『医学影像』基于Unet模型实现脊柱CT定位(中)
基于Unet模型实现脊柱CT定位(中)
目前AIstudio已经有许多基于Unet的分割项目,本项目在主要介绍分割网络的另外的应用场景,希望对大家的研究有所启发。
在项目『医学影像』基于Unet+++实现脊柱MRI定位(上)中,笔者初步探索了基于分割网络实现锥体定位的可行性。
但医疗数据种类繁多,并且成像原理各不相同,与此相关的数据集非常稀缺。此外,之前的项目仅仅探索了在侧面视图的情况下的可行性。
本项目将根据论文《Automatic L3 slice detection in 3D CT images using fully-convolutional networks》开源的CT多视图数据集进行研究。
展示了在CT数据中的定位可行性,探索了定位CT开源数据集的使用,对比在CT数据的侧面视图与正面视图中锥体定位的精度。
0. 研究动机
在医学领域,经常需要分析患某种疾病后身体脂肪含量的变化,一般通过选择某个锥体的截面来估计全身的脂肪含量。
常规的方法是通过手动从几百张影像中选择需要的切片(一般为L3),这种方法即耗时又枯燥,稍不注意还容易出错。
直接从CT图像中提取测量值非常方便,因为CT经常作为癌症分期和疾病评估的一部分获得。
目前计算肌细胞减少测量值的工作流程如下:
-
手动提取L3切片;这涉及到逐层滚动3D图像,直到找到L3层。
-
半自动分割软件(例如:Slice-O-Matic或ImageJ),包括手动细化,然后用于分割骨骼肌和脂肪组织。
此过程每幅图像需要5到10分钟,并且在大型数据集上运行会变得非常耗时
切片选择相关的研究大部分都是在3D数据上对所有的锥体进行标注,但是仅仅对单一锥体进行定位不需要其他的锥体的具体位置,而且3D数据的训练和推理需要更多的时间。
因此,目前的一个解决方案是通过将三维数据映射使用MLP映射到二维,然后使用深度学习进行定位。
由于CT影像数据的丰富性,我们可以通过MLP数据同时获得正面视图和侧面视图来进行定位。

论文《Automatic L3 slice detection in 3D CT images using fully-convolutional networks》

在过去几年中,对第三腰椎(L3)处提取的单个CT切片的分析已经引起了临床上的极大兴趣,特别是在量化肌减少(肌肉丧失)方面。
该文章提出了一种在三维CT图像中自动检测L3切片的有效方法。适用于具有各种视场、遮挡和切片厚度的图像。
首先,通过最大强度投影(MIP)将三维CT图像转换为二维图像,从而降低了问题的维数。
然后将MIP图像用作2D全卷积网络的输入,以2D置信图的形式预测L3切片的位置。

1. 项目介绍
计算机断层扫描(CT)成像广泛用于研究身体成分,即肌肉和脂肪组织的比例,应用于营养或化疗剂量设计等领域。
特别是,来自固定位置的轴向CT切片通常用于身体成分分析。然而,如果手动进行,从数百张切片中手动选择是非常繁琐的操作。
本项目将3D CT体积作为输入。体积通过最大强度投影(MIP)转换为2D图像,并进行进一步后处理。
将2D MIP图像用作网络的输入。根据网络,输出是1D或2D置信图。
置信图中的最大概率位置用作L3位置的预测,允许从CT体积中提取横向切片。
最终实现目标锥体的快速自动识别。
2. 数据集介绍
数据集来自论文公开数据集,作者从多个公开可用的数据集中收集了1070个CT图像组成的不同数据集。
癌症影像档案(TCIA)中获得3组:头颈部、卵巢、结肠;肝肿瘤数据集来自LiTS分割挑战;卵巢癌数据集来自伦敦哈默史密斯医院(HH)。
所有1070个3D CT图像都经过预处理,其中每个3D图像都会生成一组由正面图像和受限矢状图像组成的图像。
对归一化为1x1mm的图像进行注释。MIP图像由2名注释员注释:一名具有7年经验的放射科医生和一名具有5年CT图像工作经验的注释员。
对于每个图像集,注释器都会看到正面和受限矢状MIP并排显示,注释器单击L3切片的位置。
主要标志物被选为椎弓根的中间,与横突的顶部边缘对齐。

3. 代码实现
3.1 数据集预处理
本项目读取原论文数据集,其正面视图及侧面视图的尺寸最大为 700*1161,L3锥体位置为 第90-slice 到 第860-slice,空间差异较大。
对数据进行进一步处理。将空间分辨率统一为1mm,hu值截取为【100,1500】,图像两边各mask35%以去除无关信息干扰,并截取512*512尺寸的数据作为最终数据集。
具体代码处理如下:
- 经过处理后剩余979个数据集。
import numpy as np
from scipy.ndimage import zoom
def normalise_zero_one(image, eps=1e-8):
image = image.astype(np.float32)
ret = (image - np.min(image))
ret /= (np.max(image) - np.min(image) + eps)
return ret
def reduce_hu_intensity_range(img, minv=100, maxv=1500):
img = np.clip(img, minv, maxv)
img = 255 * normalise_zero_one(img)
return img
def normalise_spacing_and_preprocess(images, images_sagittal, slice_locations, spacings, new_spacing=1):
images_norm = []
images_s_norm = []
slice_loc_norm = []
for image, image_s, loc, s in zip(images, images_sagittal, slice_locations, spacings):
img = zoom(image, [s[2] / new_spacing, s[0] / new_spacing])
img_s = zoom(image_s, [s[2] / new_spacing, s[0] / new_spacing])
images_norm.append(reduce_hu_intensity_range(img))
