“万物皆可Seq2Seq” | 忠于原文的T5手写论文翻译
《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
摘要 / Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being finetuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled data sets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our data set, pre-trained models, and code.1 Keywords: transfer learning, natural language processing, multi-task learning, attentionbased models, deep learning
迁移学习,把一个模型先在数据丰富的任务上进行预训练,然后再针对下游任务进行微调,这在自然语言处理中是一个强大的技术。迁移学习的有效性引起了方法、方式和实现的多样性。在本文中,我们探索了NLP的迁移学习技术的前景,通过引入一个统一框架将所有基于文本的语言问题转换为文本到文本格式。我们系统的比较了数十种语言理解任务的预训练目标,体系结构,未标记的数据集,迁移方法和其他因素。通过结合对规模的探索和新的“巨型清洁爬虫语料库(C4)”,我们在许多基准上获得了最先进的结果,包括文本摘要,问题解答,文本分类等。为了促进NLP迁移学习的发展,我们发布了数据集,预训练的模型和代码。
章节1 介绍 / Introduction
Training a machine learning model to perform natural language processing (NLP) tasks often requires that the model can process text in a way that is amenable to downstream learning. This can be loosely viewed as developing general-purpose knowledge that allows the model to “understand” text. This knowledge can range from low-level (e.g. the spelling or meaning of words) to high-level (e.g. that a tuba is too large to fit in most backpacks). In modern machine learning practice, providing this knowledge is rarely done explicitly; instead, it is often learned as part of an auxiliary task. For example, a historically common approach is to use word vectors (Mikolov et al., 2013b,a; Pennington et al., 2014) to map word identities to a continuous representation where, ideally, similar words map to similar vectors. These vectors are often learned through an objective that, for example, encourages co-occurring words to be positioned nearby in the continuous space (Mikolov et al., 2013b).
训练一个自然语言处理领域任务的机器学习模型经常需要这个模型能够处理文本数据以适应下游学习。可以将其大致看做让其学习通用的知识,使模型可以“理解”文本。这些知识的范围可能从低级(例如单词的拼写或含义)到高级(例如大号(低音铜管乐器)太大而无法容纳大多数背包)。在现代机器学习实践中,很少明确地提供这种知识;相反的,通常将其作为辅助任务的一部分来学习。例如,一种历史上常见的方法是使用词向量(Mikolov et al., 2013b,a; Pennington et al., 2014)将单词编码映射为连续表示,理想情况下,相似的单词映射到相似的向量。这些词向量通常是通过一个目标来学习的,例如,它鼓励将同时出现的单词放在连续空间的附近(对于word2vec来说在文本距离更近的单词映射的词向量拥有更近的空间距离)(Mikolov et al., 2013b).
Recently, it has become increasingly common to pre-train the entire model on a data-rich task. Ideally, this pre-training causes the model to develop general-purpose abilities and knowledge that can then be transferred to downstream tasks. In applications of transfer learning to computer vision (Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014), pre-training is typically done via supervised learning on a large labeled data set like ImageNet (Russakovsky et al., 2015; Deng et al., 2009). In contrast, modern techniques for transfer learning in NLP often pre-train using unsupervised learning on unlabeled data. This approach has recently been used to obtain state-of-the-art results in many of the most common NLP benchmarks (Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019; Liu et al., 2019c; Lan et al., 2019). Beyond its empirical strength, unsupervised pre-training for NLP is particularly attractive because unlabeled text data is available en masse thanks to the Internet—for example, the Common Crawl project2 produces about 20TB of text data extracted from web pages each month. This is a natural fit for neural networks, which have been shown to exhibit remarkable scalability, i.e. it is often possible to achieve better performance simply by training a larger model on a larger data set (Hestness et al., 2017; Shazeer et al., 2017; Jozefowicz et al., 2016; Mahajan et al., 2018; Radford et al., 2019; Shazeer et al., 2018; Huang et al., 2018b; Keskar et al., 2019a).
