【机器学习基础】数学推导+纯Python实现机器学习算法24:HMM隐马尔可夫模型
Python机器学习算法实现
Author:louwill
Machine Learning Lab
HMM(Hidden Markov Model)也就是隐马尔可夫模型,是一种由隐藏的马尔可夫链随机生成观测序列的过程,是另一种经典的概率图模型。本文在阐述HMM的基本定义和相关概念的基础上,引申出HMM的三个重要问题:估计算法、学习算法和预测算法问题,并给出相应的代码实现方式。
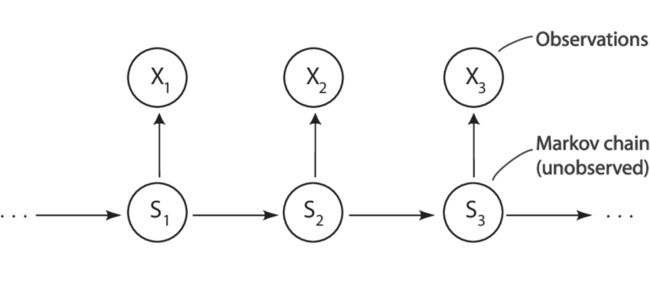
HMM的定义与相关概念
HMM是关于时序的概率模型,描述一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生随机序列的过程。其中隐藏的马尔可夫链随机生成的状态的序列称之为状态序列,每个状态产生的状态构成的序列,称之为观测序列。
HMM由初始状态概率向量 ,状态转移概率矩阵 和观测概率矩阵 决定,其中 和 决定状态序列, 决定观测序列。所以,HMM可以用一个三元符号来表示:
设 为所有可能的状态的集合, 是所有可能的观测的集合:
,
其中 是可能的状态数, 是可能的观测数。
是长度为 的状态序列, 是对应的观测序列。
,
作为状态转移矩阵,可表达为:
其中: , 是在时刻 处于状态 的条件下在时刻 转移到状态 的概率。
作为观测概率矩阵,可表达为:
其中: , 是在时刻 处于状态 条件下生成的观测 的概率。
文字和公式表述可能过于抽象,我们以一个具体的例子来看一下HMM。假设有4个盒子,每个盒子里面都要红白两种颜色的球,各个盒子里面的红白球颜色数量分布如下表所示。
摸球规则如下:首先从4个盒子里等概率的选择一个1个盒子,从这个盒子里随机摸一个球,记录颜色后放回。然后从当前盒子随机地转移到下一个盒子,转移规则如下:如果当前盒子为1,那么下一个盒子一定是2,如果当前盒子是2或者3,则分别以概率0.4和0.6转移到左边或者右边的盒子,如果当前的盒子是4,那么各以0.5的概率停留在4或者转移到3,确定了转移的盒子后,就从该盒子中随机摸取一个球记录其颜色并放回。将上述摸球试验独立重复进行5次,得到一个球的观测序列为:
红,红,白,白,红
我们按照HMM的三要素对该例子进行分析。在上述摸球过程中,我们只能观测到摸到的球的颜色,即可以观测到球的颜色序列;而观察不到球是从哪个盒子摸到的,即观测不到盒子的序列。所以,该例中状态序列即为盒子的序列,观测序列即为摸取到的球的颜色序列。具体如下所示。
状态序列: 盒子 ,盒子 ,盒子 ,盒子 ,
观测序列: 红,白 , ,状态序列和观测序列长度 ,初始概率分布 ,状态转移概率分布矩阵为:
观测概率矩阵为:
综上,我们可以归纳一个长度为 的观测序列 的生成过程如下:
按照初始状态分布 产生状态
令
按照状态 的观测概率分布 生成
按照状态 的状态转移概率分布 产生状态 ,
令 ;如果 ,跳转到第三步否则过程终止。
根据该例我们可编写一个HMM观测序列生成过程的代码如下。
HMM的三个基本问题
跟CRF一样,HMM也有三个基本问题,分别是概率估计、学习问题和预测问题。
HMM的估计算法
HMM的概率估计问题,即在给定模型 和观测序列 ,计算在模型 下观测序列 出现的概率 。
跟CRF一样,HMM的概率估计方法依然是前向-后向算法。先来看前向算法。HMM定义前向概率如下:给定HMM模型 ,定义到时刻 部分观测序列 且状态为 的概率为前向概率,记为:
可以看到前向概率是一个联合概率。通过该定义可以递推的计算前向概率 及观测序列概率 。在输入为HMM模型 ,观测序列 和输出为观测序列概率 的情形下,观测序列概率的前向算法表述如下:
初值: ,
递推:对 ,有,
终止:
下面给出前向概率算法的具体推导过程。根据前向概率的定义,可以推导初值为:
其中 表示有状态 生成的观测概率,假设在 时刻观测数据 ,则有:
且由前向概率定义可得:
根据上式,遍历 的取值求和,可得 的边际概率:
令 ,有:
上式推导中根据观测独立假设第一项可化简为:
第二项可根据齐次马尔可夫假设化简为:
假设已知 ,在前向概率的定义的基础上,有:
将前述化简结果带上上式,可得:
后向概率算法同理可推导。基于前向-后向概率我们可计算HMM的一些延申概率和期望,这里略过。
HMM的学习算法
HMM的第二个关键问题就是学习问题。即已知观测序列 ,估计HMM模型 的参数,使得在该模型下观测序列概率$P(O|\lambda)最大。
当训练数据集同时包含观测序列和对应的状态序列时,我们可以直接使用极大似然估计来估计HMM的模型参数。但大多数情况下,训练数据仅有观测序列而未给出对应的状态序列,这时我们将观测序列看作观测数据 ,状态序列看作不可观测的隐数据 ,此时的HMM模型实际上一个含有隐变量的概率模型:
由第22讲我们知道含有隐变量的概率模型可以通过EM算法来进行迭代求解。应用EM算法求解HMM模型参数也叫Baum-Welch算法。基于Baum-Welch算法求解HMM模型参数过程如下:
确定完全数据的对数似然函数
将观测数据写为 ,隐数据写为 ,完全数据可以写为。完全数据的对数似然函数为 。EM算法的E步:求 函数
其中 为HMM参数的当前估计值, 是要极大化的HMM参数。EM算法的M步:极大化 函数 求模型参数 。
HMM的预测算法
HMM的预测问题也就是解码问题。即再已知模型 和观测序列 的情况下,求对给定观测序列条件概率P(I|O)最大的状态序列 。即给定观测序列,求最有可能的对应的状态序列。