images_s_norm.append(reduce_hu_intensity_range(img_s))
slice_loc_norm.append(int(loc * s[2] / new_spacing))
return np.array(images_norm), np.array(images_s_norm), np.array(slice_loc_norm)
def resize_img(img_0,img_1,loc_,min_h_w=512):
assert min_h_w% 2 == 0, '要求限制范围取值为偶数'
img_0_out,img_1_out,loc_out = [],[],[]
for i in range(len(img_0)):
img_f = img_0[i]
img_s = img_1[i]
loc = loc_[i]
if loc>min_h_w:
continue
else:
## 处理高度
h,w = img_f.shape
# 处理高度
if h>min_h_w:
img_f = img_f[:min_h_w,:]
img_s = img_s[:min_h_w,:]
else:
img_f_ = np.zeros((min_h_w,w))
img_s_ = np.zeros((min_h_w,w))
img_f_[:h,:] = img_f
img_s_[:h,:] = img_s
img_f = img_f_
img_s = img_s_
# 处理宽度
if w>min_h_w:
mid_w = int(w*0.5)
img_f = img_f[:,mid_w-min_h_w//2:mid_w+min_h_w//2]
img_s = img_s[:,mid_w-min_h_w//2:mid_w+min_h_w//2]
else:
img_f_ = np.zeros((min_h_w,min_h_w))
img_s_ = np.zeros((min_h_w,min_h_w))
s_ind = int(0.5*(min_h_w-w))
img_f_[:,s_ind:s_ind+w] = img_f
img_s_[:,s_ind:s_ind+w] = img_s
img_f = img_f_
img_s = img_s_
# MASK 掉一部分
s_m = 0.35
img_f[:,:int(s_m*img_f.shape[1])] = 0
img_f[:,int((1-s_m)*img_f.shape[1]):] = 0
img_0_out.append(img_f)
img_1_out.append(img_s)
loc_out.append(loc)
return img_0_out,img_1_out,loc_out
def generateTrainData(path = "data/data145717/l3_dataset.npz"):
data=np.load(path,allow_pickle=True)
images = data['images_f']
images_sagittal = data['images_s']
ydata = data['ydata']
names = data['names']
spacings = data['spacings']
data.close()
slice_locations = np.zeros_like(names, dtype=np.float)
n = len(ydata.item())
for k, v in ydata.item().items():
slice_locations += v
slice_locations /= n
images_frontal, images_sagittal, slice_locations = normalise_spacing_and_preprocess(images, images_sagittal,slice_locations, spacings, new_spacing=1)
images_frontal, images_sagittal, slice_locations = resize_img(images_frontal,images_sagittal,slice_locations)
return images_frontal, images_sagittal, slice_locations
images_frontal, images_sagittal, slice_locations = generateTrainData()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:26: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
len(images_frontal)
979
3.2 定义数据集读取类
本项目将原始数据集按照80%训练,20%验证进行划分。
对读取数据集进行展示。
# 定义数据读取类
import paddle
from paddle.io import Dataset
import numpy as np
from scipy.ndimage import zoom
import paddle.vision.transforms as T
# 重写数据读取类
class MRILocationDataset(Dataset):
def __init__(self,images_frontal, images_sagittal, slice_locations,mode = 'train',transform =None,k_fold=1):
# 数据读取
self.images_frontal_list = list(images_frontal)
self.images_sagittal_list = list(images_sagittal)
self.slice_locations_list = list(slice_locations)
self.mode = mode
# 选择前80%训练,后20%测试
scale_s = int(0.2*(k_fold-1)*len(self.slice_locations_list))
