划分非独立同分布(Non-IID)数据集
在传统的机器学习中,数据同在一个中心,不会出现什么非独立同分布的问题;然而在联邦学习中,每个客户端(client)都拥有自己的数据集,大家各不相同,所以数据不独立同分布是常态。因此我们在做实验时,需要模拟真实的场景,对一个数据集进行
Non-IID的划分。这里参考网上的资料,按
Dirichlet分布划分Non-IID数据集。首先处理常见的非结构化数据集,之后再处理结构化数据集。
文章目录
-
- 什么是Non-IID
- 如何进行划分
-
- numpy中的dirichlet函数
- 函数使用案例
- 划分代码实现
- 测试
- 划分结构化数据集
-
- 划分实现
- 测试
- 最后的封装
- 参考
什么是Non-IID
非独立同分布包括以下三种:
- 不独立但同分布
- 独立但不同分布
- 不独立也不同分布
也就是说,除了独立同分布(independent and identically distributed),其余都是 Non-IID。
独立没什么好说的,关键在于同分布。
举个栗子,对于标准数据集 cifar-10 ,该数据集有 6w 张图片,分为 10 类,每类均为6k张图片。在做传统的图像分类实验中,数据集采用均匀划分的 5w 个作为训练集,1w 个样本作为测试集。我们把训练集和测试集看作两个数据集,他们各自有 10 个类别,每类都占有 1/10 ,也就是他们的标签分布都为 1:1:1……,对于两个数据集的类别数量比相同,这就叫同分布(IID)。
此时我们再想想,为什么多个客户端提供的数据集具有 Non-IID 的性质,因为不同数据集的不同类数量比一般都不同,你提供一个 100:150:200 的数据集,我提供一个 200:301:402的数据集,看起来近似,但分布就是不一样。
如何进行划分
这里先对非结构化的数据集进行划分,之后再处理结构化数据集
非结构化:图像、文本、 视频
结构化:类似于 json 格式的或数据库表那样格式的数据
比较常见的是根据样本的标签分布进行 Non-IID 的划分。
思路如下:
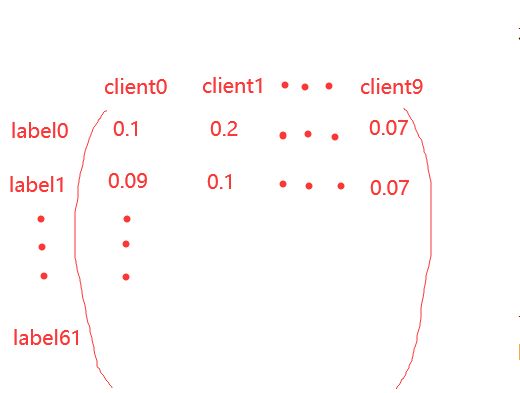
尽量让每个 client 上的样本标签分布不同。我们设有 K 个类别标签, N 个 client,每个类别标签的样本需要按照不同的比例划分在不同的 client 上。我们需要一个类别标签分布的矩阵,其行向量表示类别 k 在不同 client 上的概率分布向量(显然每个行向量的和为1),该随机向量就采样自 Dirichlet 分布。
numpy中的dirichlet函数
def dirichlet(alpha, size=None):
参数:
alpha: 对应分布函数中的参数向量 α ,长度为 k 。
size: 为输出形状大小,因为采出的每个样本是一个随机向量,默认最后一维会自动加上 k ,如果给定形状为 (m,n) ,那么 m×n 个维度为 k 的随机向量会从中抽取。默认为 None,即返回一个一个 k 维的随机向量。
返回:
out: ndarray 采出的样本,大小为 (size,k) 。
这里的 α 越小,得到的差异越大;α 越大,差异越小,也就是越平均。
K 其实就对应着 client 的数量。
函数使用案例
设 α=(10,5,3) (意味着 k=3 ), size=(2,2) ,则采出的样本为 2×2 个维度为 k=3 的随机向量。
import numpy as np
s = np.random.dirichlet((10, 5, 3), size=(2, 2))
print(s)
因为调用了 random,所以每次打印的结果都是不同的。在实验时应该设置随机数种子,保证相同的数据拆分,即结果的可复现。

划分代码实现
首先再来理一理思路,我们的目的是:将每个类别划分为 N 个子集。
- 拿到数据集对应标签的所有下标
- 分类
- 得到每个类别的所有下标
- 将每个类别用
dirichlet函数划分为 N 份 - 得到划分后的标签下标
import numpy as np
# 设置随机数种子,保证相同的数据拆分,可获得结果的复现
np.random.seed(42)
def dirichlet_split_noniid(train_labels, alpha, n_clients):
'''
参数为 alpha 的 Dirichlet 分布将数据索引划分为 n_clients 个子集
'''
# 总类别数
n_classes = train_labels.max()+1
# [alpha]*n_clients 如下:
# [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
# 得到 62 * 10 的标签分布矩阵,记录每个 client 占有每个类别的比率
label_distribution = np.random.dirichlet([alpha]*n_clients, n_classes)
# 记录每个类别对应的样本下标
# 返回二维数组
class_idcs = [np.argwhere(train_labels==y).flatten()
for y in range(n_classes)]
# 定义一个空列表作最后的返回值
client_idcs = [[] for _ in range(n_clients)]
# 记录N个client分别对应样本集合的索引
for c, fracs in zip(class_idcs, label_distribution):
# np.split按照比例将类别为k的样本划分为了N个子集
# for i, idcs 为遍历第i个client对应样本集合的索引
for i, idcs in enumerate(np.split(c, (np.cumsum(fracs)[:-1]*len(c)).astype(int))):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
有很多方法对我这 AI 小白并不友好。。记录如下:
- np.argwhere(a > 1):返回数组中大于 1 的下标。
- zip:将对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
- enumerate:将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
- np.cumsum:特别抽象的累加

- np.concatenate:连接数组

测试
在 EMNIST 数据集上调用该函数进行测试,并进行可视化呈现。

import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
from main import dirichlet_split_noniid
torch.manual_seed(42)
if __name__ == "__main__":
# 初始化客户端数、参数α
N_CLIENTS = 10
DIRICHLET_ALPHA = 1.0
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
# num_cls 为类别总数
num_cls = len(train_data.classes)
# 所有数据对应的标签下标
train_labels = np.array(train_data.targets)
# 我们让每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = dirichlet_split_noniid(train_labels, alpha=DIRICHLET_ALPHA, n_clients=N_CLIENTS)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc] for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
这个图画得也是远超我的水准。。。
打印一堆变量方才看出所以然来。
print(train_labels)
print(len(train_labels))
for idc in client_idcs:
print(train_labels[idc])
print(len(train_labels[idc]))
print(np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1))
至此,非结构化数据集的划分完毕。
划分结构化数据集
首先得搜集结构化数据集,这里使用 UCI 上的数据集,可参考以下博客:
- UCI数据集整理(附论文常用数据集)
- UCI数据集的简单介绍和使用Python保存UCI数据集为.mat文件
因需求原因,选择的是红葡萄酒数据集:Wine Quality Data Set
红葡萄酒介绍:Red Wine——红葡萄酒各指标相关性分析
有部分数据集是可以直接通过调用函数载入的,例如:
Data = datasets.load_wine()这类数据集有很多属性,便于使用,可大部分数据集又是无法直接 load 的,例如红葡萄酒。
下载到本地:

