GradientBoosting_regression_model
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import preprocessing
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.linear_model import Lasso,Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
#忽视警告
import warnings
warnings.filterwarnings("ignore")
dataset = datasets.load_boston()
featurenames = list(dataset.feature_names)
X,y = dataset.data,dataset.target
scaler = preprocessing.StandardScaler()
x = scaler.fit_transform(X)
#特征提取
clf = Lasso(alpha=1.0)
clf.fit(x,y)
coefs = clf.coef_
scores = {}
for name,coef in zip(featurenames,coefs):
scores[name] = (round(coef,4))
print('Lasso Model:\n',scores)
clf = Ridge(alpha=1.0)
clf.fit(x,y)
coefs = clf.coef_
scores = {}
for name,coef in zip(featurenames,coefs):
scores[name] = (round(coef,4))
print('Ridge Model:\n',scores)
clf = RandomForestRegressor(n_estimators=10,criterion='mse')
clf.fit(x,y)
scores = {}
for name,coef in zip(featurenames,clf.feature_importances_):
scores[name] = (round(coef,4))
print('Tree Model:\n',scores)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=1)
#优化参数
params = {
'learning_rate':[0.0001,0.001,0.01,0.1],
'n_estimators':range(100,200)
}
model = GridSearchCV(GradientBoostingRegressor(loss='ls'),params)
model.fit(x_train,y_train)
print('最佳模型为:\n',model.best_estimator_)
print('最佳参数为:\n',model.best_params_)
'''
LR=0.1,n_estimators=170
'''
clf = GradientBoostingRegressor(loss='ls',learning_rate=0.1,n_estimators=170)
clf.fit(x_train,y_train)
predict_train = clf.predict(x_train)
predict_test = clf.predict(x_test)
train_mse = mean_squared_error(y_train,predict_train)
test_mse = mean_squared_error(y_test,predict_test)
print('Train MSE = ',train_mse,' Test MSE = ',test_mse)
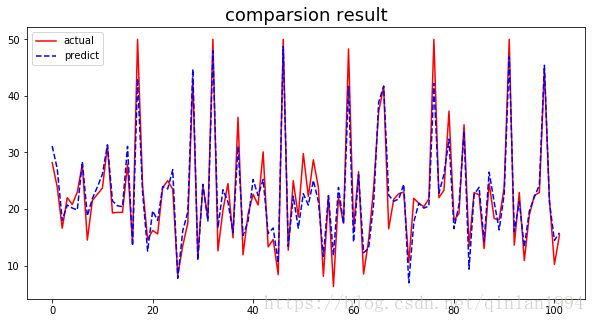
#结果可视化
fig,ax = plt.subplots(figsize=(10,5))
ax.plot(y_test,'-',color='red')
ax.plot(predict_test,'--',color='blue')
plt.legend(['actual','predict'],loc='best')
ax.set_title('comparsion result',color='black',fontsize=18)