scale_e = int(0.2*k_fold*len(self.slice_locations_list))
self.transforms = transform
if self.mode == 'train':
self.images_frontal_list = self.images_frontal_list[:scale_s]+self.images_frontal_list[scale_e:]
self.images_sagittal_list = self.images_sagittal_list[:scale_s]+self.images_sagittal_list[scale_e:]
self.slice_locations_list = self.slice_locations_list[:scale_s]+self.slice_locations_list[scale_e:]
else:
self.images_frontal_list = self.images_frontal_list[scale_s:scale_e]
self.images_sagittal_list = self.images_sagittal_list[scale_s:scale_e]
self.slice_locations_list = self.slice_locations_list[scale_s:scale_e]
# one-hot 编码 并转为 tensor
# self.slice_locations_tensor = paddle.nn.functional.one_hot(paddle.to_tensor(slice_locations-np.min(slice_locations), dtype='int64'), num_classes=np.max(slice_locations-np.min(slice_locations))+1)
def __getitem__(self, index):
images_frontal = self.images_frontal_list[index]
images_sagittal = self.images_sagittal_list[index]
slice_locations = self.slice_locations_list[index]
#slice_locations = self.slice_locations_tensor[index]
images_frontal = np.expand_dims(images_frontal, axis=0)
images_sagittal = np.expand_dims(images_sagittal, axis=0)
images_frontal = images_frontal.repeat(3,axis=0)
images_sagittal = images_sagittal.repeat(3,axis=0)
wid_label = 3
label = np.zeros((1,images_frontal.shape[1],images_frontal.shape[2]))
label[:,slice_locations-wid_label:slice_locations+wid_label,int(images_frontal.shape[2]*0.35):int(images_frontal.shape[2]*0.7)] = 255
return images_frontal/255 ,images_sagittal/255 ,slice_locations,label/255
def __len__(self):
return len(self.slice_locations_list)
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
dataset = MRILocationDataset(images_frontal, images_sagittal, slice_locations,mode='train',k_fold=2)
print('=============train dataset=============')
for item in dataset:
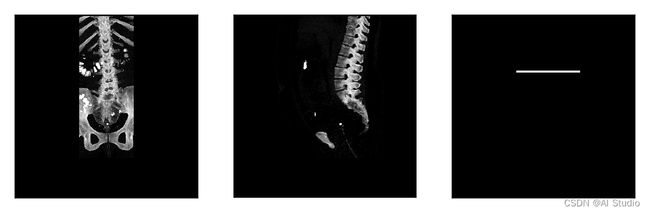
images_frontal_ ,images_sagittal_,slice_locations_,label= item
print(slice_locations_,images_frontal_.shape,images_sagittal_.shape,label.shape)
break
images_frontal_ = np.squeeze(images_frontal_[0,:,:])
images_sagittal_ = np.squeeze(images_sagittal_[0,:,:])
label = np.squeeze(label)
imga = Image.fromarray(images_frontal_*255)
imgb = Image.fromarray(images_sagittal_*255)
imgc = Image.fromarray(label*255)
plt.figure(figsize=(6, 2))
plt.subplot(1,3,1),plt.xticks([]),plt.yticks([]),plt.imshow(imga)
plt.subplot(1,3,2),plt.xticks([]),plt.yticks([]),plt.imshow(imgb)
plt.subplot(1,3,3),plt.xticks([]),plt.yticks([]),plt.imshow(imgc)
plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib_inline/config.py:68: DeprecationWarning: InlineBackend._figure_format_changed is deprecated in traitlets 4.1: use @observe and @unobserve instead.