跟CRF预测算法一样,HMM的预测算法同样是一个求解最优路径问题,所以解码算法仍然是上一篇文章说到的维特比算法。关于维特比算法的通俗解释,参考上一篇CRF的讲解。基于维特比算法的HMM最优路径求解过程如下。
初始化: , ,
递推。对 :
,终止:
最优路径回溯。对 :
HMM的代码实现
完整的HMM需要实现的内容比较多。这里我们仅给出基于盒子摸球模型的HMM观测序列生成过程和维特比解码过程的参考实现方式。完整的算法笔者后续会在GitHub上给出。
基于4个盒子摸球的HMM模型的观测序列生成过程如下:
import numpy as np
# 根据给定的概率分布随机返回数据
def get_data_with_distribution(dist):
r = np.random.rand()
for i, p in enumerate(dist):
if r < p:
return i
r -= p
def generate(T):
'''
根据给定的参数生成观测序列
T: 指定要生成数据的数量
'''
# 根据初始概率分布生成第一个状态
z = get_data_with_distribution(pi)
# 生成第一个观测数据
x = get_data_with_distribution(B[z])
result = [x]
# 遍历生成余下的状态和观测数据
for _ in range(T-1):
z = get_data_with_distribution(A[z])
x = get_data_with_distribution(B[z])
result.append(x)
return result
### 盒子和球相关的模型参数
# 初始状态概率向量
pi = np.array([0.25, 0.25, 0.25, 0.25])
# 状态转移概率矩阵
A = np.array([
[0, 1, 0, 0],
[.4, 0, .6, 0],
[0, .4, 0, .6],
[0, 0, .5, .5]])
# 观测概率矩阵
B = np.array([
[0.5, 0.5],
[0.3, 0.7],
[0.6, 0.4],
[0.8, 0.2]])
# 生成10个数据
generate(10)
[0, 0, 0, 0, 0, 0, 1, 1, 0, 0]
在已知模型参数和观测序列的情况下,基于维特比算法的解码反推最有可能的隐状态序列:
def viterbi_decode(X):
T, x = len(X), X[0]
# 初始化
delta = pi * B[:,x]
varphi = np.zeros((T, N), dtype=int)
path = [0] * T
# 递推
for i in range(1, T):
delta = delta.reshape(-1,1)
tmp = delta * A
varphi[i,:] = np.argmax(tmp, axis=0)
delta = np.max(tmp, axis=0) * B[:,X[i]]
# 终止
path[-1] = np.argmax(delta)
# 最优路径回溯
for i in range(T-1,0,-1):
path[i-1] = varphi[i,path[i]]
return path
X = [1,0,1,0,0]
N = 4
print(viterbi_decode(X))
[1, 0, 1, 2, 3]
参考资料:
李航 统计学习方法 第二版
https://zhuanlan.zhihu.com/p/85454896
往期精彩:
数学推导+纯Python实现机器学习算法28:CRF条件随机场
数学推导+纯Python实现机器学习算法27:EM算法
数学推导+纯Python实现机器学习算法26:随机森林
数学推导+纯Python实现机器学习算法25:CatBoost
数学推导+纯Python实现机器学习算法24:LightGBM
数学推导+纯Python实现机器学习算法23:kmeans聚类
数学推导+纯Python实现机器学习算法22:最大熵模型
数学推导+纯Python实现机器学习算法21:马尔科夫链蒙特卡洛
数学推导+纯Python实现机器学习算法20:LDA线性判别分析
数学推导+纯Python实现机器学习算法19:PCA降维
数学推导+纯Python实现机器学习算法18:奇异值分解SVD
数学推导+纯Python实现机器学习算法17:XGBoost
数学推导+纯Python实现机器学习算法16:Adaboost
数学推导+纯Python实现机器学习算法15:GBDT
数学推导+纯Python实现机器学习算法14:Ridge岭回归
数学推导+纯Python实现机器学习算法13:Lasso回归
数学推导+纯Python实现机器学习算法12:贝叶斯网络
数学推导+纯Python实现机器学习算法11:朴素贝叶斯
数学推导+纯Python实现机器学习算法10:线性不可分支持向量机
数学推导+纯Python实现机器学习算法8-9:线性可分支持向量机和线性支持向量机
数学推导+纯Python实现机器学习算法7:神经网络
数学推导+纯Python实现机器学习算法6:感知机
数学推导+纯Python实现机器学习算法5:决策树之CART算法
数学推导+纯Python实现机器学习算法4:决策树之ID3算法
数学推导+纯Python实现机器学习算法3:k近邻
数学推导+纯Python实现机器学习算法2:逻辑回归
数学推导+纯Python实现机器学习算法1:线性回归

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085。加入微信群请扫码进群: