Python常见bug
urllib.error.HTTPError: HTTP Error 418:
当爬虫遭到反爬机制的时候 会爆这个错误
一、场景
爬取豆瓣网站前十页数据
二、检查思路
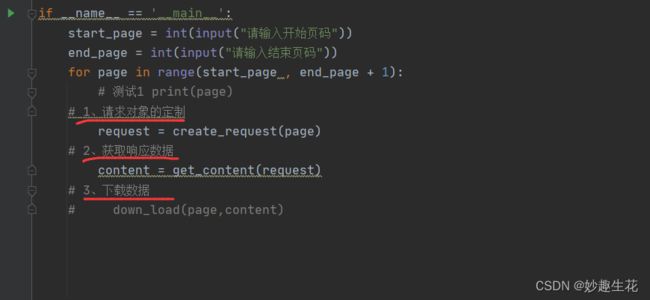
三个步骤中的方法 每写好一个方法 进行print 测试
三、解决
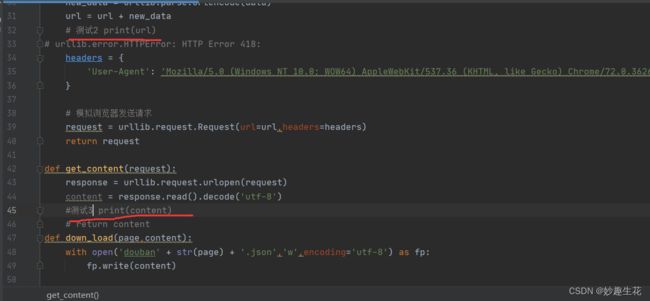
经过检查 这个请求头headers 中的UA 多了一个空格 奇奇怪怪 明明直接复制浏览器的......
四、场景案例
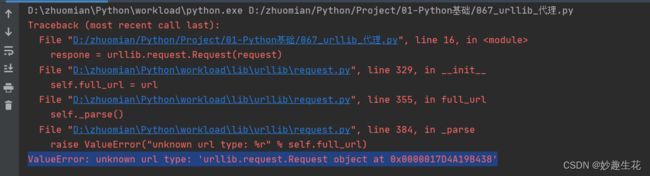
ValueError: unknown url type: 'urllib.request.Request object at 0x0000017D4A19B438'
将url的把http变为https
AttributeError: 'OpenerDirector' object has no attribute 'type'
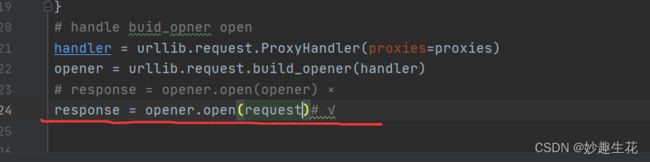
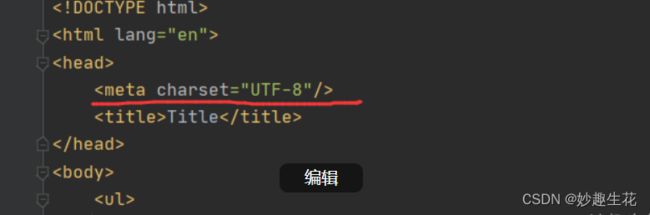
urllib.error.URLError: 遇到这种情况可以百度搜索快代理进行代理购买 不贵 新用户加上优惠券即可 lxml.etree.XMLSyntaxError: Opening and ending tag mismatch: meta line 4 and head, line 6, column 8