def _figure_format_changed(self, name, old, new):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
=============train dataset=============
160 (3, 512, 512) (3, 512, 512) (1, 512, 512)
3.3 定义模型
本项目基于Unet网络完成实验。
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class DoubleConv(nn.Layer):
def __init__(self,in_ch,out_ch):
super(DoubleConv,self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(in_ch,out_ch,3,padding=1),#in_ch、out_ch是通道数
nn.BatchNorm2D(out_ch),
nn.ReLU(),
nn.Conv2D(out_ch,out_ch,3,padding=1),
nn.BatchNorm2D(out_ch),
nn.ReLU()
)
def forward(self,x):
return self.conv(x)
class UNet(nn.Layer):
def __init__(self,in_ch=3,num_classes=1):
super(UNet,self).__init__()
self.conv1 = DoubleConv(in_ch,64)
self.pool1 = nn.MaxPool2D(2)#每次把图像尺寸缩小一半
self.conv2 = DoubleConv(64,128)
self.pool2 = nn.MaxPool2D(2)
self.conv3 = DoubleConv(128,256)
self.pool3 = nn.MaxPool2D(2)
self.conv4 = DoubleConv(256,512)
self.pool4 = nn.MaxPool2D(2)
self.conv5 = DoubleConv(512,1024)
#逆卷积
self.up6 = nn.Conv2DTranspose(1024,512,2,stride=2)
self.conv6 = DoubleConv(1024,512)
self.up7 = nn.Conv2DTranspose(512,256,2,stride=2)
self.conv7 = DoubleConv(512,256)
self.up8 = nn.Conv2DTranspose(256,128,2,stride=2)
self.conv8 = DoubleConv(256,128)
self.up9 = nn.Conv2DTranspose(128,64,2,stride=2)
self.conv9 = DoubleConv(128,64)
self.conv10 = nn.Conv2D(64,num_classes,1)
self.conv11 = nn.Conv2D(in_channels=num_classes,out_channels=num_classes,kernel_size=(1,512),stride=1)
def forward(self,x):
c1 = self.conv1(x)
p1 = self.pool1(c1)
c2 = self.conv2(p1)
p2 = self.pool2(c2)
c3 = self.conv3(p2)
p3 = self.pool3(c3)
c4 = self.conv4(p3)
p4 = self.pool4(c4)
c5 = self.conv5(p4)
up_6 = self.up6(c5)
merge6 = paddle.concat([up_6,c4],axis=1)#按维数1(列)拼接,列增加
c6 = self.conv6(merge6)
up_7 = self.up7(c6)
merge7 = paddle.concat([up_7,c3],axis=1)
c7 = self.conv7(merge7)
up_8 = self.up8(c7)
merge8 = paddle.concat([up_8,c2],axis=1)
c8 = self.conv8(merge8)
up_9 = self.up9(c8)
merge9 = paddle.concat([up_9,c1],axis=1)
c9 = self.conv9(merge9)
c10 = self.conv10(c9)
#c11 = F.sigmoid(self.conv11(c10))#化成(0~1)区间
return c10
if __name__ == '__main__':
unet = UNet(num_classes=1)
model = paddle.Model(unet)
model.summary((2,3, 512, 512))
W1005 14:08:51.387312 575 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1005 14:08:51.391311 575 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
-----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=============================================================================
Conv2D-1 [[2, 3, 512, 512]] [2, 64, 512, 512] 1,792
BatchNorm2D-1 [[2, 64, 512, 512]] [2, 64, 512, 512] 256
ReLU-1 [[2, 64, 512, 512]] [2, 64, 512, 512] 0
