超参数的性能差异。
Ⅳ.数据扩充:传统的领域适应方法仅限于从有限的源和目标数据集中学习。然而,通过对源图像和随机噪声向量(见Ⅵ)进行调节,该模型可以用来创建几乎无限的随机样本,这些样本看起来与目标域的图像相似。
Ⅴ.可解释性:PixelDA是一种域适应的图像,其输出比域适应的特征向量更容易解释。
Ⅵ.与标准GAN公式不同,在标准GAN公式中,生成器仅以噪声向量为条件,本文PixelDA模型的生成器以噪声向量和源域的图像为条件。
4.参考文献
[1]Wenshuai Zhao, Jorge Peña Queralta, Tomi Westerlund. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: a Survey. In IEEE Symposium Series on Computational Intelligence, 2020
[2]满船清梦29. 《Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics a Survey》阅读笔记. In CSDN, 2021
[3]长颈鹿骑着鲨鱼. Sim2Real. In 知乎, 2020