最近,在数据丰富的任务上对整个模型进行预训练变得越来越普遍。在理想情况下,这种预训练可使模型发展出通用的能力和知识,然后将其迁移到下游任务中。在将迁移学习应用于计算机视觉的过程中(Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014),预训练通常是在大型计算机上进行有监督学习来完成的。 比如已经标记的数据集ImageNet(Russakovsky et al., 2015; Deng et al., 2009)。相反,现在用于NLP中的迁移学习技术通常在未标记的数据上使用无监督学习进行预训练。在许多最常见的NLP基准测试中,近期用这种方法获得了最顶的结果(Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019; Liu et al., 2019c; Lan et al., 2019)。除了其经验优势之外,对无监督预训练的NLP尤其具有吸引力,因为借助互联网,可以获得无标签文本数据,例如,Common Crawl project2每月会从网页提取大约20TB的文本数据。这自然适用于神经网络,神经网络已显示出卓越的可扩展性,即通常只需在较大的数据集上训练较大的模型,通常就有可能获得更顶的性能(Hestness et al., 2017; Shazeer et al., 2017; Jozefowicz et al., 2016; Mahajan et al., 2018; Radford et al., 2019; Shazeer et al., 2018; Huang et al., 2018b; Keskar et al., 2019a).
This synergy has resulted in a great deal of recent work developing transfer learning methodology for NLP, which has produced a wide landscape of pre-training objectives (Howard and Ruder, 2018; Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019), unlabeled data sets (Yang et al., 2019; Liu et al., 2019c; Zellers et al., 2019), benchmarks (Wang et al., 2019b, 2018; Conneau and Kiela, 2018), fine-tuning methods (Howard and Ruder, 2018; Houlsby et al., 2019; Peters et al., 2019), and more. The rapid rate of progress and diversity of techniques in this burgeoning field can make it difficult to compare different algorithms, tease apart the effects of new contributions, and understand the space of existing methods for transfer learning. Motivated by a need for more rigorous understanding, we leverage a unified approach to transfer learning that allows us to systematically study different approaches and push the current limits of the field.
这种1+1>2的作用导致最近对NLP的迁移学习有了大量的工作进展,这产生了广泛的预训练目标(Howard and Ruder, 2018; Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019),未标记的数据集(Yang et al., 2019; Liu et al., 2019c; Zellers et al., 2019),基准(Wang et al., 2019b, 2018; Conneau and Kiela, 2018),微调方法(Howard and Ruder, 2018; Houlsby et al., 2019; Peters et al., 2019)等。在这个迅速发展的领域中,快速的进步和技术的多样性可能使得很难比较不同的算法,难以梳理出新研究的效果,并难以理解现有的迁移学习方法的情况。由于需要更严谨的理解,我们利用统一的方法来迁移学习,使我们能够系统地研究不同的方法,并推动该领域的当前发展。
The basic idea underlying our work is to treat every text processing problem as a “text-to-text” problem, i.e. taking text as input and producing new text as output. This approach is inspired by previous unifying frameworks for NLP tasks, including casting all text problems as question answering (McCann et al., 2018), language modeling (Radford et al., 2019), or span extraction Keskar et al. (2019b) tasks. Crucially, the text-to-text framework allows us to directly apply the same model, objective, training procedure, and decoding process to every task we consider. We leverage this flexibility by evaluating performance on a wide variety of English-based NLP problems, including question answering, document summarization, and sentiment classification, to name a few. With this unified approach, we can compare the effectiveness of different transfer learning objectives, unlabeled data sets, and other factors, while exploring the limits of transfer learning for NLP by scaling up models and data sets beyond what has previously been considered.