Conv2D-2 [[2, 64, 512, 512]] [2, 64, 512, 512] 36,928
BatchNorm2D-2 [[2, 64, 512, 512]] [2, 64, 512, 512] 256
ReLU-2 [[2, 64, 512, 512]] [2, 64, 512, 512] 0
DoubleConv-1 [[2, 3, 512, 512]] [2, 64, 512, 512] 0
MaxPool2D-1 [[2, 64, 512, 512]] [2, 64, 256, 256] 0
Conv2D-3 [[2, 64, 256, 256]] [2, 128, 256, 256] 73,856
BatchNorm2D-3 [[2, 128, 256, 256]] [2, 128, 256, 256] 512
ReLU-3 [[2, 128, 256, 256]] [2, 128, 256, 256] 0
Conv2D-4 [[2, 128, 256, 256]] [2, 128, 256, 256] 147,584
BatchNorm2D-4 [[2, 128, 256, 256]] [2, 128, 256, 256] 512
ReLU-4 [[2, 128, 256, 256]] [2, 128, 256, 256] 0
DoubleConv-2 [[2, 64, 256, 256]] [2, 128, 256, 256] 0
MaxPool2D-2 [[2, 128, 256, 256]] [2, 128, 128, 128] 0
Conv2D-5 [[2, 128, 128, 128]] [2, 256, 128, 128] 295,168
BatchNorm2D-5 [[2, 256, 128, 128]] [2, 256, 128, 128] 1,024
ReLU-5 [[2, 256, 128, 128]] [2, 256, 128, 128] 0
Conv2D-6 [[2, 256, 128, 128]] [2, 256, 128, 128] 590,080
BatchNorm2D-6 [[2, 256, 128, 128]] [2, 256, 128, 128] 1,024
ReLU-6 [[2, 256, 128, 128]] [2, 256, 128, 128] 0
DoubleConv-3 [[2, 128, 128, 128]] [2, 256, 128, 128] 0
MaxPool2D-3 [[2, 256, 128, 128]] [2, 256, 64, 64] 0
Conv2D-7 [[2, 256, 64, 64]] [2, 512, 64, 64] 1,180,160
BatchNorm2D-7 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,048
ReLU-7 [[2, 512, 64, 64]] [2, 512, 64, 64] 0
Conv2D-8 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,359,808
BatchNorm2D-8 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,048
ReLU-8 [[2, 512, 64, 64]] [2, 512, 64, 64] 0
DoubleConv-4 [[2, 256, 64, 64]] [2, 512, 64, 64] 0
MaxPool2D-4 [[2, 512, 64, 64]] [2, 512, 32, 32] 0
Conv2D-9 [[2, 512, 32, 32]] [2, 1024, 32, 32] 4,719,616
BatchNorm2D-9 [[2, 1024, 32, 32]] [2, 1024, 32, 32] 4,096
ReLU-9 [[2, 1024, 32, 32]] [2, 1024, 32, 32] 0
Conv2D-10 [[2, 1024, 32, 32]] [2, 1024, 32, 32] 9,438,208
BatchNorm2D-10 [[2, 1024, 32, 32]] [2, 1024, 32, 32] 4,096
ReLU-10 [[2, 1024, 32, 32]] [2, 1024, 32, 32] 0
DoubleConv-5 [[2, 512, 32, 32]] [2, 1024, 32, 32] 0
Conv2DTranspose-1 [[2, 1024, 32, 32]] [2, 512, 64, 64] 2,097,664
Conv2D-11 [[2, 1024, 64, 64]] [2, 512, 64, 64] 4,719,104
BatchNorm2D-11 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,048
ReLU-11 [[2, 512, 64, 64]] [2, 512, 64, 64] 0
Conv2D-12 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,359,808
BatchNorm2D-12 [[2, 512, 64, 64]] [2, 512, 64, 64] 2,048
ReLU-12 [[2, 512, 64, 64]] [2, 512, 64, 64] 0
DoubleConv-6 [[2, 1024, 64, 64]] [2, 512, 64, 64] 0
Conv2DTranspose-2 [[2, 512, 64, 64]] [2, 256, 128, 128] 524,544
Conv2D-13 [[2, 512, 128, 128]] [2, 256, 128, 128] 1,179,904
BatchNorm2D-13 [[2, 256, 128, 128]] [2, 256, 128, 128] 1,024
ReLU-13 [[2, 256, 128, 128]] [2, 256, 128, 128] 0