划分实现
这里并没有改动主要的划分函数 dirichlet_split_noniid,而是对数据集做了一定的预处理。
最后的划分结果会在原有 dataframe 的基础上新增一列 ”client“,表示该行数据分给哪个客户端,
需要使用数据集时进行 group 即可。
import numpy as np
# 设置随机数种子,保证相同的数据拆分,可获得结果的复现
np.random.seed(42)
def dirichlet_split_noniid(train_labels, alpha, n_clients):
'''
参数为 alpha 的 Dirichlet 分布将数据索引划分为 n_clients 个子集
'''
# 总类别数
n_classes = train_labels.max()+1
# [alpha]*n_clients 如下:
# [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
# 得到 62 * 10 的标签分布矩阵,记录每个 client 占有每个类别的多少
label_distribution = np.random.dirichlet([alpha]*n_clients, n_classes)
print(label_distribution)
# 记录每个类别对应的样本下标
class_idcs = [np.argwhere(train_labels==y).flatten()
for y in range(n_classes)]
# 定义变量作最后的返回值
client_idcs = [[] for _ in range(n_clients)]
# 记录N个client分别对应样本集合的索引
for c, fracs in zip(class_idcs, label_distribution):
# split_indexs 记录划分时的间断点
split_indexs = (np.cumsum(fracs)[:-1] * len(c)).astype(int)
# for i, idcs 为遍历第i个client对应样本集合的索引
# np.split按照比例将类别为k的样本划分为了N个子集
for i, idcs in enumerate(np.split(c,split_indexs)):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
测试
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
from main import dirichlet_split_noniid
import pandas as pd
torch.manual_seed(42)
if __name__ == "__main__":
# 初始化客户端数、参数α
N_CLIENTS = 5
DIRICHLET_ALPHA = 2.0
df = pd.read_csv('winequality-red.csv', sep=';')
# 取最后一列,即所有的标签
labels = df.iloc[:,-1]
# 获取所有标签名称
target_name = labels.unique()
# 获取所有标签对应的下标
target = [np.argwhere(target_name == name).flatten()
for name in labels]
target = np.concatenate(np.array(target))
# target = []
# for name in labels:
# for index,item in enumerate(target_name) :
# if name == item:
# target.append(index)
# target = np.array(target)
# num_cls 为类别总数
num_cls = len(target_name)
# 我们让每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = dirichlet_split_noniid(target, alpha=DIRICHLET_ALPHA, n_clients=N_CLIENTS)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(14,8))
plt.hist([target[idc] for idc in client_idcs], stacked=True,
bins=np.arange(min(target)-0.5, max(target) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), target_name)
plt.legend()
plt.show()
df['client'] = -1
for i, indexs in enumerate(client_idcs):
for index in indexs:
df.loc[index, "client"] = i
print(df)
最后的封装
为了方便使用,当然得封装到一个类里,最后还加了一些注释。
这里还顺手加上了独立同分布的划分。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from pandas import DataFrame
class Partitioner(object):
# 设置随机数种子,保证相同的数据拆分,可获得结果的复现
np.random.seed(42)
def __init__(self, dataset:DataFrame, n_clients: int,split_policy: str = "non-iid",alpha:int = 1.0,show_img: bool = True):
'''
初始化数据划分的类
:param dataset: DataFrame类型的数据集
:param n_clients: 客户端数量
:param split_policy: 划分策略, 传入字符串 non-iid 或 iid
:param alpha: 狄利克雷分布函数的参数
:param show_img: 是否展示划分后的可视化图片
'''
self.dataset = dataset
self.n_clients = n_clients
self.split_policy = split_policy
self.alpha = alpha
self.show_img = show_img
def partition(self):
'''
划分实现
:return: 划分后的数据集索引
'''
# 取最后一列,即所有的标签
labels = self.dataset.iloc[:, -1]
# 获取所有标签名称
target_name = labels.unique()
# 获取所有标签对应的下标
target = [np.argwhere(target_name == name).flatten()
for name in labels]
target = np.concatenate(np.array(target))
# num_cls 为类别总数
num_cls = len(target_name)
# 我们让每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = self.split_index(target, split_policy=self.split_policy,alpha=self.alpha, n_clients=self.n_clients)
if self.show_img:
self.show_split_img(target,client_idcs,num_cls,target_name)
return client_idcs
def split_index(self,target, n_clients, split_policy, alpha):
'''
具体的划分函数
:param target: 数据集对应的标签下标
:param n_clients:
:param split_policy:
:param alpha:
:return:
'''
# 记录总类别数
n_classes = target.max() + 1
# 记录每个类别对应的样本下标
class_idcs = [np.argwhere(target == y).flatten()
for y in range(n_classes)]
if split_policy == "iid":
label_distribution = [[1.0 / n_clients for _ in range(n_clients)]
for _ in range(n_classes)]
elif split_policy == "non-iid":
label_distribution = np.random.dirichlet([alpha] * n_clients, n_classes)
# 定义变量作最后的返回值
client_idcs = [[] for _ in range(n_clients)]
# 记录N个client分别对应样本集合的索引
for c, fracs in zip(class_idcs, label_distribution):
# split_indexs 记录划分时的间断点
split_indexs = (np.cumsum(fracs)[:-1] * len(c)).astype(int)
# for i, idcs 为遍历第i个client对应样本集合的索引
# np.split按照比例将类别为k的样本划分为了N个子集
for i, idcs in enumerate(np.split(c, split_indexs)):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
def show_split_img(self,target,client_idcs,num_cls,target_name):
# 展示不同client的不同label的数据分布
plt.figure(figsize=(14, 8))
plt.hist([target[idc] for idc in client_idcs], stacked=True,
bins=np.arange(min(target) - 0.5, max(target) + 1.5, 1),
label=["Client {}".format(i+1) for i in range(self.n_clients)], rwidth=0.5)
plt.xticks(np.arange(num_cls), target_name)
plt.legend()
plt.show()
测试:
from non_iid4.dataset_util import Partitioner
import pandas as pd
df = pd.read_csv('winequality-red.csv', sep=';')
# 测试集使用的公共数据集
non_iid_partitioner = Partitioner(df,5,"non-iid")
indexs = non_iid_partitioner.partition()
client1_index = list(indexs[0])
client1_data = df.loc[client1_index]
print(client1_data)
参考
什么是非独立同分布
狄利克雷分布参考资料:
什么是狄利克雷分布?狄利克雷过程又是什么?
Dirichlet distribution狄利克雷分布
浅谈狄利克雷分布——Dirichlet Distribution
代码实现摘于知乎大佬:联邦学习:按Dirichlet分布划分Non-IID数据集