我们工作的基本思想是将每个文本处理问题都视为“文本到文本”问题,即以文本作为输入并产生一个新的文本作为输出(万物皆可Seq2Seq)。这种方法受到以前用于NLP任务的统一框架的启发,包括将所有文本问题都转换为问答问题(McCann et al., 2018),语言建模(Radford et al., 2019)或跨度提取Keskar等任务。重要的是,文本到文本框架允许我们可以将相同的模型,目标,训练过程和解码过程直接应用于我们所考虑的每个任务。我们通过各种基于英语的NLP问题来评估这种性能,其中包括问答,文档摘要和情感分类等。使用这种统一的方法,我们可以比较不同的迁移学习目标,未标记的数据集和其他因素的有效性,同时通过扩大模型和数据集的范围以超越先前考虑的范围,探索NLP迁移学习的局限性。
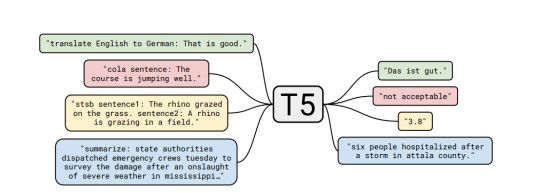
Figure 1: A diagram of our text-to-text framework. Every task we consider—including translation, question answering, and classification—is cast as feeding our model text as input and training it to generate some target text. This allows us to use the same model, loss function, hyperparameters, etc. across our diverse set of tasks. It also provides a standard testbed for the methods included in our empirical survey. “T5” refers to our model, which we dub the “Text-to-Text Transfer Transformer”.
图1:我们的文本到文本框架图。我们考虑的每个任务(包括翻译,问题解答和分类)都将文本作为输入喂入我们的模型,并对其进行训练来生成一些目标文本。这使我们可以在各种任务中使用相同的模型,损失函数,超参数等。它还为我们调研中的方法提供了标准的测试方法。“Text-to-Text Transfer Transformer”是指我们的模型,我们将其称为“T5”。
We emphasize that our goal is not to propose new methods but instead to provide a comprehensive perspective on where the field stands. As such, our work primarily comprises a survey, exploration, and empirical comparison of existing techniques. We also explore the limits of current approaches by scaling up the insights from our systematic study (training models up to 11 billion parameters) to obtain state-of-the-art results in many of the tasks we consider. In order to perform experiments at this scale, we introduce the “Colossal Clean Crawled Corpus” (C4), a data set consisting of hundreds of gigabytes of clean English text scraped from the web. Recognizing that the main utility of transfer learning is the possibility of leveraging pre-trained models in data-scarce settings, we release our code, data sets, and pre-trained models.
我们强调,我们的目标不是提出新方法,而是提供有关这个领域现状的全面观点。因此,我们的工作主要包括对现有技术的研究,探索和经验的比较。我们还将通过扩大我们的系统研究(训练模型多达110亿个参数)的见解来探索当前方法的局限性,从而在我们考虑的许多任务中获得最顶的结果。为了进行如此大规模的实验,我们引入了“巨型清洁爬虫语料库”(C4),该数据集是从网络上抓取的数百GB干净的英语文本组成。我们认识到迁移学习的主要作用是让人们可以在数据稀缺的环境中利用预训练的模型,因此我们发布了代码,数据集和预训练的模型。
The remainder of the paper is structured as follows: In the following section, we discuss our base model and its implementation, our procedure for formulating every text processing problem as a text-to-text task, and the suite of tasks we consider. In Section 3, we present a large set of experiments that explore the field of transfer learning for NLP. At the end of the section (Section 3.7), we combine insights from our systematic study to obtain state-of-the-art results on a wide variety of benchmarks. Finally, we provide a summary of our results and wrap up with a look towards the future in Section 4.
在本文的其余结构如下:在下面的部分中,我们讨论基本模型及其实现,将每个文本处理问题表达为文本到文本任务的过程以及我们考虑的一系列任务。在第3节中,我们提供了大量的实验,探索NLP的迁移学习领域。在本节的最后(第3.7节),我们结合了系统研究的理解,从而获得了各种基准上的最顶结果。最后,我们对结果进行了总结,并在第4节中总结了对未来的展望。