Conv2D-14 [[2, 256, 128, 128]] [2, 256, 128, 128] 590,080
BatchNorm2D-14 [[2, 256, 128, 128]] [2, 256, 128, 128] 1,024
ReLU-14 [[2, 256, 128, 128]] [2, 256, 128, 128] 0
DoubleConv-7 [[2, 512, 128, 128]] [2, 256, 128, 128] 0
Conv2DTranspose-3 [[2, 256, 128, 128]] [2, 128, 256, 256] 131,200
Conv2D-15 [[2, 256, 256, 256]] [2, 128, 256, 256] 295,040
BatchNorm2D-15 [[2, 128, 256, 256]] [2, 128, 256, 256] 512
ReLU-15 [[2, 128, 256, 256]] [2, 128, 256, 256] 0
Conv2D-16 [[2, 128, 256, 256]] [2, 128, 256, 256] 147,584
BatchNorm2D-16 [[2, 128, 256, 256]] [2, 128, 256, 256] 512
ReLU-16 [[2, 128, 256, 256]] [2, 128, 256, 256] 0
DoubleConv-8 [[2, 256, 256, 256]] [2, 128, 256, 256] 0
Conv2DTranspose-4 [[2, 128, 256, 256]] [2, 64, 512, 512] 32,832
Conv2D-17 [[2, 128, 512, 512]] [2, 64, 512, 512] 73,792
BatchNorm2D-17 [[2, 64, 512, 512]] [2, 64, 512, 512] 256
ReLU-17 [[2, 64, 512, 512]] [2, 64, 512, 512] 0
Conv2D-18 [[2, 64, 512, 512]] [2, 64, 512, 512] 36,928
BatchNorm2D-18 [[2, 64, 512, 512]] [2, 64, 512, 512] 256
ReLU-18 [[2, 64, 512, 512]] [2, 64, 512, 512] 0
DoubleConv-9 [[2, 128, 512, 512]] [2, 64, 512, 512] 0
Conv2D-19 [[2, 64, 512, 512]] [2, 1, 512, 512] 65
=============================================================================
Total params: 31,055,297
Trainable params: 31,031,745
Non-trainable params: 23,552
-----------------------------------------------------------------------------
Input size (MB): 6.00
Forward/backward pass size (MB): 7436.00
Params size (MB): 118.47
Estimated Total Size (MB): 7560.47
-----------------------------------------------------------------------------
3.4 模型训练
# 初始化权重
import paddle
import paddle.nn as nn
from paddle.nn.initializer import KaimingNormal,Constant
def weight_init(module):
for n,m in module.named_children():
if isinstance(m,nn.Conv2D):
KaimingNormal()(m.weight,m.weight.block)
if m.bias is not None:
Constant(0)(m.bias)
if isinstance(m,nn.Conv1D):
KaimingNormal()(m.weight,m.weight.block)
if m.bias is not None:
Constant(0)(m.bias)
import pandas as pd
import os
import numpy as np
from tqdm import tqdm
# 创建文件夹
for item in ['log','saveModel']:
make_folder = os.path.join('work',item)
if not os.path.exists(make_folder):
os.mkdir(make_folder)
EPOCH_NUM = 30 # 设置外层循环次数
BATCH_SIZE = 8 # 设置batch大小
# 定义网络结构
# 五折交叉验证
#for K in range(5):
K=5 #K+1
# unet3p / unet / u2net / attunet / unet2p
# 每次实例化模型
model = UNet(num_classes=1)
model_name = 'unet'
for item in ['log','saveModel']:
make_folder = os.path.join('work',item,model_name)
if not os.path.exists(make_folder):
os.mkdir(make_folder)
# 定义优化算法,使用随机梯度下降SGD,学习率设置为0.01
scheduler = paddle.optimizer.lr.StepDecay(learning_rate=0.01, step_size=30, gamma=0.1, verbose=False)
optimizer = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
# 定义数据读取
train_dataset = MRILocationDataset(images_frontal, images_sagittal, slice_locations,mode='train',k_fold=K)
# 使用paddle.io.DataLoader 定义DataLoader对象用于加载Python生成器产生的数据,
data_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=False,num_workers=4)
loss_BCEloss = paddle.nn.BCELoss()
result = pd.DataFrame()
model.train()
model.apply(weight_init)
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 定义内层循环
LOSS = {}
for iter_id, data in enumerate(tqdm(data_loader())):
images_frontal_ ,images_sagittal_,slice_locations_,label = data # x 为数据 ,y 为标签
# 将numpy数据转为飞桨动态图tensor形式
x = paddle.to_tensor(images_frontal_,dtype='float32')
y = paddle.to_tensor(images_sagittal_,dtype='float32')
label = paddle.to_tensor(label,dtype='float32')
# 前向计算
predicts = model(y)
# 计算损失
loss = loss_BCEloss(paddle.nn.functional.sigmoid(predicts), label)
# 清除梯度
optimizer.clear_grad()
# 反向传播
loss.backward()
# 最小化loss,更新参数
optimizer.step()
LOSS[iter_id] = loss.item()
scheduler.step()
info_loss = {'Epoch':epoch_id+1,'Loss':np.around(sum(LOSS.values())/len(LOSS), 5)}
result = result.append(info_loss,ignore_index=True)
print("第{}/5次交叉验证,epoch: {}, loss is: {}".format(K,epoch_id+1, loss.item()))
# 保存模型参数,文件名为 模型.pdparams
paddle.save(model.state_dict(), os.path.join('work/saveModel',model_name,model_name + '_{}.pdparams'.format(K)))
result.to_csv( os.path.join('work/log',model_name,model_name + '_{}.csv'.format(K)),index=False)
print('模型保存成功,模型参数保存在:',model_name,'_{}.pdparams中'.format(K))
3.5 模型测试
import paddle
import pandas as pd
import os
# 模型验证
BATCH_SIZE = 8
# 单次验证记录
Error_mean,Error_std= [],[]
# 全局验证记录
MODEL_Mean,MODEL_Std = [],[]
# 清理缓存
print("开始测试")
result = pd.DataFrame()
#for K in range(5):
K=5 #K+1
# 定义模型
model_name = 'unet'
model = UNet(num_classes=1)
# 用于加载之前的训练过的模型参数
para_state_dict = paddle.load(os.path.join('work/saveModel',model_name,model_name + '_{}.pdparams'.format(K)))
model.set_dict(para_state_dict)
model.eval()
test_dataset = MRILocationDataset(images_frontal, images_sagittal, slice_locations,mode='test',k_fold=K)
test_data_loader = paddle.io.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False,num_workers=4)
with paddle.no_grad():
for iter_id, data in enumerate(test_data_loader()):
x, y,loc,label_ = data # x 为数据 ,y 为标签
# 将numpy数据转为飞桨动态图tensor形式
x = paddle.to_tensor(x,dtype='float32')
y = paddle.to_tensor(y,dtype='float32')
label_ = paddle.to_tensor(label_,dtype='float32')
predicts = model(y)
predicts = paddle.nn.functional.sigmoid(predicts)
for i in range(predicts.shape[0]):
predict = predicts[i,:,:,:].cpu().numpy()
label = label_[i,:,:,:].cpu().numpy()
inputs = y[i,1,:,:].cpu().numpy()
predict = np.squeeze(predict)
label = np.squeeze(label)
inputs = np.squeeze(inputs)
#当要保存的图片为灰度图像时,灰度图像的 numpy 尺度是 [1, h, w]。需要将 [1, h, w] 改变为 [h, w]
plt.figure(figsize=(6, 18))
plt.subplot(1,3,1),plt.xticks([]),plt.yticks([]),plt.imshow(predict,cmap='gray')
plt.subplot(1,3,2),plt.xticks([]),plt.yticks([]),plt.imshow(label,cmap='gray')
plt.subplot(1,3,3),plt.xticks([]),plt.yticks([]),plt.imshow(inputs,cmap='gray')
plt.show()
index_predict= np.argmax(np.max(predict,1))+3
index_label = np.argmax(np.max(label,1))
print('真实位置:',index_label,'预测位置:',index_predict)
Error_mean.append(np.abs(index_label-index_predict))
Error_std.append(index_label-index_predict)
break
print("第{}个模型测试集平均定位误差为:{:.2f},定位误差标准差为:{:.2f}".format(K,np.mean(Error_mean),np.std(Error_std)))
MODEL_Mean.append(np.mean(Error_mean))
MODEL_Std.append(np.std(Error_std))
info_loss = {'K折交叉验证':K,'定位误差均值':np.mean(Error_mean),'定位误差标准差':np.std(Error_std)}
result = result.append(info_loss,ignore_index=True)
# 加入K折的最终验证结果
info_loss = {'K折交叉验证':'ALL','定位误差均值':np.mean(MODEL_Mean),'定位误差标准差':np.mean(MODEL_Std)}
result = result.append(info_loss,ignore_index=True)
result.to_csv( os.path.join('work/log',model_name,model_name + '_all.csv'),index=False,encoding='utf-8-sig')
print('-----------------------------------------')
print('模型{}五折交叉验证平均误差为:{:.2f},误差标准差为:{:.2f}'.format(model_name,np.mean(MODEL_Mean),np.mean(MODEL_Std)))
print('-----------------------------------------')
np.mean(MODEL_Mean),'定位误差标准差':np.mean(MODEL_Std)}
result = result.append(info_loss,ignore_index=True)
result.to_csv( os.path.join('work/log',model_name,model_name + '_all.csv'),index=False,encoding='utf-8-sig')
print('-----------------------------------------')
print('模型{}五折交叉验证平均误差为:{:.2f},误差标准差为:{:.2f}'.format(model_name,np.mean(MODEL_Mean),np.mean(MODEL_Std)))
print('-----------------------------------------')
开始测试
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_min = np.asscalar(a_min.astype(scaled_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_max = np.asscalar(a_max.astype(scaled_dtype))

真实位置: 182 预测位置: 189

真实位置: 222 预测位置: 233

真实位置: 134 预测位置: 141

真实位置: 347 预测位置: 353

真实位置: 369 预测位置: 346

真实位置: 202 预测位置: 207

真实位置: 214 预测位置: 217
真实位置: 337 预测位置: 343
第5个模型测试集平均定位误差为:8.50,定位误差标准差为:9.96
-----------------------------------------
模型unet五折交叉验证平均误差为:8.50,误差标准差为:9.96
-----------------------------------------

4 项目总结
| L3锥体定位 | 正面视图 | 侧面视图 |
|---|---|---|
| 误差 mm | 41 | 25 |
| 标准差 mm | 120 | 67 |
结论:侧面视图的定位精度要优于正面视图
-
本项目基于Unet算法实现了锥体的自动定位,更加深入的探讨了模型应用场景。
-
该项目启发对深度学习对于影像特征不明显的任务(不同于肿瘤的影像学特征明显,锥体定位要人工数),深度学习也能起到效果。
-
本项目对比了CT数据正面视图及侧面视图的定位精度,其中预处理是自动定位不可忽略的操作。
-
本项探索了开源数据数据正面视图及侧面视图的定位实验,后续可以在该模型中进一步改进。
此文章为搬运
原项目链接